Top 8 AI Web Search Engines
.avif)
Ilan Chemla
.png)
Top 8 AI Web Search Engines
Ilan Chemla
Most popular articles

Get structured, reliable data for your stack.
Top 8 AI Web Search Engines
What happens when your production AI agent makes decisions based on outdated web data? There’s a gap between the snapshots traditional search APIs use and the data that is available live on the web. Most search APIs rely on pre-indexed databases that may lag behind what is actually published online. When production AI agents or internal tools make business or infrastructure decisions based on stale information, it becomes a reliability problem for engineers and developers.
Enterprises expect their agents to perform mission-critical tasks like conducting market research or optimizing supply chains. However, there is a disconnect between expectations and execution. The data extracted for model training is often stale or incomplete. With 40% of enterprise applications likely to have task-specific AI agents by the end of 2026, this lagging data is a barrier to the next phase of automation.
AI web search engines for agents address this issue by serving as the programmatic retrieval layer that connects AI agents to live web data. If your team wants to get the most out of production agents, this retrieval layer is the most critical part of the integration. An agent's reliability is ultimately limited by the freshness and completeness of the data that layer provides. It also depends on whether that data is delivered in structured formats that can be processed directly inside automated workflows.
Let's take a closer look at the top AI web search engines and how to decide which one is right for your organization.
What are AI web search engines?
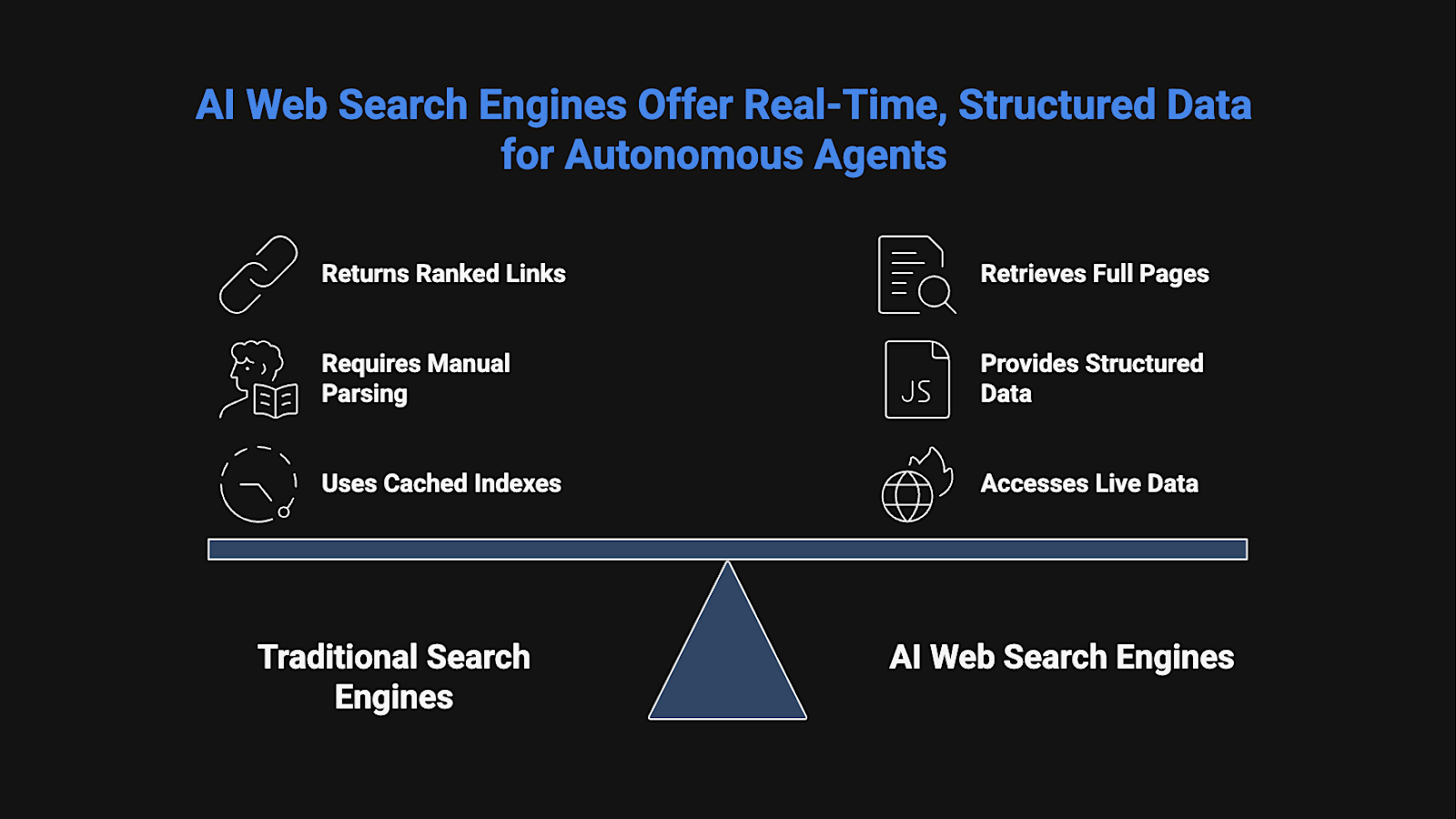
Traditional search engines are manual research tools that require a human to act as the integration layer. That process is inefficient for automation and unsuitable for autonomous AI systems.
