What Is Model Inference? Definition, Examples, and Best Practices

Tom Shaked
.png)
What Is Model Inference? Definition, Examples, and Best Practices
Tom Shaked
Most popular articles

Get structured, reliable data for your stack.

Artificial intelligence (AI) now makes millions of choices every second that affect how we use the Internet. For example, it flags suspicious transactions, suggests products we might like, and even diagnoses medical conditions. Yet while everyone talks about training bigger models, the business impact of AI is decided at a different stage: model inference, which is when those models generate live predictions.
Model inference is the process of applying trained models to new data in real time so they can make decisions, predictions, or recommendations that affect people and operations. Inference is what users actually experience, even if it receives less attention than training. Most importantly for businesses, it’s the point where AI systems start delivering value.
As organizations move from experimentation to production, the need for reliable and efficient inference is expanding rapidly. Analysts estimate the global AI inference market at $91.4 billion in 2024, and it’s projected to grow to $255 billion by 2032. Understanding what inference is and how it works is essential for any business that wants AI to deliver measurable impact.
What is Model Inference?
Model inference happens when trained ML models meet new data and make predictions. Training learns patterns; inference applies them to unseen data under real-world performance requirements.
Think of it this way: training is like studying for a test, and inference is like taking the test. Models learn from examples from the past during training. During inference, they use what they know to solve problems they’ve never seen before.
Why does this distinction matter? Training and inference need completely different things:
- Training is computationally heavy but runs periodically, ranging from hours to months, depending on the application.
Inference must return answers in milliseconds for real-time systems or within minutes for batch workloads, often handling thousands to millions of requests per second in production.

