Top 8 Data Pipeline Tools by Category

Nimble's Expert
.png)
Top 8 Data Pipeline Tools by Category
Nimble's Expert
Most popular articles

Get structured, reliable data for your stack.
Every dataset tells a story, but few organizations can hear it in real time. Disconnected APIs, inconsistent web data, and brittle pipelines mean that most analytics teams spend more time fixing data than using it. This fragmentation slows decision-making, disrupts AI performance, and drains engineering resources.
Data pipeline tools change that. They are the operational architecture that transforms disparate sources into structured intelligence by continuously connecting, cleaning, and delivering data. Enterprise demand for real-time automation is driving the global data pipeline market, which is expected to reach $28 billion by 2030.
While traditional pipeline tools connect internal systems and APIs, newer platforms like Nimble extend that automation to the public web. They continuously stream and structure live web data into compliant, analysis-ready outputs that integrate directly into analytics and AI workflows. Each data pipeline tool category addresses a unique operational challenge.
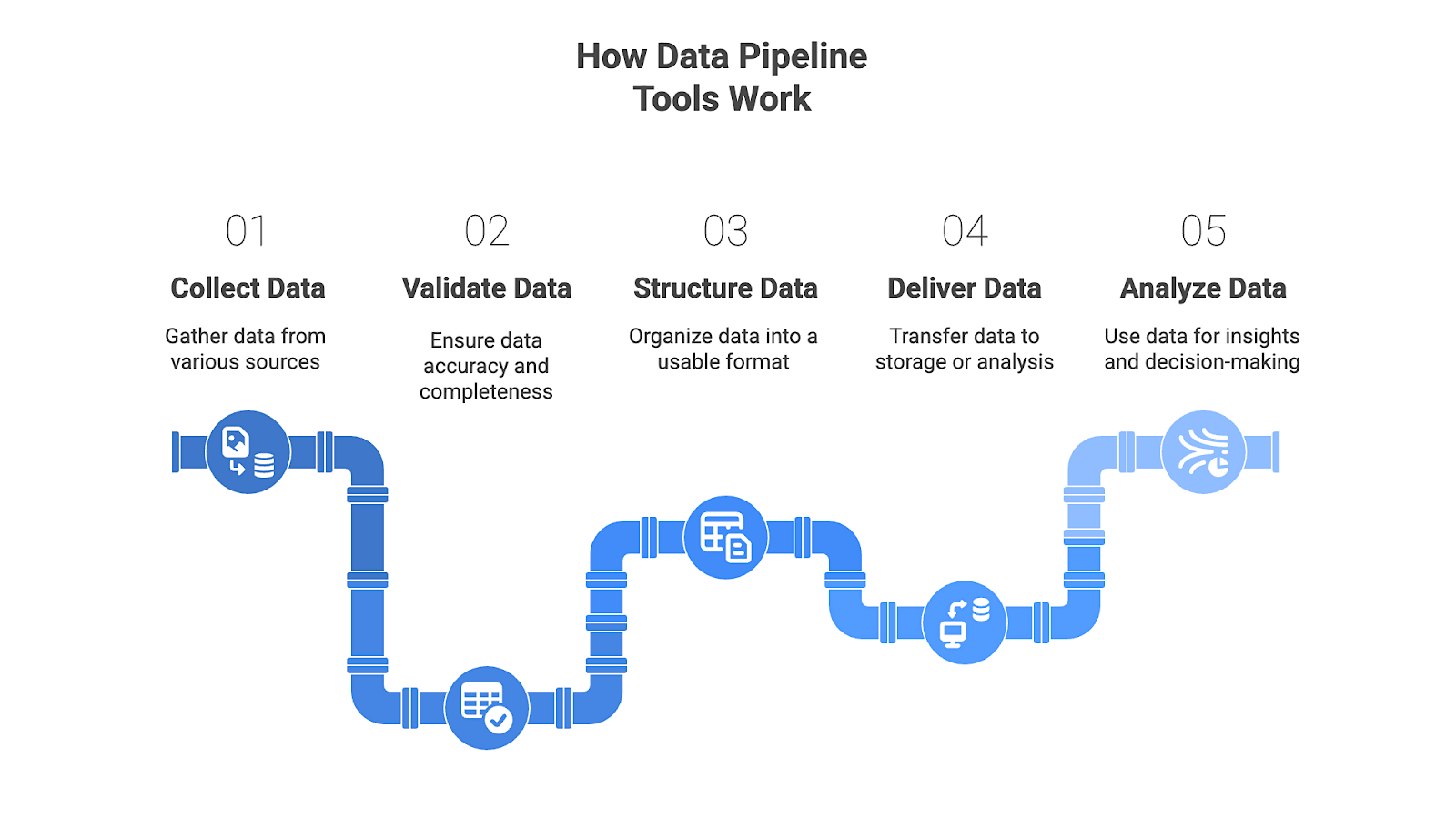
What are data pipeline tools?
