Top 15 Web Search MCPs to Connect Your AI To
Top 15 Web Search MCPs to Connect Your AI To

Charlie Klein

Top 15 Web Search MCPs to Connect Your AI To
Top 15 Web Search MCPs to Connect Your AI To
Charlie Klein
Most popular articles

Get structured, reliable data for your stack.
Top 15 Web Search MCPs to Connect Your AI To
Abstract
A web search Model Context Protocol (MCP) server is a standardized MCP connector that lets AI agents search, retrieve, crawl, extract, or interact with public web content. It gives developers a standard way to connect AI systems to current web data without building a separate integration for every external tool or website.
Top web search MCP servers include:
- Nimble
- Browserbase
- Exa
- Tavily
- Firecrawl
- Apify MCP
- Jina MCP Server
- Brave Search MCP Server
- Linkup MCP Server
- Kagi MCP Server
- Serper MCP Server
- DuckDuckGo MCP Server
- WebSearch-MCP
- Perplexity MCP Server
- Playwright MCP
Most production AI agents eventually run into the same constraint: they need current public web data, but the model itself cannot retrieve it. Prices change, documentation updates, pages move, and search results shift after training. If your agent cannot reach those sources at runtime, it is forced to reason from stale context.
Web search MCP servers provide a standard way to expose live web access to AI agents without building a separate integration for every tool. The MCP ecosystem has expanded quickly, with one registry listing more than 5,500 servers of various types. For AI engineers, the question is which web search MCP fits the job your system needs to perform.
What is a Web Search MCP?
The Model Context Protocol (MCP) is an open standard for connecting AI applications to external tools and data sources. MCP servers implement the protocol and expose tools or resources that an AI application can access at runtime.
A Web Search MCP is an MCP server whose primary purpose is public web access, letting an AI agent search, retrieve, crawl, extract, or interact with live web content. AI agents often lack direct access to current web data or external tools unless engineers build custom integrations for each source. Web search MCPs solve that by providing a standardized interface for web access, reducing one-off integration work for every data source.
Web search MCPs are used by AI engineers, developers, and technical teams building agents to access live search results, current page content, structured public data, or browser-rendered web pages in production.
Clearing Up Confusion Around Web Search MCPs
Not every server that uses MCP is built for web access. Some connect agents to internal systems, repositories, databases, or observability tools. A web search MCP is specifically designed for agents that need to search, retrieve, extract, or interact with public web content.
Web search MCPs are not required for every agent workflow. If the agent only needs static prompt-based responses, or the workflow has no dependency on live web data, a direct API integration may be simpler than adding a web search MCP server. In smaller or tightly scoped workflows, MCP can also introduce orchestration and integration overhead that may not be necessary.
Key Terms
- MCP client: The AI application or environment that connects to MCP servers.
- Tool call: An action the AI system requests through an MCP server.
- Category: The MCP server’s primary role in a web access workflow, such as web data infrastructure, AI web search, web crawling and extraction, web search and retrieval, answer engine, or browser-based web access.
- Agent capability: What the MCP enables the AI system to do, such as search the web, retrieve pages, crawl sites, extract structured data, access SERP results, generate cited answers, or interact with dynamic pages.
- Output format: What the AI system gets back, such as search results, structured data, extracted text, Markdown, SERP data, cited answers, screenshots, or browser state.
- Setup effort: How much work is required to configure, authenticate, and use the MCP server.
Top Picks at a Glance
AI Web Search
- Recommended for customizable AI web search and structured live web data: Nimble
Web Crawling and Extraction
- Recommended for web scraping and page extraction: Firecrawl
Web Search and Retrieval
- Recommended for URL reading and retrieval workflows: Jina MCP Server
Answer Engine
- Recommended for answer-based web research and cited responses: Perplexity MCP Server
Browser-based Web Access
- Recommended for hosted browser access and dynamic websites: Browserbase
Top 15 Web Search MCPs [by Category]
AI Web Search
AI web search MCPs help agents retrieve relevant web context during reasoning or research tasks. The best options return useful sources quickly and reduce the cleanup required before the model can use the result. Key features to evaluate are retrieval quality, freshness, latency, citation support, source transparency, and output usability.
