AI Data Classification: Definitions, Use Cases, and Best Practices

Nimble's Expert
.png)
AI Data Classification: Definitions, Use Cases, and Best Practices
Nimble's Expert
Most popular articles

Get structured, reliable data for your stack.
Every organization building with AI faces the same challenge: data is multiplying faster than it can be managed. Product listings stretch across multiple pages, transaction logs fill cloud storage, and internal files proliferate across disconnected systems. When this information is not labeled or structured, it becomes difficult to trust, which slows down analysis, compliance, and decision-making.
AI data classification offers a way to restore order. It uses machine learning to automatically tag and organize information based on its content and context, and transforms messy, unstructured inputs into data that is clear, searchable, and secure. Recent research shows that around 80% of enterprise data is unstructured. It's locked away in formats and interactions that are difficult to analyze effectively. Classification helps close that gap by bringing structure, accuracy, and consistency to the foundation every AI system depends on.
Depth is what makes it work. Effective AI data classification depends on access to complete, continuously updated data instead of limited snapshots or outdated files. The more context your systems can capture across product pages, reviews, or transaction records, the more accurately they can identify patterns and apply the right labels. Let’s explore AI data classification and why deep, structured data is essential for scaling AI responsibly.
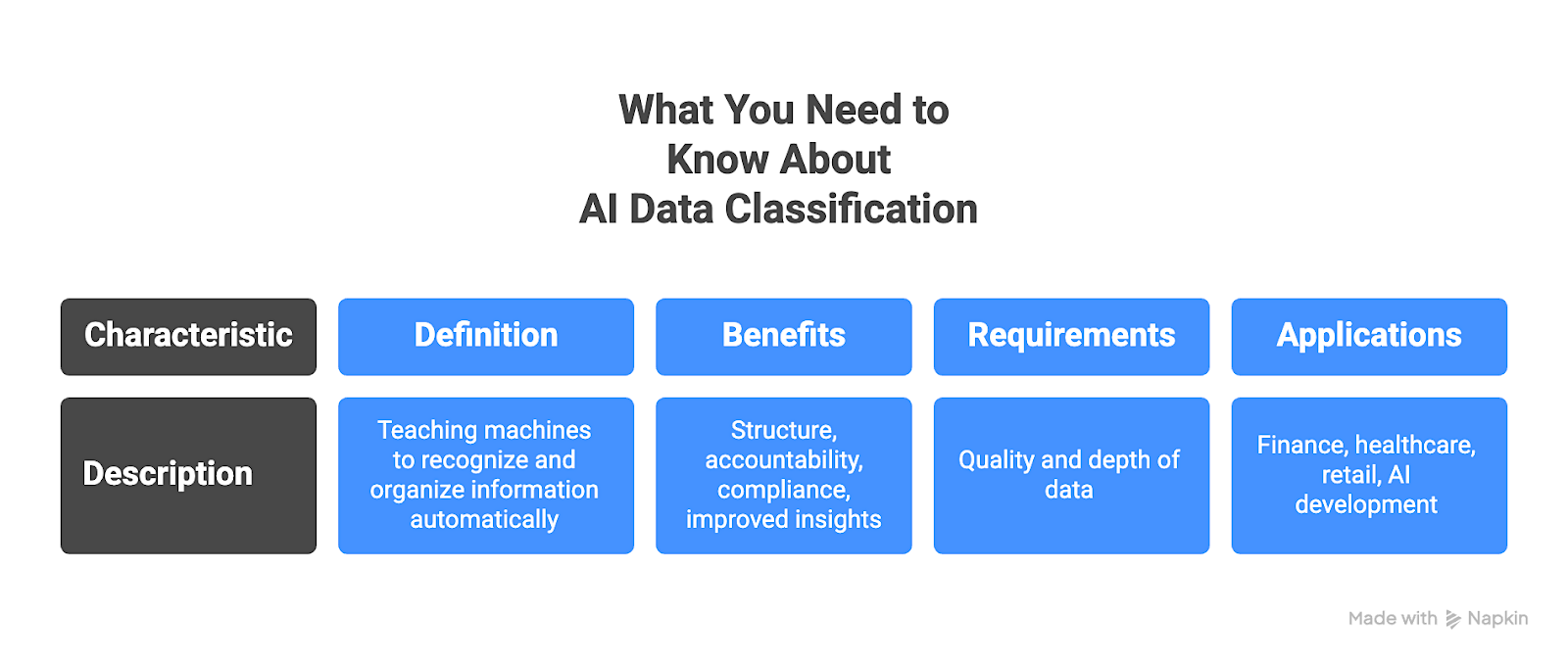
What is AI data classification?