Data pipeline tools automate the flow of information between systems. They collect data from web sources, APIs, databases, and SaaS applications, validate and structure it, then deliver it into warehouses or analytical environments where teams can act on it.
In enterprise settings, data pipeline tools replace brittle scripts, manual uploads, and static datasets with governed, repeatable workflows that preserve accuracy as information moves across systems.
Data pipeline tools are the core infrastructure for data engineers, analysts, and AI teams. They ensure stable ingestion, consistent dashboards, and continuously refreshed, validated training data across complex, multi-source enterprise environments.
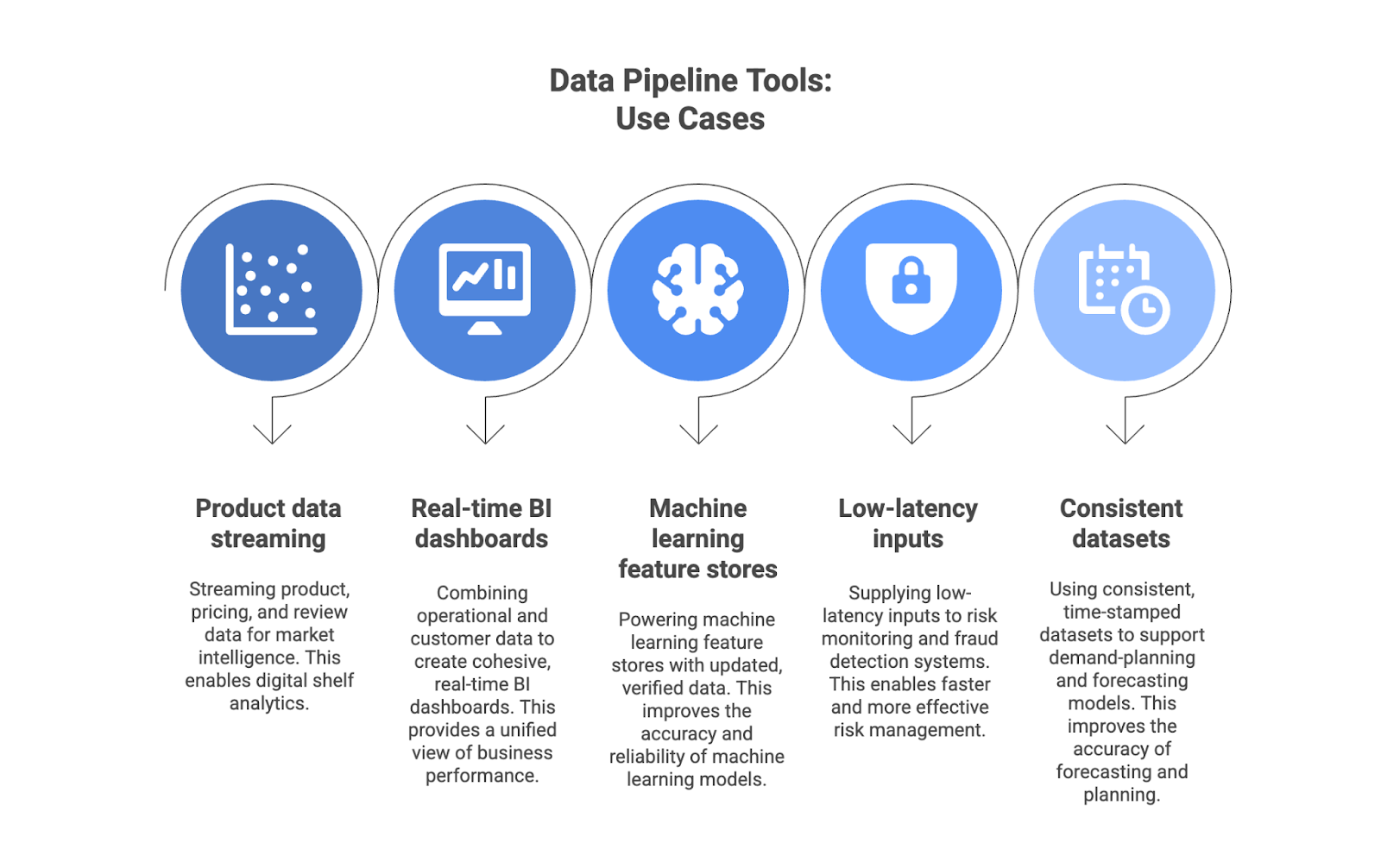
Data Pipeline Tools: Use Cases and Benefits
Common enterprise use cases for data pipeline tools include:
- Product, pricing, and review data streaming for market intelligence and digital shelf analytics.
- Creating cohesive, real-time BI dashboards by combining operational and customer data.
- Using updated, verified data to power machine learning feature stores.
- Supplying low-latency inputs to risk monitoring and fraud detection systems.
- Using consistent, time-stamped datasets to support demand-planning and forecasting models.
Data pipelines matter because real-time accuracy is now a competitive advantage. They eliminate outdated data, reduce failure points, and ensure that every downstream system runs on clean, current, and complete information.
Top 8 Data Pipeline Tools by Category
ETL/ELT Platforms
ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) platforms automate data movement from diverse sources into warehouses or data lakes. These data pipeline tools create a unified, analytics-ready source of truth. They improve accuracy, scalability, and operational efficiency across enterprise data systems.