AI web search engines are programmatic retrieval layers that allow AI agents to access and process live web data autonomously. Instead of returning ranked links like traditional search engines or querying pre-built indexes, they execute searches and retrieve full underlying pages at request time. The collected data is then delivered directly into agent workflows for downstream reasoning.
The value of AI web search engines comes from retrieving current information and returning it in structured formats that can be used directly inside production agent workflows.
They are most useful in scenarios where:
- Information changes frequently enough that cached indexes quickly become outdated, such as real-time pricing or availability data.
- Questions require interpretation across multiple sources.
- Teams need structured, machine-readable data (like JSON) that can be consumed directly inside automated workflows, rather than long blocks of text that require additional parsing.
- AI agents must operate autonomously without human supervision.
As AI agents move into production, the effectiveness of AI web search engines depends on how reliably they can retrieve and structure live web data.
How do AI search engines work?
Although individual implementations vary, most AI search engine workflows look something like this:
- An AI agent submits a request via API.
- The AI search engine determines what information is needed to fully answer the query.
- Relevant sources are identified through ranking or heuristics.
- Pages are accessed and rendered at request time rather than pulled from pre-indexed databases.
- The content is then parsed into structured formats and passed into an AI model.
- The model uses the collected data to complete a task or generate an answer.
In a traditional RAG (Retrieval-Augmented Generation) pipeline, prompting can improve answer quality, but overall accuracy still depends on retrieval quality. Autonomous agents operate in a continuous loop where state and retrieval consistency matter more than prompt phrasing.
If the retrieval layer lags or produces outputs that are difficult to use, the agent's reasoning chain is compromised from the first step, which is a limitation that affects many AI search tools. Nimble addresses this problem through its live web execution layer by browsing the web and returning structured, validated data.
Types of AI Web Search Engines
There isn't a standard way to classify AI search solutions yet. The space is still relatively new, and vendors often blur category lines in how they position their products. They may market themselves as both a lightweight search tool and a full-stack AI platform. Because of this overlap, developers and leadership should evaluate these tools across multiple functional layers:
Types by Tech Stack Layer
There are several layers to consider when evaluating AI web search engines, depending on the level of control and execution depth required:
- User-facing apps like Perplexity or ChatGPT focus on a conversational experience and a strong interface. They use high-level APIs to access data.
- Embedded search tools like Gemini and Microsoft Copilot retrieve data as part of a workflow. They can access the web and private work data within their ecosystems.
- Programmatic infrastructure tools like Nimble provide developers with a way to feed live web data directly into AI agents without building and maintaining scrapers.
- Underlying execution infrastructure is also required to handle bot protections and render dynamic JavaScript. This layer determines whether an AI system can reliably access live webpages instead of static snapshots.