1. Nimble – Recommended for live web intelligence and structured web data

When deployed as an MCP server, Nimble gives AI agents direct access to the live web through a complete web data platform. Rather than limiting agents to search results, Nimble enables them to search, extract, map, crawl, and structure data from public websites in real time. The platform exposes these capabilities through MCP-compatible tools, allowing agents to retrieve fresh web intelligence and convert it into analysis-ready outputs without building custom retrieval infrastructure.
This makes Nimble particularly valuable for production AI systems that depend on accurate, current web data. Teams can customize retrieval workflows, create reusable extraction agents, and deliver structured outputs that plug directly into downstream reasoning, analytics, and automation pipelines.
Key Features:
- Focus Modes: Customize web search to return precise data from specific domains and use cases, including shopping, news, company research, or general search. This helps AI agents retrieve cleaner, more relevant results instead of broad, generic web outputs.
- Live Web Retrieval: Routes requests to the live web rather than relying only on cached indexes, helping agents work with current information.
- Source Transparency: Retrieves information directly from live public web sources, helping agents trace results back to their origin and validate information during research workflows.
- Flexible Search Depth: Supports both fast lookups and deeper web exploration, allowing agents to balance retrieval speed and context depth based on the task.
- Structured Outputs: Returns clean JSON so agents can reason over usable data without extra parsing or cleanup calls.
- Production-Grade Web Access: Uses Nimble’s rendering, proxy, and extraction infrastructure to improve reliability on dynamic and complex public websites.
Pricing:
Flexible pricing with both subscription plans and usage-based data access.
Review:
“Nimble has become our default platform for collecting public web data. We use a combination of Nimble IP and the Web API to route requests through residential proxies and reliably unlock sites that were very unstable with other providers.”
2. Exa – Recommended for semantic web search and concept-based discovery
The Exa MCP server offers a specialized search capability that allows models to execute concept-based, neural lookups rather than literal keyword matches. It gives your agent architecture a clean, standardized tool to uncover highly specific documentation and hidden resources that traditional search engine rules miss.
Key Features:
- Semantic Precision: Evaluates the underlying meaning of an agent's query instead of relying on exact keyword matching.
- Vector Readiness: Returns web search results and extracted content that can be used in downstream retrieval or research workflows.
- URL Similarity Mapping: Includes a dedicated endpoint tool that allows an agent to discover content matching the structure of a baseline link.
Pricing:
Free tier with 1,000 queries per month; commercial developer access tiers scale starting at $7 per 1,000 requests.
Review:
“We use Exa to give Hyper's AI agent the ability to search the web mid-conversation. When a user asks something beyond their own meeting history, Exa handles the retrieval.”
3. Tavily – Recommended for AI-native web research and source discovery
When Tavily is exposed through its MCP, the model gains the ability to retrieve information as questions develop. Search, source checking, and follow-up retrieval happen during execution rather than before it. That works well for research tasks where the answer depends on current information and traceable sources.
Key Features:
- Good for Prototyping: Works with MCP-compatible frameworks to introduce retrieval early, giving agents access to external context while prompts and tool flows are still evolving.
- Low Setup Effort: Provides a rapid, low-overhead bridge between active model prompts and live internet facts.
- Framework Integration: Connects out of the box with major AI orchestration tools without requiring unique middle-tier code.
Pricing:
Free introductory allowances with credit-capped monthly quotas. Paid technical tiers available.
Review:
“Tavily gives me results that are filtered down to what's actually about the right company, without burying me in noise or doing so much post-processing that I lose control of the raw signal.”
Web Crawling and Extraction
Crawling and extraction MCPs retrieve page content, follow site paths, and convert web pages into formats that are easier for agents or downstream systems to use. When evaluating solutions, look for crawl controls, parsing reliability, JavaScript support, extraction depth, and output cleanliness.
4. Firecrawl – Recommended for web scraping and page extraction
Deploying the Firecrawl MCP server collapses your entire extraction pipeline into a single, standardized interface. Instead of forcing your model to navigate site structures sequentially or write custom parsing logic for every new domain, the server lets your AI agents map and crawl whole domains or pull unique target URLs via an explicit tool schema. It acts as a robust translation layer that shifts the extraction burden completely off your model.