ETL/ELT platforms eliminate manual exports and schema errors, reducing the engineering effort required to keep data consistent. Built-in monitoring and lineage tracking maintain continuous data freshness and transparency throughout the process.
1. Matillion
Matillion is a cloud-native ETL and ELT platform for Snowflake, BigQuery, Redshift, and other modern data warehouses. It combines visual workflows with transformation and integration features.
Key features:
- Visual, drag-and-drop pipeline creation with SQL or Python customization.
- Automated schema detection and transformation management.
- Built-in orchestration, version control, and error recovery.
- Native connectors for major data warehouses and SaaS platforms.
- API and REST integrations for flexible data movement across systems.
Best for: Data teams managing large workloads in Snowflake, BigQuery, or Redshift who need scalable, governed transformations without custom code.
Review: “This is a very user-friendly platform for ETL. Its visual interface makes complex workflows look easier. It offers great scalability, making it suitable for big and small-scale users.”
Data Streaming and Integration Tools
The process of continuously capturing, verifying, and combining data from databases, SaaS platforms, web sources, and APIs is powered by data streaming and integration tools. In enterprise data architectures, these tools form the live entry point of pipelines, ensuring that downstream analytics and AI or LLM training systems operate on structured, current, and compliant data.
Data streaming and integration tools deliver reliable, analysis-ready information in real-time Seamless integration of data sources across environments reduces engineering effort and keeps data flows dependable.