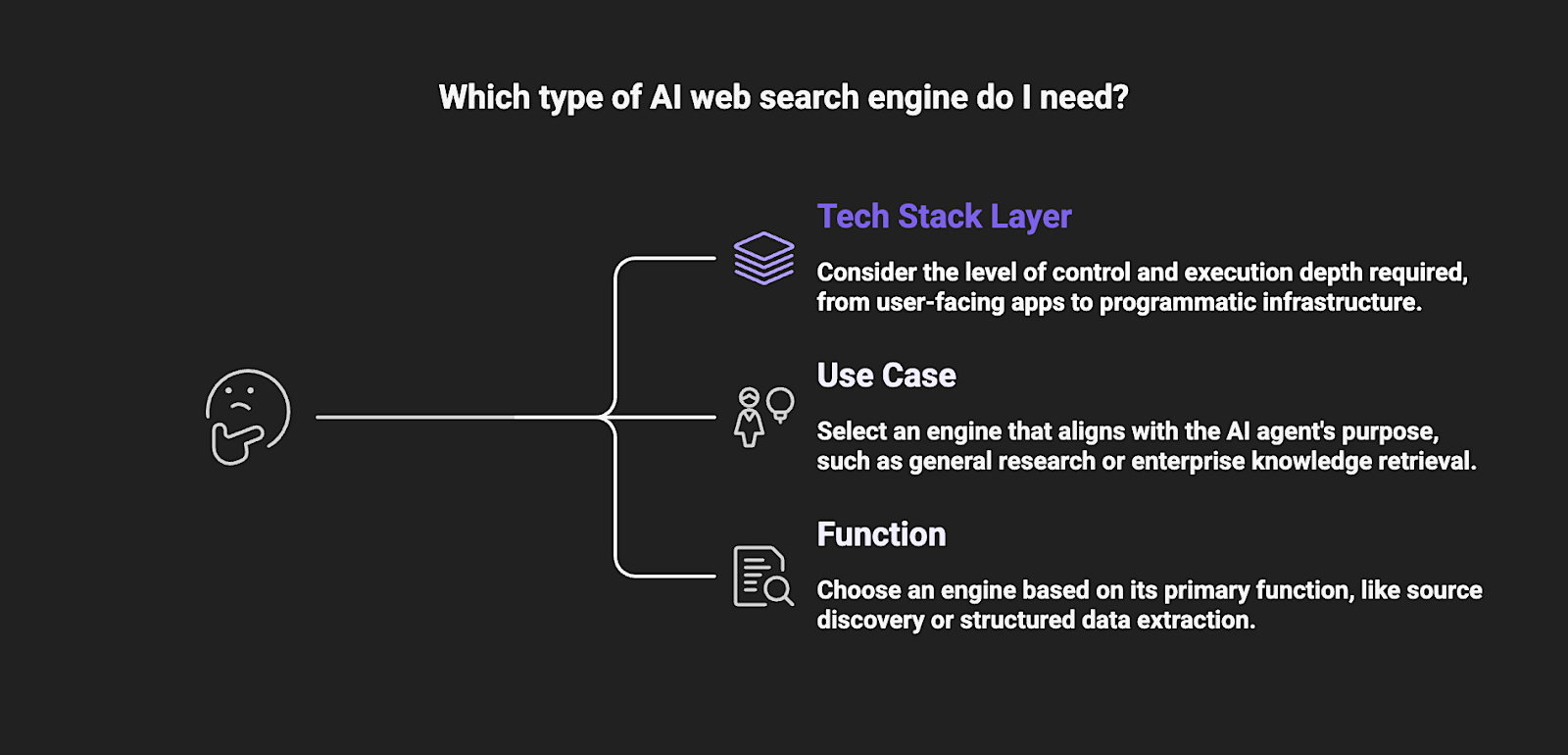
Types by Use Case
Different AI agent workflows require different levels of retrieval capability. Selecting the right AI web search engine depends on the AI use cases the agent is designed to support. These include:
- General research and broad information gathering – The search engine retrieves web pages and generates synthesized answers intended for human consumption.
- Exploratory discovery across multiple sources – These search engines evaluate results across domains, rank relevant sources, and return material that can be examined or compared.
- Enterprise or internal knowledge retrieval – In enterprise environments, the search engine connects to internal systems or secured data sources and retrieves information within controlled workflows.
- Real-time data retrieval for model training, dynamic pricing, and production monitoring workflows – When used inside automated systems such as LLM training pipelines or dynamic pricing engines, the search engine executes queries at request time and returns structured web data for downstream processing.