For businesses, inference is where AI delivers results. It’s when recommendation engines serve customers, fraud detection systems protect transactions, and predictive maintenance prevents breakdowns. But inference is more than prediction. It is a production service with strict demands for speed, reliability, cost efficiency, and governance. Failures have a direct impact on customers, which makes managing inference a business priority.
How Model Inference Works
We can divide the process of inference into several steps. Understanding each part helps engineering teams balance performance, reliability, and cost.
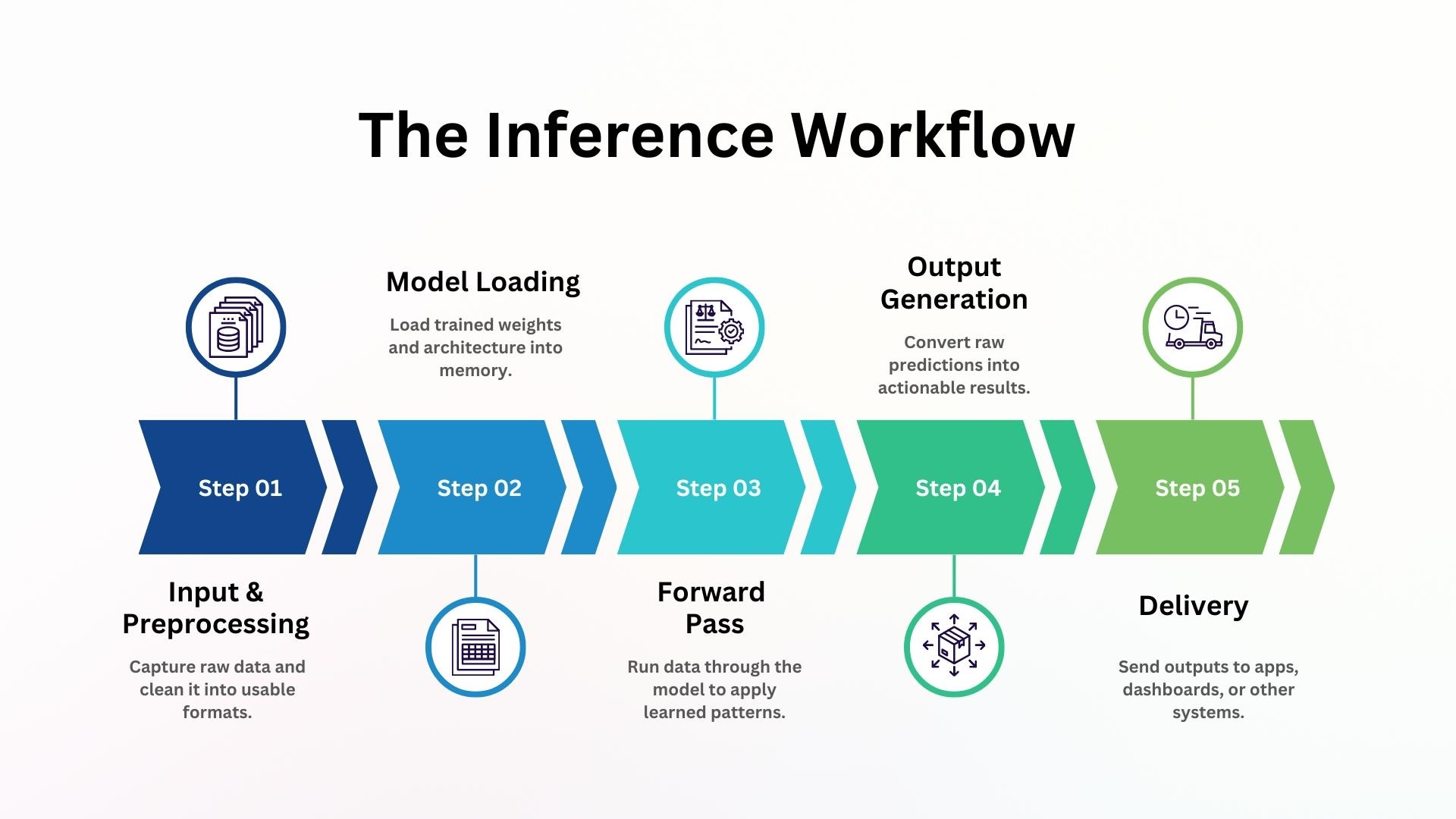
The Inference Workflow
Each inference workflow contains five steps:
- Input Capture and Preprocessing: The data is captured at the sources, and preprocessing is done to clean and format the unstructured, messy data.
- Model Loading: The trained weights and architecture are loaded into memory, typically during container or service startup for efficiency.
- Forward Pass: The data is passed forward through the model to apply learned patterns. This stage is the most compute-intensive, especially when serving thousands of concurrent requests.
- Output Generation: Raw predictions are transformed into usable formats.
- Delivery to Applications: Results are delivered wherever needed: user interfaces, databases, message queues, or other systems.
Runtime Environments
Inference runs within specific runtime environments that determine how quickly and efficiently predictions are generated. The choice of hardware shapes both performance and cost.
- CPUs are cost-effective for most workloads, especially when optimized frameworks are used.
- GPUs and TPUs offer high parallelism suited to high-throughput scenarios, such as serving complex models or large user volumes.
The environment you select determines how well the system can scale, how much each prediction costs, and how quickly it responds under load. Balancing these trade-offs is central to achieving stable, production-grade inference.