Key Features:
- High-Density Output: Translates messy HTML structures directly into clean Markdown or organized JSON arrays.
- Deep Crawl Execution: Automates multi-level, site-wide domain crawls via straightforward parameters exposed to the model.
- Self-Hosted Infrastructure: Supports cloud usage and self-hosted deployment options.
Pricing:
Subscription frameworks are credit-driven alongside a completely free, self-hosted open-source AGPL library option.
Review:
“Great if you want to give AI the ability to scrape pages with a headerless scraper, a very complete AI, and a dashboard to manage results. Nice UI, clear docs.”
5. Apify MCP – Recommended for marketplace-based web scraping and site-specific data extraction
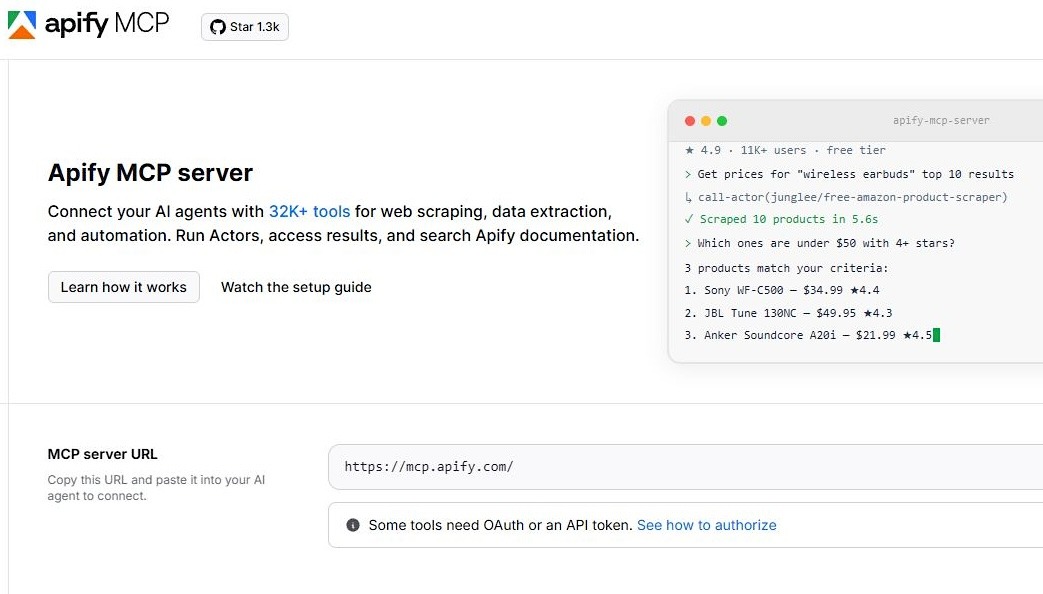
Deploy Apify through its MCP, and the solution does not begin with an empty page, because the retrieval paths already exist. The MCP server lets agents discover and run Apify Actors, and returns structured output without rebuilding the extraction layer each time. The work becomes less about reaching the page and more about deciding what to collect. That makes sense when the target sites are known, and the value comes from getting structured data back quickly.
Key Features:
- Actor Integration: Runs Apify Actors (pre-built cloud scripts) for web scraping, data extraction, and automation.
- Workflow Automation: Supports scheduling parameters, automated task backgrounding, and direct database pipeline outputs.
- Infrastructure Management: Eliminates the overhead of building individual scrapers from scratch for major dynamic networks.
Pricing:
Free basic tier options with dev credits. Paid subscriptions scale starting at $29 per month.
Review:
“It's easy to set up and just works. I reached my goals very quickly.”
Web Search and Retrieval
These web search MCPs support lookup, URL reading, page fetching, and search-index access. They’re useful when the workflow depends on fast validation or targeted retrieval rather than full-scale crawling or browser execution. Check potential solutions to evaluate retrieval quality, freshness, rate limits, fetch reliability, geographic coverage, and returned data structure.