2. Nimble
Nimble’s Web Search Agents continuously stream public web data at scale, then clean, validate, and structure it into analysis-ready data streams that integrate directly into enterprise analytics and AI pipelines. It eliminates the need for brittle scrapers and static datasets with a managed ingestion layer that automates collection, transformation, and quality control.
Key features:
- Scalable web data streaming with automated validation and schema enforcement.
- Real-time data collection across websites, APIs, and cloud sources.
- Built-in self-healing mechanisms that adapt to layout or structural web changes.
- Continuous delivery of structured outputs compatible with BI, analytics, and AI workflows.
- Compliance-first architecture that gathers only publicly available data.
Best for: Enterprises relying on large-scale web and third-party data for analytics or AI that need a managed, self-healing streaming layer without maintaining internal scrapers.
Review: “Effortlessly deriving impactful insights from complex web data, Nimble’s advanced technology simplifies my role as a data engineer with its seamless and powerful platform. The ease of extracting and utilizing structured data is transformative.”
Real-Time and Streaming Tools
Real-time and streaming data pipeline tools process continuous data flows for instant insights and event-driven responses. By facilitating low-latency processing, large-scale streaming, and smooth integration with analytics and monitoring systems, they help businesses respond quickly to real-time data, enhance operational responsiveness, and provide AI models with consistent, high-quality data.
3. Confluent
Confluent is a managed real-time streaming platform built on Apache Kafka and enhanced with Flink and KSQLDB for advanced stream processing. It enables secure, low-latency data delivery for enterprise-scale, event-driven systems.
Key features:
- Continuous event streaming that delivers data between microservices, applications, and analytics platforms in milliseconds.
- Native integration with cloud providers, data warehouses, and observability tools.
- Enterprise-grade governance with role-based access control, and encryption in transit and at rest.
- Stream processing features that support real-time analytics and transformations.
- Automated scaling, monitoring, and recovery for production workloads.
Best for: Teams running event-driven systems needing instant visibility into transactions and metrics, especially in finance, retail, and telecom environments.
Review: “I really liked how Confluent simplified working with Kafka and Flink through managed cloud services like Azure.”
Data Orchestration and Workflow Tools
Data orchestration and workflow tools automate and coordinate complex data processes across multiple systems. These data pipeline tools centralize scheduling, track dependencies, and provide live visibility through dashboards. This coordination ensures consistent execution, faster recovery, and scalable reliability across hybrid and multi-cloud environments, while reducing manual intervention and improving overall pipeline performance.
4. Prefect
Prefect is a cloud-native orchestration platform that automates complex data workflows, simplifying scheduling, monitoring, and dependency management.
Key features:
- Centralized orchestration of data pipelines across hybrid and cloud environments.
- Built-in retry logic, dependency tracking, and real-time error notifications for reliable execution.
- A modern UI with visual dashboards for live monitoring and task insights.
- API-driven workflow design that integrates seamlessly with existing data stacks.
- Prefect Cloud for fully managed scheduling, versioning, and collaboration.
Best for: Data teams orchestrating large, multi-step workflows seeking a low-maintenance, flexible alternative to cron jobs or legacy Airflow setups.
Review: “It is easy to stand up a flow, get UI benefits for orchestration, and test and debug when flows fail.”
Cloud-Native and Managed Pipeline Services
Cloud-native and managed data pipeline tools provide fully hosted, auto-scaling data pipeline services that are integrated with major cloud platforms. They manage compliance, monitoring, and orchestration, lowering infrastructure overhead and enhancing visibility, scalability, and dependability. It enables teams to deploy complex architectures quickly and confidently while concentrating on analytics, modeling, and insights.
5. AWS Glue
A serverless data integration service, AWS Glue enables automation of data discovery, preparation, and movement across AWS tools such as S3, Redshift, and Athena.
Key features:
- Automated schema discovery through the AWS Glue Data Catalog for consistent data classification.
- Native integration with core AWS services for streamlined ingestion and transformation.
- Serverless architecture that scales compute resources automatically based on workload.