Types by Function
AI web search engines also differ based on what they do with retrieved information. While many tools span multiple functions, they typically emphasize one of the following:
- Source discovery and ranking – Systems like Tavily API identify and prioritize relevant, high-quality sources that agents can use for reference.
- Live retrieval – Tools like Nimble pull web content at request time while handling dynamic pages and JavaScript rendering. They return structured data for downstream workflows.
- Structured data extraction – Solutions like Firecrawl transform web content into structured, machine-readable formats suitable for agent workflows.
- Answer synthesis – Frameworks like LangChain and LlamaIndex combine retrieved data into context-aware outputs that an agent can use for reasoning or responses.
For production AI agents, understanding where a tool sits across these layers helps determine whether it supports reliable execution or primarily enhances user-facing search experiences.
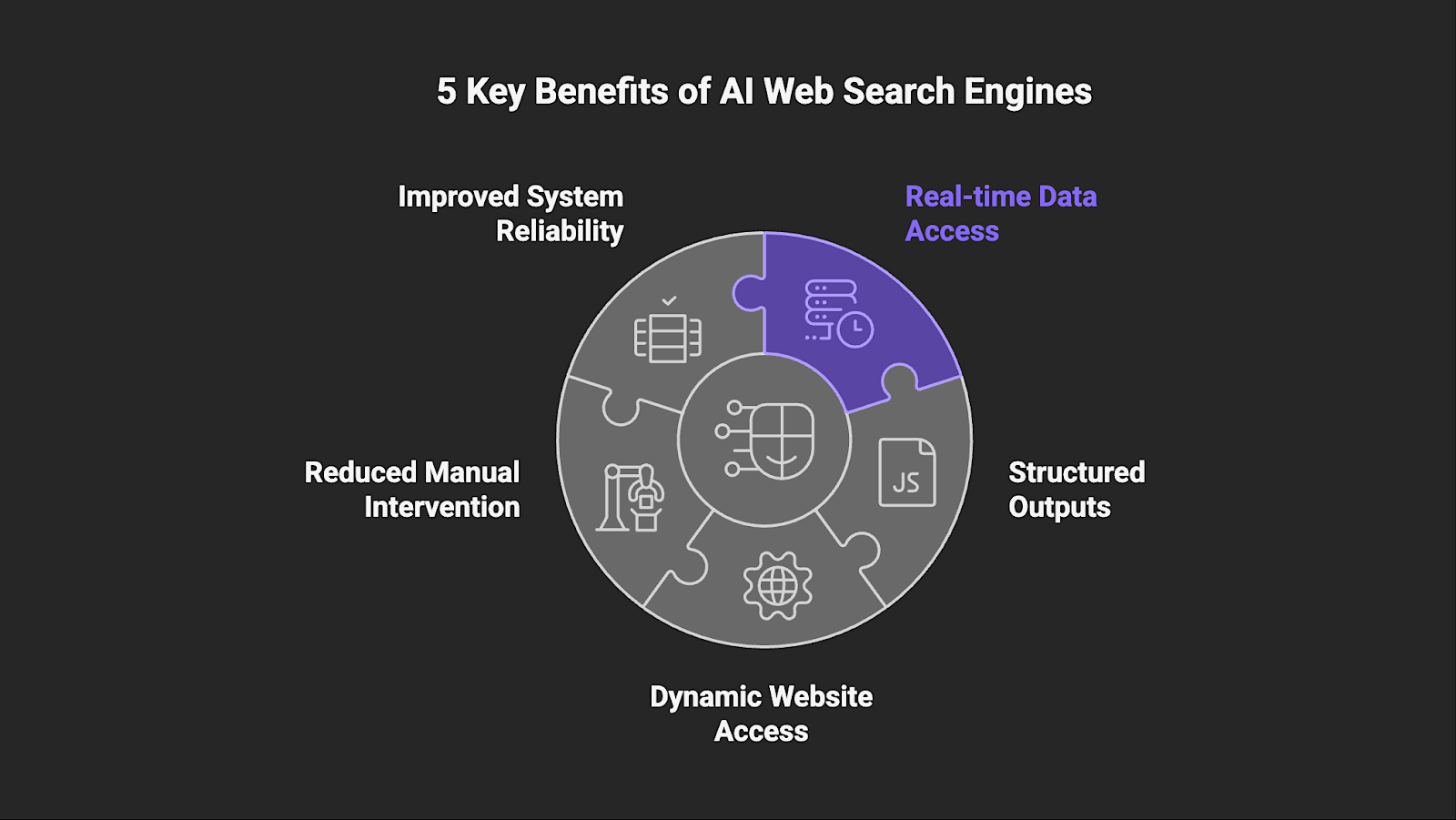
5 Key Benefits of AI Web Search Engines
When deployed inside production AI systems, AI web search engines provide several operational advantages:
- Access to real-time web data – AI web search engines retrieve information at request time rather than relying on cached indexes, reducing the risk of outdated responses.