6. Jina MCP Server - Recommended for URL reading and retrieval workflows

The Jina MCP server works from the assumption that you already know where to look. The solution passes a URL and receives back the contents of that page in a cleaner, more usable form. There is no wider crawl, and no retrieval system growing around the request. Jina fits workflows where a single source needs to move into context quickly.
Key Features:
- Instant Text Ingestion: Extracts high-density text arrays by simply dropping the target URL path directly into the tool call.
- Boilerplate Filtering: Strips out sidebars, tracking blocks, headers, and script clutter automatically.
- Zero-Setup Gateway: Provides a streamlined shortcut for single-page retrieval tasks without massive backend setup.
Pricing:
Free public technical utility with flexible consumption thresholds for development pipelines.
Review:
“The effective embedding is multilingual, and multimodal search is exceptional.”
7. Brave Search MCP Server – Recommended for independent-index web search and result validation
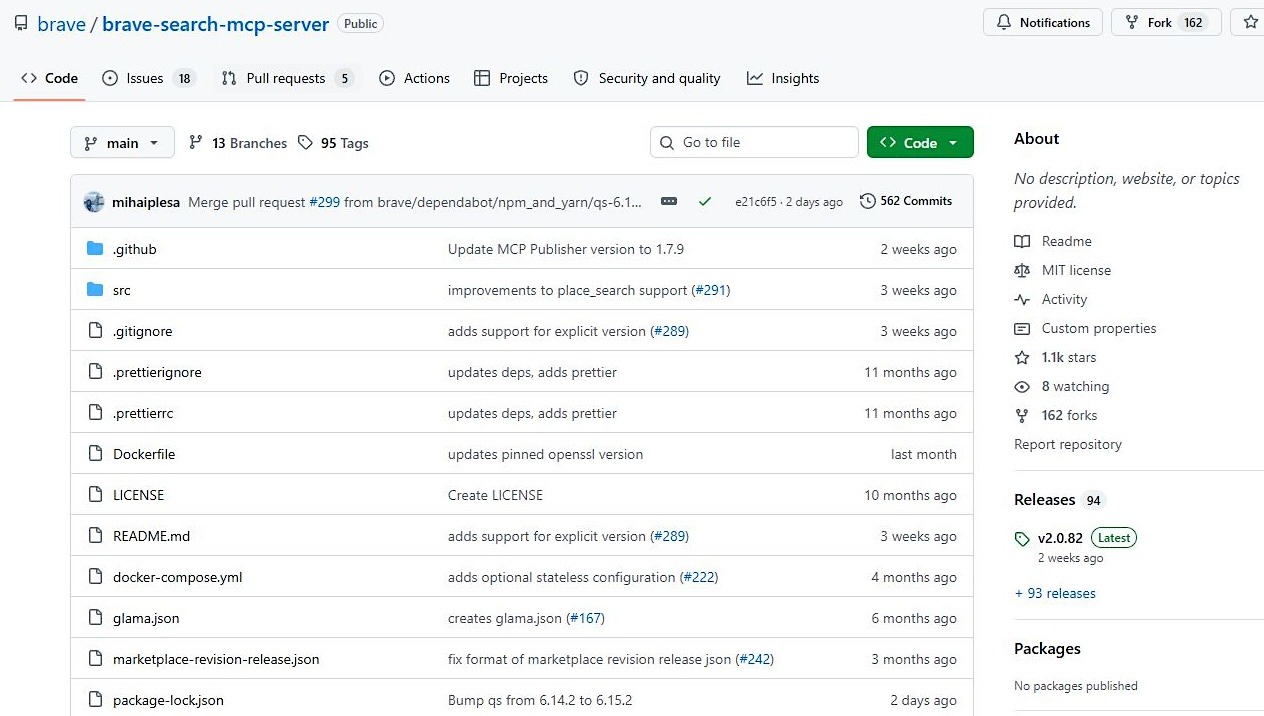
Brave Search MCP server gives your agent architecture a private, stable connection to a completely independent scale index. It achieves this by exposing an autonomous query path that stays entirely outside legacy search engine environments. This connector allows models to validate data points and execute lookup routines without dealing with sudden upstream layout changes or scraping technicalities.