AI data classification is the process of teaching machines to recognize and organize information automatically. It transforms raw, unstructured information into structured datasets that can be trusted for digital shelf analytics, compliance, and model training.
Machine learning models are trained on labeled examples, and learn to detect patterns in text, images, or other formats. Once trained, they can assign new data to specific categories at scale, and with speed and accuracy that manual tagging cannot match.
Effective AI data classification brings structure and accountability to how data is handled. It allows teams to identify sensitive information, apply appropriate access controls, and maintain consistent governance across systems. It helps keep data discoverable and governed across its lifecycle and supports compliance by aligning labels with policies, access controls, and retention rules. This precision improves both compliance and the quality of insights generated from analytics or AI workflows.
Industries such as finance, healthcare, retail, and AI development rely on this process to manage regulated or high-volume data responsibly. In these environments, accuracy and traceability are required for trust and operational continuity.
The strength of any classification system depends on the quality and depth of its data. Models trained on shallow or outdated samples quickly lose accuracy. Systems powered by continuously updated, structured data pipelines stay reliable even as data evolves.
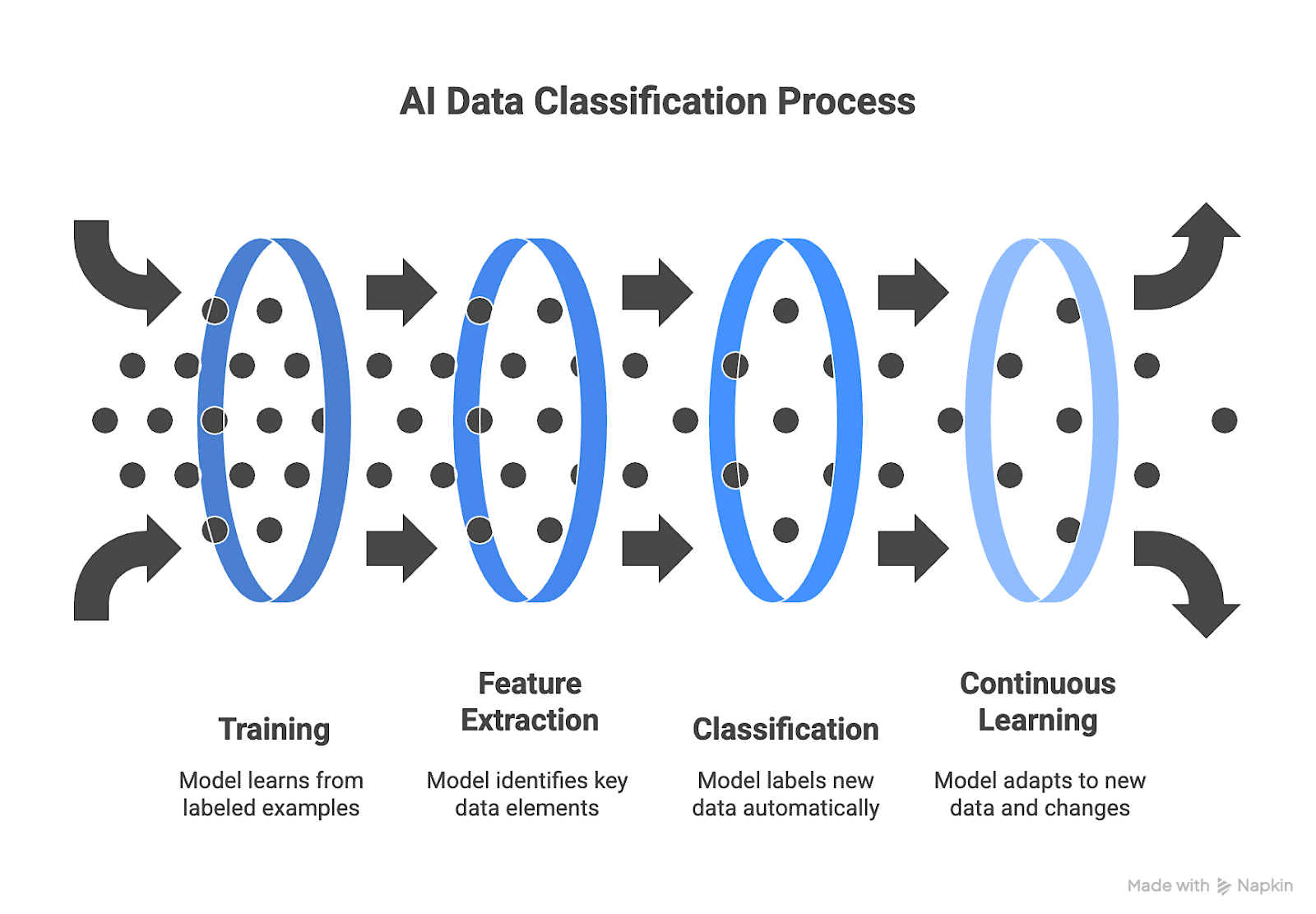
How AI Data Classification Works
While implementation details vary, most AI data classification systems follow four main stages that build on one another to create accuracy and scale:
1. Training
Classification begins with model training. Machine learning algorithms study labeled examples to learn which characteristics define each data category. A model may learn that numerical strings represent payment information, or that specific medical terms belong to health records.
The success of this stage depends on the quality and completeness of the data used. Models trained on limited datasets quickly lose accuracy; continuous retraining with diverse, up-to-date data ensures lasting precision. Systems powered by rich, continuously refreshed datasets perform better because they learn from real-world variability and maintain accuracy as data evolves.
2. Feature Extraction
Once trained, the model identifies which elements of new data carry meaning. This process, known as feature extraction, isolates the signals that distinguish one category from another. In text, this often involves tokenization, n-grams, and embeddings; in documents and web pages, metadata, layout cues, and DOM hierarchies provide structural signals.