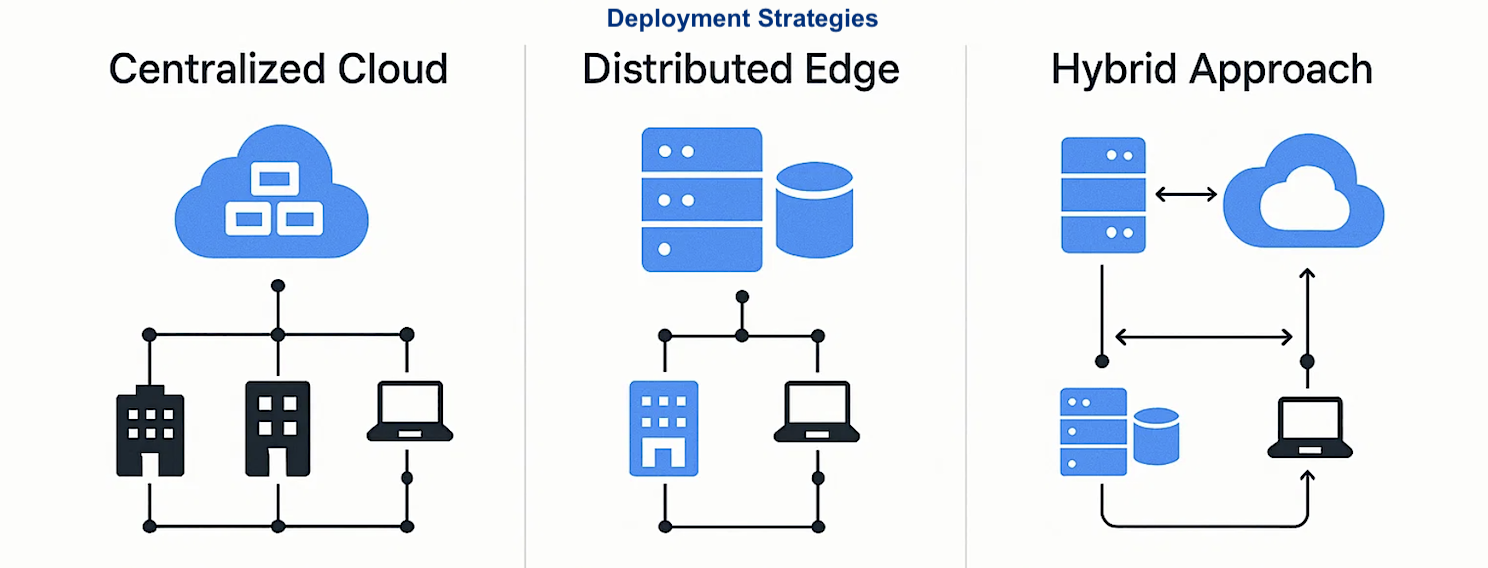
Deployment Strategies
Inference can be deployed in different ways depending on latency, scale, and compliance needs:
- Centralized Cloud: Offers elastic scaling and managed services but introduces network latency.
- Distributed Edge: Processes data on the spot for faster responses and greater privacy.
- Hybrid Approach: Combines both by routing urgent requests to edge nodes and operating batch jobs in the cloud.
Operational Factors
Managing inference in production requires controls that sustain performance as demand and data volume fluctuate. They determine how well the system adapts to changing workloads and maintains consistent output quality.
- Auto-scaling Policies: Specify explicit thresholds for when to increase capacity and when to scale down.
- Concurrency Management: Set limits to prevent resource exhaustion while maximizing throughput.
- Response Time SLAs: Different use cases require different speeds. For example, fraud detection might need responses under 100ms, while recommendation systems often target under 200ms.
- Cold Start Optimization: New instances need time to initialize. To reduce delays, pre-warm models, use smaller containers, or keep a small number of instances running.
Models are only as good as their data pipelines. Bad schemas, stale features, or dirty inputs can break inference regardless of model quality. It’s best to use reliable Web Search Agents and pipelines that stream fresh, fully structured external data, so inference services receive clean, validated inputs by default. This step prevents schema drift, maintains data freshness, and eliminates the need for brittle scrapers or manual data cleaning.
12 Examples of Model Inference in Action
Let’s examine how inference is applied across industries to solve operational problems and improve business outcomes:
Finance: Risk Decisions at Lightning Speed
- Transaction Monitoring: Banks analyze each card swipe in real time, comparing purchase behaviors, merchant reputation, and location anomalies to detect potential fraud and reduce losses.
- Instant Credit Decisions: Modern lenders use alternative data alongside credit histories to approve loans within minutes instead of days, improving customer experience and accelerating revenue.
- Market Surveillance: Trading systems scan millions of transactions daily to identify insider activity or market manipulation, strengthening compliance and trust.