Key Features:
- Index Independence: Queries a dataset of over 40+ billion records natively, removing any operational reliance on third-party scrapers.
- Strict Privacy Boundaries: Uses Brave Search API infrastructure with privacy-oriented search capabilities.
- Pre-Formatted Payloads: Exposes a specialized LLM context endpoint that chunks raw findings into clean, concentrated text arrays before they hit the model window.
Pricing:
Clear commercial lookup rates, structured transparently, at approximately $5 per 1,000 context inquiries.
Review:
“With the Brave Search MCP server, developers can seamlessly integrate real-time web search into AI agents and applications quickly, securely, and at scale.”
8. Linkup MCP Server – Recommended for real-time web search and page fetching
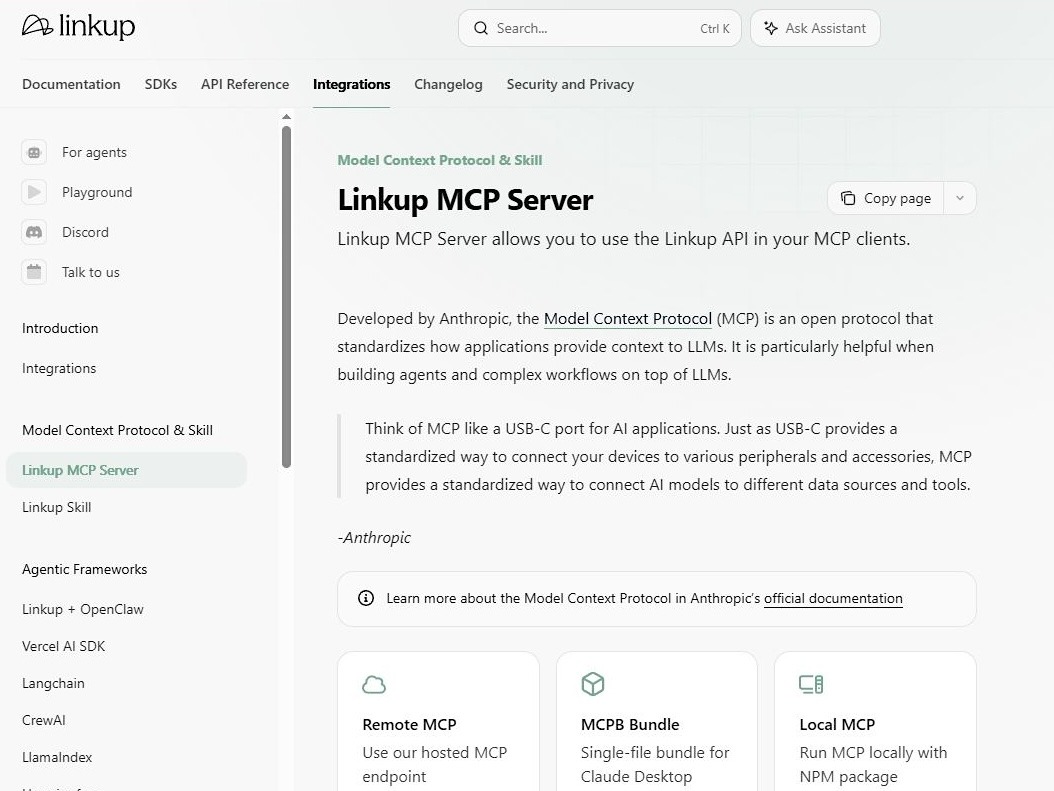
From an architecture standpoint, Linkup collapses the traditional search-then-scrape routine into a single server framework. The MCP integration allows an AI agent to query the internet and receive text results or fetched page content rather than only a list of raw links.
Key Features:
- Consolidated Pipelines: Integrates web query execution and page fetching loops inside a single protocol server step.
- Token Optimization: Filters out dynamic navigation elements and returns high-density text payloads to save context space.
- Execution Acceleration: Reduces request overhead by removing the need for custom proxy layers between the model and retrieval tools.