Richer, more complete data helps the model detect relevant features and filter noise more effectively. For example, feature extraction can involve tokenizing text, analyzing metadata, or recognizing layout structure in web pages. Shallow or incomplete inputs reduce context and lead to misclassification, while deep, multi-layered data helps the system understand structure and relationships more accurately.
3. Classification
With features extracted, the model applies its learned patterns to label new data automatically. Classification becomes operational when it converts streams of unstructured inputs into organized outputs that can feed directly into analytics dashboards or AI pipelines. When the underlying data is validated and complete, classification results require less manual review and are immediately usable across teams and systems.
4. Continuous Learning
New product formats, terminology, and regulatory definitions emerge, and static models quickly lose accuracy. Continuous learning keeps systems aligned with these changes. Incorporating feedback, retraining on new examples, and validating performance over time allows models to maintain precision and reduce drift. Structured, real-time data pipelines make this possible by providing a steady flow of fresh, validated examples.
4 Types of AI Data Classification
AI data classification can be applied in several ways depending on the organization’s goals and the nature of its data. Each method defines how information is analyzed and labeled, and many systems combine multiple approaches to balance automation with control.
1. Content-Based Classification
This method examines the actual content of a file or record to determine its category. It analyzes text, images, or metadata to identify what the data contains. For example, a model might detect a credit card number in a form or recognize a product review within a document. Content-based systems perform best when trained on deep, well-labeled datasets that represent the full range of formats and sources the model will encounter.
2. Context-Based Classification
Context-based systems rely on information about where data comes from and how it is used. They consider factors such as file location, creator, access level, and usage patterns. A document created in a finance workspace or uploaded through a customer portal might be categorized as financial or customer data even if its content is unclear. This method depends on well-organized metadata and system-level visibility to maintain accuracy.