Healthcare: Augmenting Medical Expertise
- Medical Imaging: AI analyzes X-rays, MRIs, and CT scans to identify cancers, fractures, or other anomalies with greater speed and consistency.
- Drug Discovery: Models screen large molecular datasets in silico to predict binding behaviors and flag promising candidates, reducing research timelines and cost.
- Diagnosis Support: Real-time analysis supports clinicians by differentiating potential diagnoses and recommending treatment options more accurately.
Retail: Personal Shopping at Scale
- Product Recommendations: AI inference engines deliver personalized suggestions based on browsing history, shopping cart content, and current demand trends.
- Dynamic Pricing: Retailers adjust prices in real-time for millions of SKUs according to demand, seasonality, and competitive changes to maximize revenue.
- Personalized Promotions: Customer data is analyzed to issue timely, relevant offers that increase engagement and conversion rates.
Manufacturing: Preventing Problems Before They Happen
- Predictive Maintenance: Sensor data identifies wear patterns days or weeks before equipment failure, reducing downtime and maintenance costs.
- Production Optimization: Models monitor quality data and adjust production parameters automatically to improve efficiency and yield.
- Autonomous Operations: Robots and industrial vehicles rely on continuous inference for navigation, process control, and safety assurance.
Across these domains, inference enables organizations to act on real-time insight, reduce operational risk, and sustain consistent performance at scale. Understanding how these systems function lays the groundwork for effectively applying the best practices for model inference.
10 Best Practices for Model Inference
1. Start with Clear Business Goals
Inference delivers the most value when it supports specific business outcomes. Each model should have a defined purpose that links predictions to measurable results. Setting these goals early keeps engineering and business teams aligned and ensures performance targets stay relevant as conditions change.
Best Practices:
- Link each prediction to a business decision or process.
- Define measurable outcomes such as conversion lift or fraud loss reduction.
- Align technical and business stakeholders on success criteria before deployment.
- Revisit goals regularly to reflect changing priorities.
2. Choose the Appropriate Metrics and Targets
Once goals are defined, teams need metrics that track both system performance and business impact. Technical metrics show how well the model runs in production, while business metrics reveal whether it’s creating value. Establishing clear targets keeps teams accountable and helps spot problems early.
Best Practices:
- Define metrics that measure accuracy, latency, throughput, and availability.
- Track business results such as cost per prediction or false-positive reduction.
- Set service-level objectives for each metric based on the importance of the application.
- Monitor results by region, workload, and model version to detect regressions early.
3. Select the Right Deployment Environment
The deployment environment determines how inference workloads run in production. Choosing where and how to deploy models—whether in the cloud, at the edge, or through a hybrid setup—affects latency, cost, and compliance. Planning this early ensures inference services operate efficiently and scale smoothly as demand grows.
Best Practices:
- Evaluate latency and bandwidth requirements before choosing an environment.
- Use cloud infrastructure for flexibility and scaling, and edge locations when real-time response is critical.
- Document routing rules, failover logic, and recovery procedures clearly.
- Test deployment configurations across regions to confirm performance consistency.
4. Shrink Models Without Sacrificing Quality
Inference costs rise quickly when models are too large or computationally intensive. Optimizing model size and performance reduces hardware demand while maintaining accuracy. Efficiency improvements also shorten response times and help systems scale under load.
Best Practices:
- Apply techniques such as quantization, pruning, and distillation to reduce model size.
- Benchmark each optimized version against production workloads to confirm accuracy.
- Use version control so teams can roll back if optimizations introduce regressions.
- Reevaluate performance regularly as data and infrastructure evolve.
5. Keep Data Pipelines Clean and Resilient
Inference models rely on consistent, well-structured data to perform accurately. When inputs become inconsistent or outdated, even strong models produce unreliable predictions. Maintaining clean, automated data pipelines keeps inference stable and prevents minor issues from cascading into system-wide failures.