- Structured outputs for downstream processing – Instead of returning long text passages, AI web search engines deliver structured data such as JSON that can be processed directly inside automated workflows.
- Reliable access to dynamic and protected websites – Rendering JavaScript and handling anti-bot mechanisms enables these search engines to retrieve content that traditional search APIs often miss.
- Reduced manual intervention – Autonomous retrieval removes the need for human-driven search and comparison across multiple sources.
- Improved system reliability – When AI agents are grounded in current, structured web data, decision quality and workflow stability improve across enterprise environments.
Key Features to Look for in AI Web Search Engines
When evaluating AI web search engines for production use, several technical capabilities determine whether the system can support reliable agent workflows:
- Request-time retrieval – Systems must retrieve data at request time instead of relying on cached indexes to ensure current information.
- Dynamic site execution – Headless browsing and proxy rotation should capture the full content of JavaScript-heavy pages and access protected sites.
- Blocking resistance at scale – Fingerprinting and proxy management should reduce request failures under sustained production workloads.
- Predictable failure behavior – When data is unavailable or blocked, the system should fail explicitly and should not fabricate answers.
- Retrieval and generation separation – The retrieval layer should operate independently from generation so that agents can use their own models or pipelines on top of it.
- Output format flexibility – Teams should be able to choose between raw sources, structured outputs, or summaries depending on the workflow.
- Response control – Developers should be able to control response generation parameters and failure handling.
The Top 8 AI Web Search Engines
1. Nimble – Best for Live Web AI Search with Structured Outputs for Production AI Agents
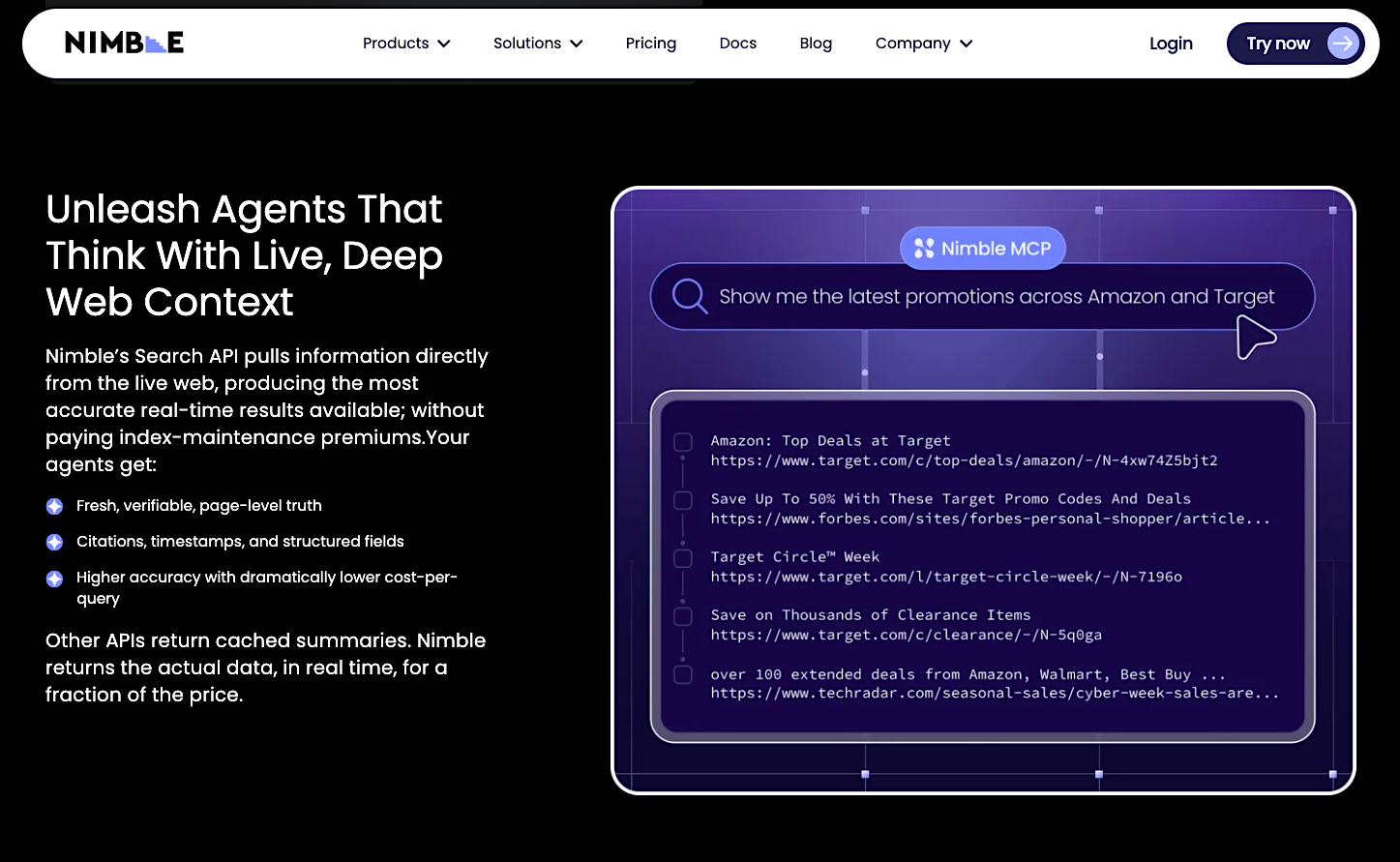
Nimble is the execution layer that connects AI agents to the live web. Instead of querying stale indexes, it goes page to page, renders the JavaScript, and returns structured data that AI systems can use immediately. While some search tools prioritize low-latency responses from cached databases, Nimble prioritizes request-time execution and data accuracy for production workflows.