3. User-Defined Classification
User-defined classification systems allow administrators or domain experts to create labeling rules directly. These rules define sensitivity levels, business functions, or policy categories. It also helps organizations align automated classification with existing security or data governance frameworks without manual rework.
4. Hybrid Classification
Hybrid classification combines automated intelligence with human-defined rules. Machine learning models analyze the content and context of data to predict the correct category, while policy-based rules defined by governance teams apply additional structure and oversight. This approach scales efficiently without losing accuracy or control. Hybrid systems are most effective when supported by in-depth, multi-source data that reflects the diversity of real-world inputs and continuously updates to capture new patterns.

Benefits of AI Data Classification
AI data classification offers many benefits, including:
- Improved Security – Classification identifies and tracks sensitive data automatically, allowing organizations to apply the right controls and detect exposure quickly. It transforms data protection into an automated, always-on control layer.
- Simplifies Regulatory Compliance – Accurate labeling ensures that regulated information is handled according to privacy laws and internal governance policies. Automated classification streamlines audits and lowers compliance risk.
- Increased Efficiency – Automating data labeling removes manual overhead and minimizes errors. Teams spend less time cleaning and categorizing data, and more time applying it to generate insights and business value..
- More Consistent Data – Standardized categories keep information consistent across systems and business units. This consistency improves data quality and reliability throughout analytics and reporting pipelines.
- Analytics Readiness – Well-classified data is easier to search, integrate, and model. Consistent structure speeds up analysis and strengthens AI performance, while reducing the time to generate insights.
AI Data Classification Use Case Examples
Here are some common use cases of AI data classification across industries where large volumes of information must be leveraged:
Retail and CPG
AI data classification organizes product listings, pricing data, inventory updates, and customer reviews. It enables retailers to monitor category changes, pricing shifts, and consumer sentiment across multi-page catalogs and marketplaces.
Finance
Financial institutions classify transaction histories, payment data, and customer documentation. The process helps segregate sensitive information such as account identifiers and personal data from general business records.
AI and LLM Development
Automated labeling prepares datasets for LLM training and fine-tuning models by grouping text, images, and tabular records into defined categories. Continuous data updates keep training inputs representative of current conditions.
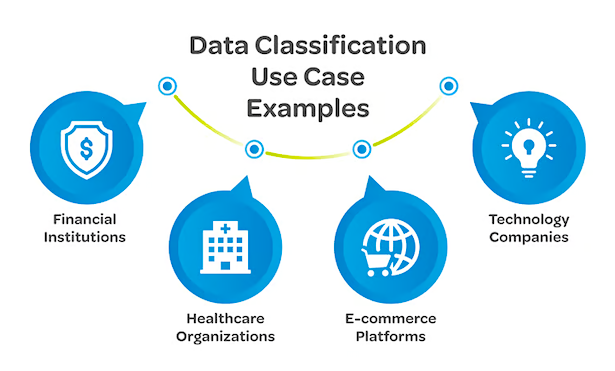
Marketing and Personalization
Marketing teams use AI models to classify customer and campaign data by behavior, engagement, and purchase history. Labeled datasets support precise segmentation and consistent cross-platform measurement..
Healthcare
Healthcare organizations use AI data classification to automatically detect and label protected health information (PHI) across clinical, research, and operational systems. Machine learning models analyze both text and visual data to identify sensitive content, helping teams enforce privacy controls and maintain HIPAA compliance at scale.
8 Best Practices for AI Data Classification
1. Define a Clear Data Taxonomy
A data taxonomy is the framework that defines how information is labeled, grouped, and prioritized within an organization. It provides the structure classification models use to interpret data consistently across repositories and workflows.
A well-designed taxonomy reduces ambiguity, and ensures sensitive or regulated information is tagged correctly. It also simplifies governance by aligning data categories with business functions and compliance requirements.
How to do it:
- Define standardized category names and hierarchies, and specify labeling criteria.
- Document them in a centralized schema that can be maintained over time.
- Collaborate with governance and engineering teams to keep taxonomy updates accurate and synchronized across systems.