- Built-in job monitoring, logging, and error recovery within the AWS Management Console.
- Support for ETL, ELT, and data preparation tasks using Python (PySpark) or SQL.
Best for: AWS-centric enterprises needing scalable, low-maintenance data integration while modernizing legacy ETL pipelines or building cloud-native data lakes.
Review: “AWS Glue saves a ton of time by automating most of the data integration and preparation process…and because it's serverless, I don't have to worry about infrastructure.”
Transformation and Modeling Tools
These data pipeline tools enable data teams to clean, structure, and model information directly within cloud data warehouses. Transformation and modeling tools focus on in-database transformations, version control, and collaboration, so teams can standardize business logic and ensure data consistency across analytics environments. These tools ensure reliable, well-documented, and transparent analytical outputs through modular SQL development and testing.
6. dbt (Data Build Tool)
dbt is a SQL-based transformation framework that lets teams build modular, version-controlled models directly in the warehouse with testing and CI/CD integration.
Key features:
- SQL-first development that leverages existing warehouse compute for in-place transformations.
- Built-in testing, documentation, and lineage tracking for reliable and auditable data models.
- Integration with orchestration tools such as Airflow and Prefect for automated execution.
- Reusable, modular model design that promotes collaboration and consistency across teams.
- Support for CI/CD pipelines and Git-based versioning for robust change management.
Best for: Analytics and engineering teams standardizing warehouse transformations in SQL with version control, testing, and production-grade reliability.
Review: “It is the first step for me in organizing, testing, and documenting the entirety of our data models. I can track all changes made and the details surrounding each one.”
Reverse ETL (Data Activation) Tools
Reverse Extract, Transform, Load (ETL) and data activation tools are data pipeline tools that push warehouse data into CRMs, marketing, and support systems to turn analytics into action. With prebuilt connectors, scheduling, and monitoring, they ensure near-real-time synchronization and data integrity to eliminate manual exports, minimize latency, and empower teams to act on trusted information across operations.
7. Hightouch
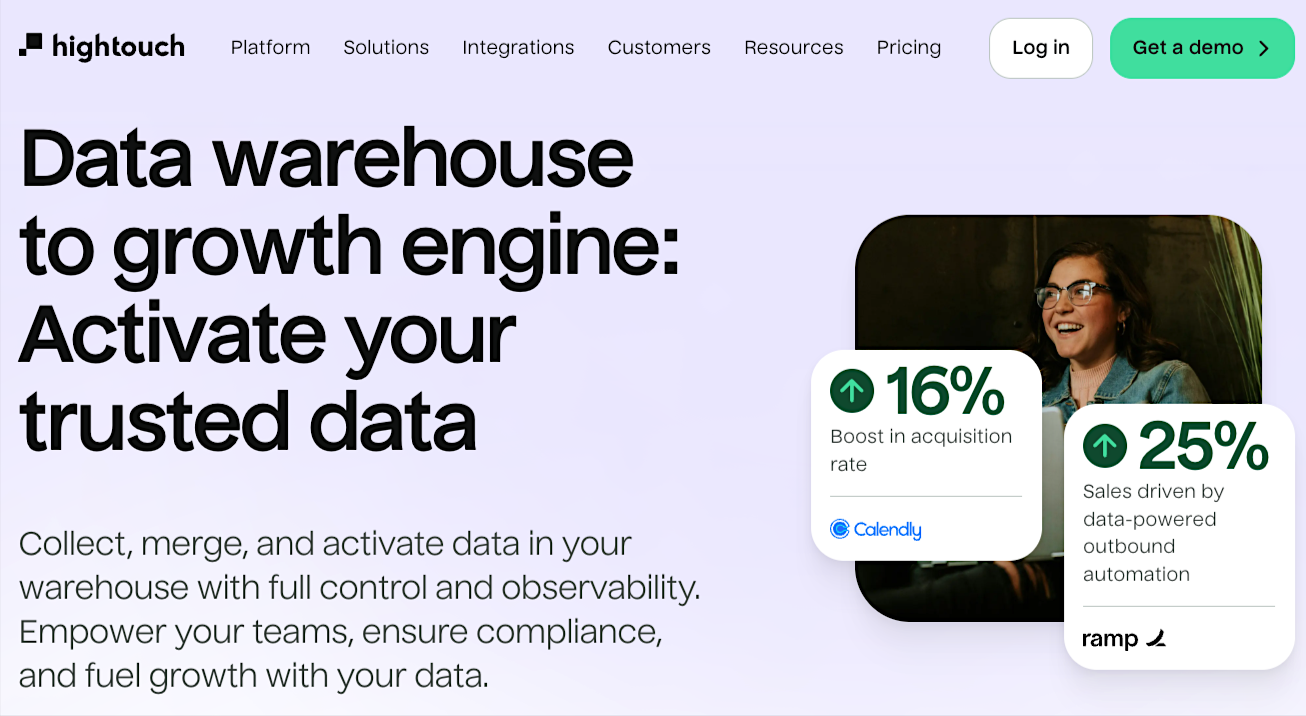
Hightouch syncs warehouse data to over 150 business apps, enabling teams to activate analytics directly within sales, marketing, and customer platforms.
Key features:
- Native connectors to major CRMs, ad networks, and support systems for rapid deployment.
- Flexible sync scheduling and prioritization to control update frequency.
- Built-in transformation and field-mapping logic to match destination requirements.