Pricing:
Commercial lookups are billed via standard volume consumption metrics.
Review:
“This server enables AI assistants like Claude to perform intelligent web searches with natural language queries and fetch content from any webpage, accessing real-time information from trusted sources across the web.”
9. Kagi MCP Server – Recommended for privacy-focused web search and content summarization
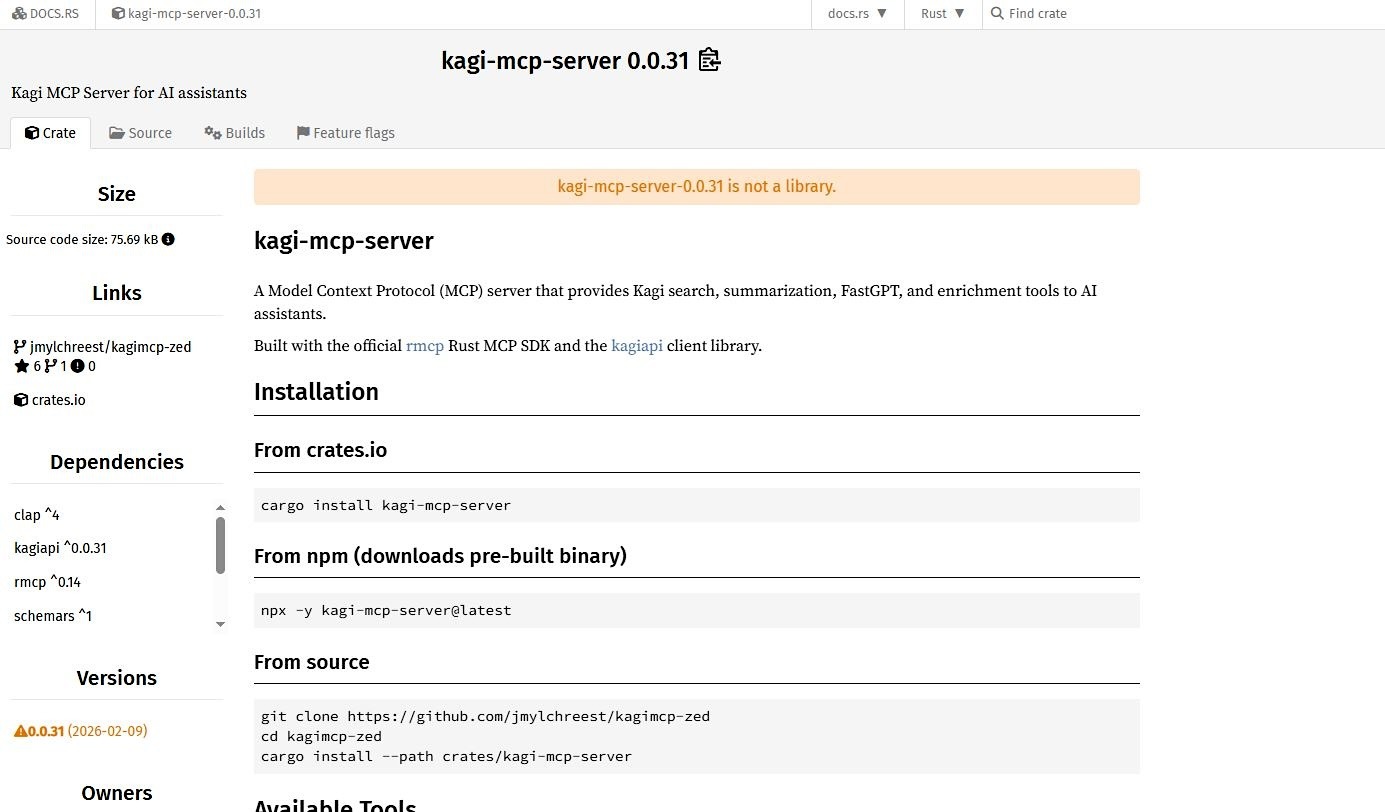
Accessing Kagi through its MCP server changes what the model sees when it searches. Queries return pages and summaries without much of the advertising and tracking machinery that normally surrounds them. The result is a cleaner input and a quieter research process. Kagi works well when the goal is to gather information without adding unnecessary signals to the model’s context.