2. Adopt Scalable Data Infrastructure with Nimble
AI data classification accuracy depends on a continuous flow of structured, real-time data. When inputs update slowly or inconsistently, models lose precision and governance gaps appear. Scalable infrastructure ensures that data is captured, cleaned, and validated in real-time so that data classification keeps pace with changing information.
How to do it:
- Use Nimble’s Web Search Agents to autonomously collect and structure web data at scale.
- The resulting data pipelines feed directly into enterprise systems as verified, compliant, and analysis-ready outputs.
- This architecture keeps classification stable and accurate.
3. Prioritize Sensitive and Regulated Data
Classification should begin with the information that carries the highest compliance and business risk. This includes personally identifiable data, financial transactions, medical records, intellectual property, and regulated data. Focusing on these sources first reduces exposure and creates a controlled foundation for classification across the organization.
How to do it:
- Start by mapping where sensitive data is stored and how it moves between systems.
- Identify which datasets are subject to specific laws or security requirements, such as GDPR, HIPAA, or PCI DSS.
- Apply classification to these areas early to confirm that access controls, retention rules, and protection policies function as intended before extending coverage to lower-risk data.
4. Validate and Clean Data at Ingestion
Every classification system depends on the quality of the data it receives. When errors or inconsistencies enter at ingestion, they distort labeling and weaken model reliability downstream. Continuous validation ensures that data arriving from different sources or API integrations meets defined standards before it’s used or stored. This approach preserves integrity across systems and keeps classification grounded in accurate, trusted data.
How to do it:
- Build validation directly into your pipelines to check structure and completeness as data is ingested.
- Flag anomalies early and correct them automatically where possible, reducing the need for manual cleanup later.
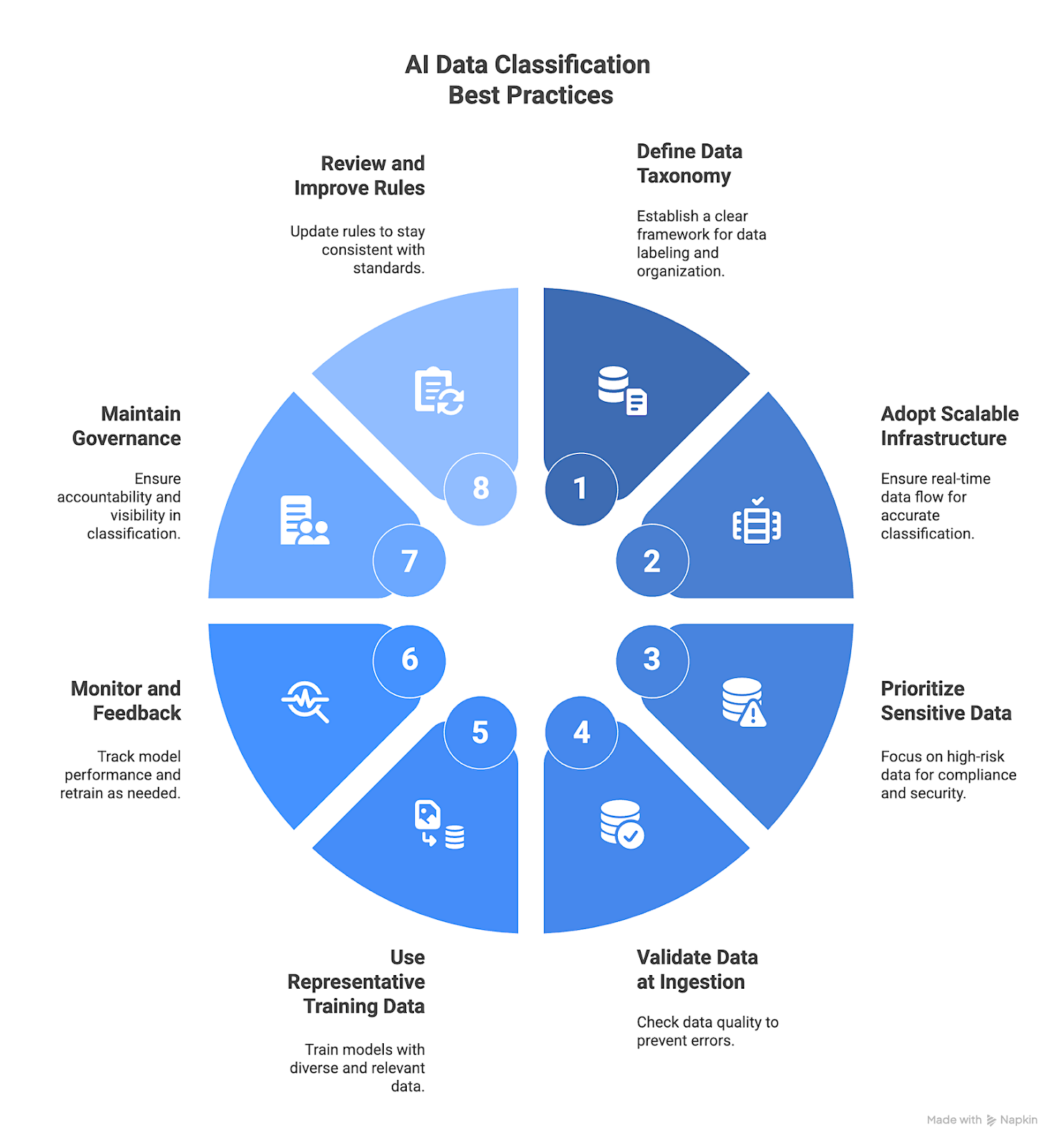
5. Use Representative Training Data
AI data classification stays accurate when models are trained on data that reflects real conditions. Narrow or outdated samples create gaps that lead to errors as new data appears. Training data should include full examples and preserve the context that exists in live systems. Representative data helps prevent bias and drift as models encounter new patterns, improving both training outcomes and downstream model inference accuracy.
How to do it:
- Build datasets that match the structure and variety of your operational data.
- Include enough depth to capture how information changes over time.
- Refresh the datasets regularly so models continue to learn from current inputs.