- Real-time monitoring and alerting to ensure data consistency and visibility.
- Secure architecture with cybersecurity compliance support for GDPR and SOC 2.
Best for: Organizations activating warehouse data in real time for personalization, targeting, and performance across marketing, sales, and customer platforms.
Review: “Hightouch makes it easy to activate data directly from Snowflake into tools like Braze, Iterable, and HubSpot without custom pipelines.”
Monitoring, Observability, and Data Quality Tools
These essential tools identify irregularities, track lineage, and enforce accuracy metrics to ensure dependability across data pipelines. They help analytics and AI systems run on complete, reliable, and validated data by accelerating issue resolution, maintaining compliance, and providing live visibility into pipeline health.
8. Monte Carlo

Monte Carlo uses AI agents to monitor data pipelines for anomalies and reliability issues, providing end-to-end visibility to prevent broken dashboards, missing records, and stale analytics.
Key features:
- Automated AI agents perform anomaly detection for data freshness, volume, schema, and distribution changes.
- End-to-end lineage tracking to visualize dependencies and isolate root causes quickly.
- Configurable alerting and incident workflows for faster issue resolution.
- Centralized dashboards that monitor SLA compliance and overall data reliability.
- Integration with modern data stacks, including Snowflake, Databricks, BigQuery, and Airflow.
Best for: Data teams overseeing large, distributed pipelines that require proactive monitoring and automated quality to maintain trusted, current analytics outputs.
Review: “Monte Carlo's out-of-the-box monitors create a relatively easy way to set yourself up for some potential big wins.”
Build Better Data Pipelines at the Source with Nimble
Choosing the right data pipeline stack determines whether your analytics and AI initiatives scale or stall. A reliable pipeline keeps data accurate, compliant, and actionable across every stage of the lifecycle. However, most data pipeline solutions focus only on moving information between systems and do not ensure that data streams remain continuously reliable at the point of collection.
Nimble redefines data pipelines by automating reliability at the source. Its self-healing Web Search Agents function as dynamic data streaming pipelines that continuously capture, validate, and structure public web data in real-time. When paired with Nimble’s SDKs and API infrastructure, teams can integrate fresh, compliant data directly into BI, analytics, and AI workflows without worrying about breakage or maintenance.
Book a demo to discover how Nimble’s Web Search Agents stream, structure, and deliver trustworthy web data in real-time.
FAQ
Answers to frequently asked questions
.avif)


.png)
.png)
.avif)
.png)