Key Features:
- Noise-Free Results: Provides Kagi search, summarization, FastGPT, and enrichment tools through MCP.
- Summarization Routines: Includes built-in document compression tools to keep agent context windows efficient.
- Deep Index Surfacing: Optimizes results by surfacing high-quality, independent resources that ad-driven platforms bury.
Pricing:
Requires configuration linking to an active commercial Kagi developer API account plan.
Review:
“Its results are clean, customizable, and incredibly high-quality.”
10. Serper MCP Server – Recommended for Google Search data and SEO research
Integrating the Serper MCP server equips an AI agent with a high-speed conduit to Google Search results via the Serper API. The protocol configuration maps complex, multi-layered search elements straight into cleanly structured data arrays, allowing your models to run automated competitive analysis and SEO tracking without the overhead of rendering full target web pages or managing complex DOM layout changes.
Key Features:
- Layout Parsing: Extracts organic ranks, local map fields, paid ads, and metadata blocks simultaneously.
- Granular Geotargeting: Tracks search details down to specific zip code parameters for highly localized business context.
- Low-Latency Transfers: Streams structured search records quickly without running multi-step site-scraping logic.
Pricing:
2,500 free introductory queries upon configuration.
Review:
“Serper is a comprehensive search and location server that integrates with the Serper API, designed to enhance AI assistants by providing various search functionalities.”
11. DuckDuckGo MCP Server – Recommended for lightweight public web lookup
DuckDuckGo MCP server is a lightweight, configuration-free gateway that connects an AI-assistant to public search channels that don’t require a developer account or API key. It exposes search capabilities directly through the protocol, meaning developers can quickly implement basic lookup tools for local agent testing and intermittent data checking.
Key Features:
- Configuration-Free Setup: Enables instantaneous model web integration with no developer signup steps or pricing tracking.
- Prototype Access: Pulls standard public text snippets and links quickly to check real-time facts.
- Minimal Footprint: Runs with negligible system overhead for applications that only require occasional internet connectivity.
Pricing:
Completely free to use under open public access rate boundaries without API token keys.
Review:
“The DuckDuckGo MCP Server provides web search and content retrieval capabilities through DuckDuckGo's search engine, enabling LLM-based applications to perform internet searches and fetch webpage content.”
12. WebSearch-MCP – Recommended for self-hosted web search infrastructure
WebSearch-MCP is a self-hosted retrieval layer for teams that want local control over web search execution. Models issue requests through MCP and retrieve information directly from internal search systems, private indices, or custom data services.
Key Features:
- Private Network Isolation: Runs entirely inside corporate network perimeters to guarantee absolute data privacy.
- Custom Node Links: Allows software engineers to bind unique internal data collections or local private indices.
- Zero Variable Costs: Eliminates monthly vendor platform billing thresholds by running exclusively on private hardware.
Pricing:
Free and open-source under standard development licensing.
Review:
“The Web Search connector gives Claude the ability to search the public internet for real-time information, including verifying facts, pulling recent news, and researching topics outside its training data.”
Answer Engine
Answer engine web search MCPs combine retrieval with synthesis. They are useful when the agent needs a researched answer rather than raw web results. Buying considerations include citation quality, source transparency, recency, answer consistency, and how much control you retain over the underlying retrieval process.
13. Perplexity MCP Server – Recommended for answer-based web research and cited responses
Building custom code to make an agent cross-reference search results and verify facts takes a lot of development time. Running Perplexity through an MCP server lets you offload AI search and answer synthesis to a dedicated answer engine. Your application receives a highly concentrated summary text with citations that can be used by the agent or application.
Key Features:
- Conversational Synthesis: Provides models with fully summarized research text, reducing the need for multiple internal prompt runs.
- Automatic Citations: Appends clear source tracking variables to every returned block to ensure full traceability.
- Real-Time Coverage: Processes information across widespread live news sources and public documentation networks.
Pricing:
Consumption metrics map directly to underlying enterprise token rates on Perplexity's developer infrastructure.