6. Automate Continuous Monitoring and Feedback
Classification models degrade over time as data and business conditions change. Continuous monitoring tracks how accurately models label new information and detects when retraining is needed. Without this feedback loop, small deviations accumulate and undermine the reliability of downstream analytics.
How to do it:
- To maintain accuracy, connect classification outputs to automated monitoring that flags shifts in data patterns or confidence scores.
- Review these signals regularly and feed validated results back into retraining cycles to keep models current with real-world conditions and prevent performance drift.
7. Maintain Governance and Auditability
Governance gives classification structure and accountability. Each decision, from how data is labeled to how policies change, should be easy to trace and verify. Auditability ensures that no part of the process operates without visibility or control.
How to do it:
- Record all classification activity, model and policy updates, access changes, and other governance events in a centralized system with version control.
- Limit who can change labeling rules or taxonomy definitions.
- Review these records on a fixed schedule to confirm that processes remain compliant and accurate.
8. Regularly Review and Improve Classification Rules
Classification systems operate in changing environments. As data pipelines expand and compliance requirements evolve, labeling rules can become outdated. Regular reviews ensure classification stays consistent with current data and governance standards.
How to do it:
- Run scheduled evaluations of recent classifications using a verified sample of labeled data.
- Identify where category assignments or confidence scores diverge from established definitions.
- Update the rules or retrain the model to correct those gaps.
- Document each revision to maintain a complete record of system changes over time.
Build Reliable AI Data Classification at Scale
Reliable AI data classification depends on data that is complete, current, and structured for how it’s used. Without that consistency, even robust AI models lose accuracy as information changes across sources and formats. Follow these eight best practices to establish the foundation for keeping AI data classification dependable in production.
Nimble delivers the data infrastructure that makes this possible. Its Web Search Agents collect live web data with full depth and structure it into verified data pipelines. They supply real-time, compliant, and analysis-ready information that AI data classification systems can trust. With continuously refreshed data, teams can maintain accuracy, reduce model drift, and meet governance requirements.
Connect with Nimble to see how real-time, production-ready data powers reliable AI data classification at scale.
FAQ
Answers to frequently asked questions


.png)

.png)
.avif)
.png)
.png)