Best Practices:
- Automate processes of ingesting data, checking schemas, setting SLAs, and detecting drift.
- Treat pipelines as first-class production systems with clear ownership and error budgets.
- Use Nimble’s Web Search Agents to stream fully structured, real-time data and eliminate brittle scrapers and manual collection.

6. Make Predictions Accessible
Inference outputs only create value when they flow directly into the systems where decisions are made. If results remain isolated from business workflows, they lose context and can’t inform action. Connecting inference outputs to enterprise tools ensures insights are applied consistently across teams.
Best Practices:
- Deliver inference results in structured, analysis-ready formats that integrate directly into BI dashboards, data lakes, and AI workflows.
- Support both real-time and batch delivery through standardized APIs based on application needs.
- Include confidence scores and, when possible, explanations alongside predictions.
- Develop role-specific dashboards that present metrics relevant to each user group.
- Enable human review for high-impact or regulated decisions.
7. Monitor Inference Continuously
Continuous monitoring ensures inference systems stay accurate and responsive after deployment. Tracking latency, throughput, and prediction quality helps teams detect drift, performance degradation, or failures early. Keeping monitoring data fresh allows teams to see how models perform under current, real-world conditions.
Best Practices:
- Monitor request patterns, latency, throughput, and confidence scores in real-time.
- Track infrastructure resource utilization to prevent overload and maintain stability.
- Configure alerts tied to service-level objectives so teams can respond quickly to anomalies.
- Use Nimble’s continuous, compliant web-data streams to keep monitoring signals current as market conditions change.
8. Automate Retraining and Rollout
Model performance declines as data and behavior change over time. Regular retraining keeps predictions accurate and aligned with current patterns. Automating this process helps teams respond quickly to drift without disrupting production systems.
Best Practices:
- Schedule retraining based on drift indicators, seasonality, or changes in user behavior.
- Test AI code and versions with shadow models, canary deployments, or A/B evaluations before release.
- Use Nimble’s fresh, compliant web data to ensure new training cycles reflect real-world conditions and reduce model bias.
9. Scale Smart and Manage Costs
Inference workloads grow quickly as usage expands, and unplanned scaling can drive costs out of control. Balancing performance with resource efficiency ensures systems remain fast and financially sustainable. Effective scaling strategies allow organizations to serve growing demand without overspending.
Best Practices:
- Profile workloads to understand actual compute and memory consumption.
- Batch inference requests when possible to lower operational overhead.
- Use cost-efficient infrastructure, such as spot or reserved instances, for noncritical workloads.
- Apply cascaded inference so simpler models handle routine cases and complex models focus on harder ones.
- Cache frequent predictions and use admission controls to maintain stability during traffic spikes.
10. Maintain Governance and Traceability
Every inference output should be auditable and reproducible. Governance practices make it possible to trace each decision back to its data, model version, and configuration, ensuring accountability and compliance. Maintaining this visibility builds trust and simplifies post-deployment reviews.
Best Practices:
- Version all models, datasets, and configurations for full reproducibility.
- Log predictions with identifiers that connect inputs, models, and outcomes.
- Retain metadata and access records to support audits and error analysis.
- Establish approval workflows before deploying updated models.
- Document model limitations, known risks, and appropriate use cases.
- Use provenance tracking systems that record the lineage of external inputs, ensuring audit-ready inference pipelines.
Reliable Data Powers Accurate Inference
Model inference fills in the space between what AI can do and what it can do for businesses. Training looks for patterns, and inference uses those patterns to stop fraud, make experiences more personal, and improve operations. To get there, organizations need more than fast models. They need reliable data flowing into those systems, every single time.
Nimble turns the live web into structured, compliant streams your agents can trust, keeping features fresh, schemas stable, and inputs low-latency. With real-time data delivered at scale, your model inference stays fast, reliable, and cost-efficient in production. Connect with us to learn more!
FAQ
Answers to frequently asked questions
.png)
.avif)
.png)
.png)
.png)
.png)