Through a single Search API and the Nimble SDK, agents can programmatically run/handle search and data collection. To ensure reliable access to modern web applications, Nimble handles browser execution, JavaScript rendering, and anti-bot resistance. Retrieval is separated from generation, so developers have complete control over how retrieval integrates into downstream reasoning.
Key Features:
- Real-time browsing of the live web
- Search API and SDK
- Structured JSON outputs instead of text snippets
- Enterprise-grade scraping and proxy infrastructure
- Focus Modes for shopping, social, news, and company research
- Deep Search vs. Fast Search modes
- High reliability on JavaScript-heavy and protected sites
Review: “Our customers need us to scrape web-accessible data reliably and at scale. Some of this data requires complex page interactions to obtain, as well. Nimble takes the headache out of proxy management by making our web scraping needs as easy as using an API.”
2. Perplexity – Best for Agent-assisted Deep Research with Multi-step Web Reasoning
Perplexity functions like a research-heavy agent that wraps LLM models like GPT-4 and Claude with native web tools. It operates as an agent layer that determines when to search the web and how to incorporate sources into its answers. The Deep Research mode automates the process of clicking through links and synthesizing multiple sources into structured reports. It's built for discovery tasks where you need a front door to the web that prioritizes cited evidence.
Key Features:
- Live web search with inline source citations
- Deep Research for extended, multi-source investigation
- Create files and apps functionality
- Internal Knowledge Search for enterprise plans
- Search and model APIs for embedding capabilities
Review: “It saves a lot of time when I’m researching or validating information, especially when accuracy matters.”
3. ChatGPT – Best for General-purpose AI Agent Workflows with Browsing
ChatGPT supports agent-driven search through features such as Agent Mode and Deep Research, enabling it to interact with websites and execute multi-step workflows. It can navigate across pages, gather information from multiple sources, and maintain context while generating outputs. In Agent Mode, ChatGPT operates within a virtual browsing environment that allows it to take actions on web interfaces, but it doesn't handle structured retrieval pipelines.
Key Features:
- Agent Mode for autonomous browser control
- Deep Research for extended, multi-source investigation
- Virtual browsing environment with interactive page control
- Context persistence across tasks and tools
- Connectors for integration with external applications
Review: “When I give the agent good guidelines, it can do the entire job from A-Z.”