Review:
“Perplexity has a clean, intuitive interface with a beautiful design that makes searching a pleasure.”
Browser-based Web Access
Browser-based MCPs let agents work through a live or hosted browser environment. They fit workflows that depend on rendered pages, multi-step navigation, form interaction, or JavaScript-heavy sites. Buying considerations include session reliability, rendering accuracy, automation controls, scalability, compute cost, and operational overhead.
14. Browserbase – Recommended for hosted browser access and dynamic websites
The Browserbase MCP server acts as an infrastructure layer that allows AI models to control remote browser sessions. Instead of managing local headless browser infrastructure, agents interact with complex web applications via cloud-hosted containers.
Key Features:
- Containerized Execution: Operates headless browser instances inside scalable cloud environments to protect host memory stability.
- Interactive Actions: Natively translates model intent into mouse clicks, form configurations, and deep session pathways.
- Dynamic DOM Capturing: Extracts complete script-rendered pages and visual confirmation screenshots after complex elements finish loading.
Pricing:
Plans operate on scalable hourly browser execution rates and concurrent background session volume.
Review:
“Made it insanely easy to run real browser sessions for our AI agents. Without it, the whole system would be 10x harder to build and scale.”
15. Playwright MCP – Recommended for browser-based page interaction and UI testing
Linking your agent to an open-source Playwright browser automation framework shifts the operational dynamic from simple data scraping to active environment manipulation. Instead of treating a web destination as a static document to download, the protocol allows an AI system to spin up an automated browser instance right inside your immediate server environment.
Key Features:
- Granular Instance Control: Controls browser execution paths, layout states, and automated system commands directly.
- Local Ingestion Infrastructure: Runs with zero vendor-per-page usage costs or external cloud connection needs.
- Automation Engineering: Ideal for building continuous integration tasks, visual debugging scripts, and quality assurance workflows.
Pricing:
Completely free and open-source utility under standard software distribution licensing.
Review:
“What I like most about Playwright is how reliable it is for end-to-end testing. It supports multiple browsers (Chromium, Firefox) and handles modern web apps really well.”
How We Compared These Tools
We reviewed each web search MCP server from the perspective of deciding whether to put it into a real workflow, such as what it retrieves, how difficult it is to connect, what limits appear after setup, and whether the product appears actively maintained. Everything in this guide reflects information that was public on 27 May 2026.
What We Looked At:
- Documentation and onboarding materials.
- Pricing models, quotas, and account requirements.
- Release notes, changelogs, and signs of ongoing maintenance.
- Repository activity and developer discussion, where available.
How We Evaluated Each Tool:
Our comparison focused on retrieval capability, implementation effort, output structure, and behavior under common retrieval constraints. We considered the unique buying considerations for each category of web search MCP as defined in this article.
We did not execute identical hands-on speed tests for every option listed. Where a technical metric or unblocking parameter lacked explicit documentation, we highlighted the uncertainty to keep the findings verifiable.
Current Context Starts With the Right Web Search MCP
MCP servers give AI systems a standard interface for connecting to external tools and data sources. Choosing the right web search MCP comes down to four things: use case, setup effort, output type, and access control needs. Agents that work with current context rather than relying solely on model knowledge are more useful in production, and the server you choose determines how reliably that context arrives.
For AI engineers building agents that need live web intelligence and structured public web data at scale, Nimble is the MCP to prioritize. Its MCP server connects agents to real-time search, extraction, crawling, and structured output capabilities. That makes it particularly relevant for workflows where data freshness and output consistency directly affect results: AI search, market intelligence, pricing intelligence, and product monitoring.
Book a Nimble demo to experience how its MCP server connects your AI agents to live, structured public web data at scale.
FAQ
Answers to frequently asked questions
![Top 9 AI Enterprise Search Solutions for 2026 [by Category]](https://cdn.prod.website-files.com/699c65d475d592ff4cf9729d/69fc42a16546ad21fd4c45bc_Top%209%20AI%20Enterprise%20Search%20Solutions.png)
.avif)
.png)
.png)
.png)

.png)