4. Tavily – Best for Simple AI Search API Integration
Tavily is an agent-native search engine that focuses on context over raw data. Tavily uses a proprietary LLM-based ranking and filtering to filter, rank, and then summarize webpages into short snippets that can fit into a model's context window without wasting tokens. It handles scraping and deduplication, making it a plug-and-play search layer for organizations with RAG pipelines, though it is less effective for sites with multi-step JavaScript rendering.
Key Features:
- LLM optimized search results (low-token context)
- Search and extract endpoints
- Automated research API for iterative deep dives
- Built-in RAG ranking
- Advanced domain and date filters
Review: “Tavily is a solid tool in many cases, but like most web search APIs, it doesn’t always guarantee live or high-quality links.”
5. Exa – Best for Embedding-based Semantic Web Discovery
Exa is a neural search engine that works to understand the meaning of a page rather than just matching keywords. Instead of ranking by SEO or ads, its model is trained to predict the next relevant link an agent would want to see. It indexes and ranks content using embedding-based similarity rather than traditional keyword scoring. It is well-suited for finding high-quality, niche results.
Key Features:
- Neural intent-based search
- Sub-200ms API
- Semantic "find similar" links to discover pages
- Query-based highlights
- Markdown extraction to remove navigation and ads
Review: “Exa's powerful search capabilities have been instrumental in delivering the high-quality, relevant web content our users need.”
6. Firecrawl – Best for Developer-managed Crawling Workflows
Firecrawl is a web crawling framework built for engineers developing custom data pipelines who need direct control over how sites are explored and processed. It allows teams to programmatically collect content from target domains and define how pages are parsed and returned. Crawl logic, job execution, and data handling are configured at the application level.
Key Features:
- API-based crawl job creation and management
- Structured content extraction with metadata support
- Configurable URL discovery rules and crawl depth control
- Retry logic and rate limiting controls
- SDKs for integrating crawling into custom applications
Review: “The integration with dynamic content is one of its standout features – it handles JavaScript and SPAs effortlessly, which makes the process smoother than I expected.”
7. Brave Search API – Best for Access to an Independent Search Index
This Search API provides direct access to Brave's independent web index, giving developers the ability to retrieve quality, ranked search results without relying on the infrastructure of Big Tech. Results are returned in structured JSON format for integration into applications and AI workflows. It draws from a continually updated, privacy-respecting index.
Key Features:
- Brave’s proprietary, fully independent search index
- Ranked web and image results in a clean API
- Privacy-first design
- Low-latency queries
- Flexible query parameters and result filtering
Review: “It delivers high-quality data at a reasonable price, and with intuitive data structuring. Its speed and precision have been crucial.”
8. Parallel Web Systems– Best for Lightweight Agent Search Orchestration
The AI company Parallel Web Services has created a streamlined search orchestration layer built specifically for AI agents and lightweight retrieval tasks. It doesn't act as a full browsing or crawling infrastructure, but instead focuses on helping systems execute search queries programmatically. Its API accepts natural language objectives and returns ranked, LLM-optimized excerpts designed for direct integration into agent reasoning workflows.
Key Features:
- Natural language objective-based search queries
- API security supported through authenticated API key access
- Structured JSON responses for agent integration
- Concurrency and performance controls for production workloads
- Lightweight REST API designed for AI systems
Review: “In cases where a code review comment involved a third-party library, Macroscope was able to reduce review comments by 55% by querying Parallel’s APIs.”
Ground Your AI Workflows in Live Data with Nimble
AI web search engines are now core infrastructure for production AI systems. When agents operate autonomously, reliability depends on how they retrieve and structure live web data. In production environments, retrieval architecture determines whether systems run on current information or introduce risk through cached or limited execution.
Nimble enables AI agents to browse the live web at request time, retrieve full underlying pages, and receive structured data that integrates directly into downstream systems. By handling JavaScript rendering, blocking resistance, and execution at scale, Nimble supports AI workflows that depend on accurate and timely web intelligence.
Book a demo to see how Nimble delivers structured, live web data for production AI agents.
FAQ
Answers to frequently asked questions

.png)
.png)
.png)
.png)