Top 10 Data Extraction Tools by Category

Nimble's Expert
.png)
Top 10 Data Extraction Tools by Category
Nimble's Expert
Most popular articles

Get structured, reliable data for your stack.
Data chaos is strangling business decisions. While competitors race ahead with real-time insights, teams in traditional companies are stuck copying information from PDFs and wrestling with APIs that break without warning. Hours turn into days, and by the time the data’s ready, the insights are already stale. But what can organizations do to keep from drowning in an ocean of data?
Recent research shows that 87% of enterprise information consists of unstructured data, and there’s simply no way to glean value from this data until it is parsed and structured. As organizations accelerate AI and real-time analytics initiatives, turning raw data into structured formats has become mission-critical. Fortunately, data extraction tools offer a life preserver to overwhelmed teams by automating data collection, parsing, and structuring.
By removing these manual barriers, teams can finally work with data that’s current, clean, and analysis-ready. Let’s explore the top ten data extraction tools across four categories to help you find a platform that delivers the speed, scale, and accuracy your data strategy demands.
What are data extraction tools?
Data extraction tools are automated solutions that retrieve raw data from sources like databases, websites, APIs, and documents, then convert it into a centralized, usable format for storage and analysis. These tools form the foundation for modern data pipelines, analytics, and AI workflows, and also automate the initial ‘Extract’ stage of the Extract, Transform, Load (ETL) or ELT pipeline.
Tools like these have immense benefits to:
- Data analysts and scientists who need clean, reliable inputs for their models and reports.
- Data engineers who build and maintain scalable data pipelines that depend on consistent, structured inputs.
- Business intelligence (BI) teams that rely on extracted data for dashboards that drive decisions.
- Growth and marketing teams that use extraction for competitive analysis and lead generation.
Across roles, each of these teams depends on consistent, automated access to accurate and analysis-ready data.
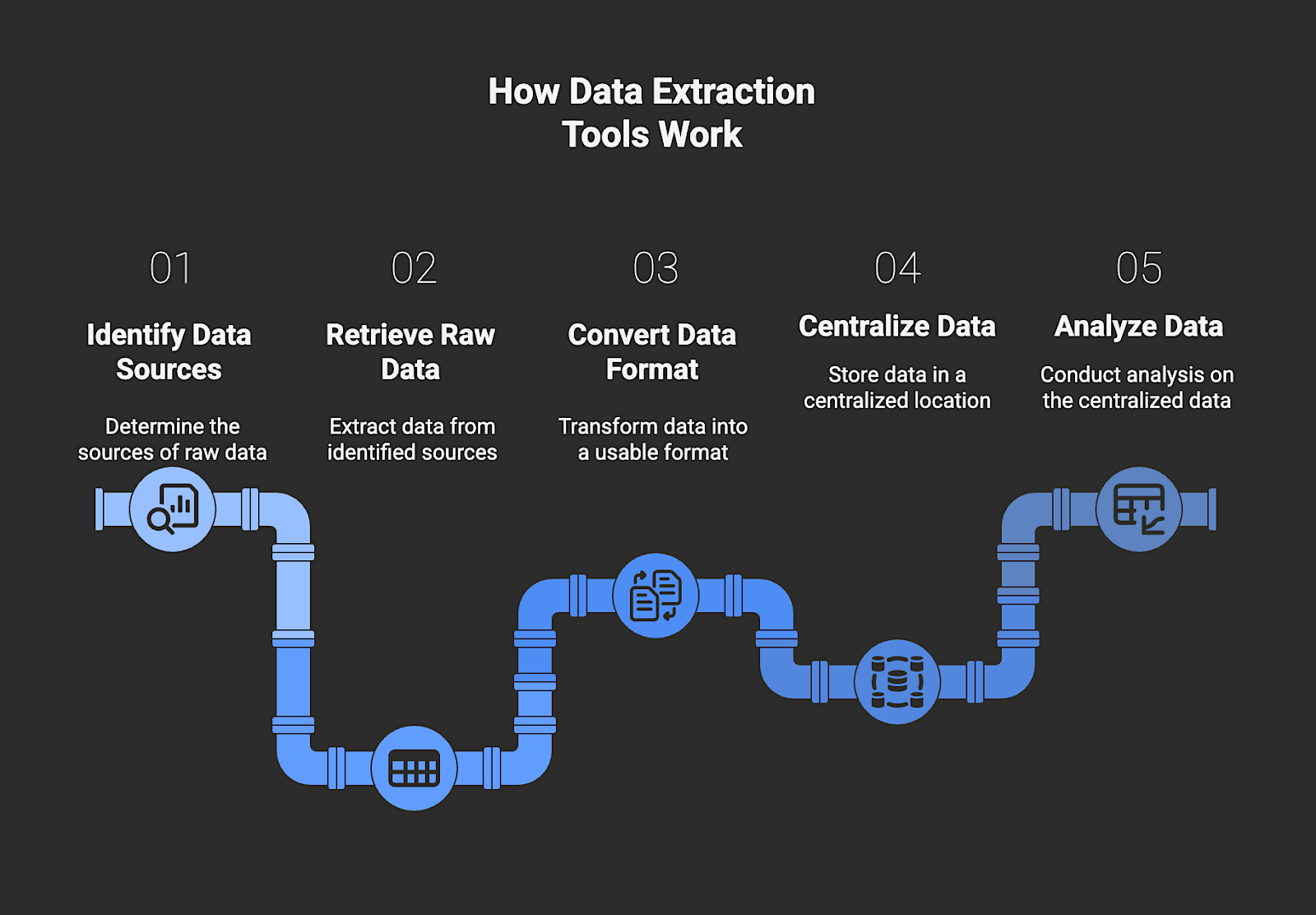
Types of Data Extraction Tools
Here are the four primary types of data extraction tools, each designed for different types of data and use cases:
Web Scraping Tools (Web Data APIs & Infrastructure)
Web scraping tools are specialized platforms that extract public data from websites by parsing HTML, often through visual interfaces or APIs. They’re widely used for market research, lead generation, and tracking public news or reviews. These platforms handle pagination, manage proxy rotation to avoid blocking, and process dynamic content like JavaScript-heavy pages, giving teams dependable access to current web data.
ETL/ELT Integration Platforms (API & database)
ETL and ELT platforms move large volumes of data between systems on a continuous basis. They connect to internal databases and SaaS applications such as Salesforce to build pipelines that feed data warehouses. The best platforms handle API authentication, manage schema changes automatically, and use Change Data Capture (CDC) so only new or updated records are processed.
Intelligent Document Processing (IDP) / OCR tools
These data extraction tools use AI to extract information from unstructured or semi-structured sources like forms, contracts, and PDFs. They recognize both text and context through Key-Value Pair extraction rather than fixed templates, automating workflows in areas such as accounts payable, contract review, and claims handling.
Open Source Data Solutions (OSS)
Open-source data solutions are community-built frameworks that give engineering teams complete control over their extraction logic. They provide the foundations for workflow orchestration and data streaming, making them a strong fit for organizations with unique data requirements or large-scale integration needs.
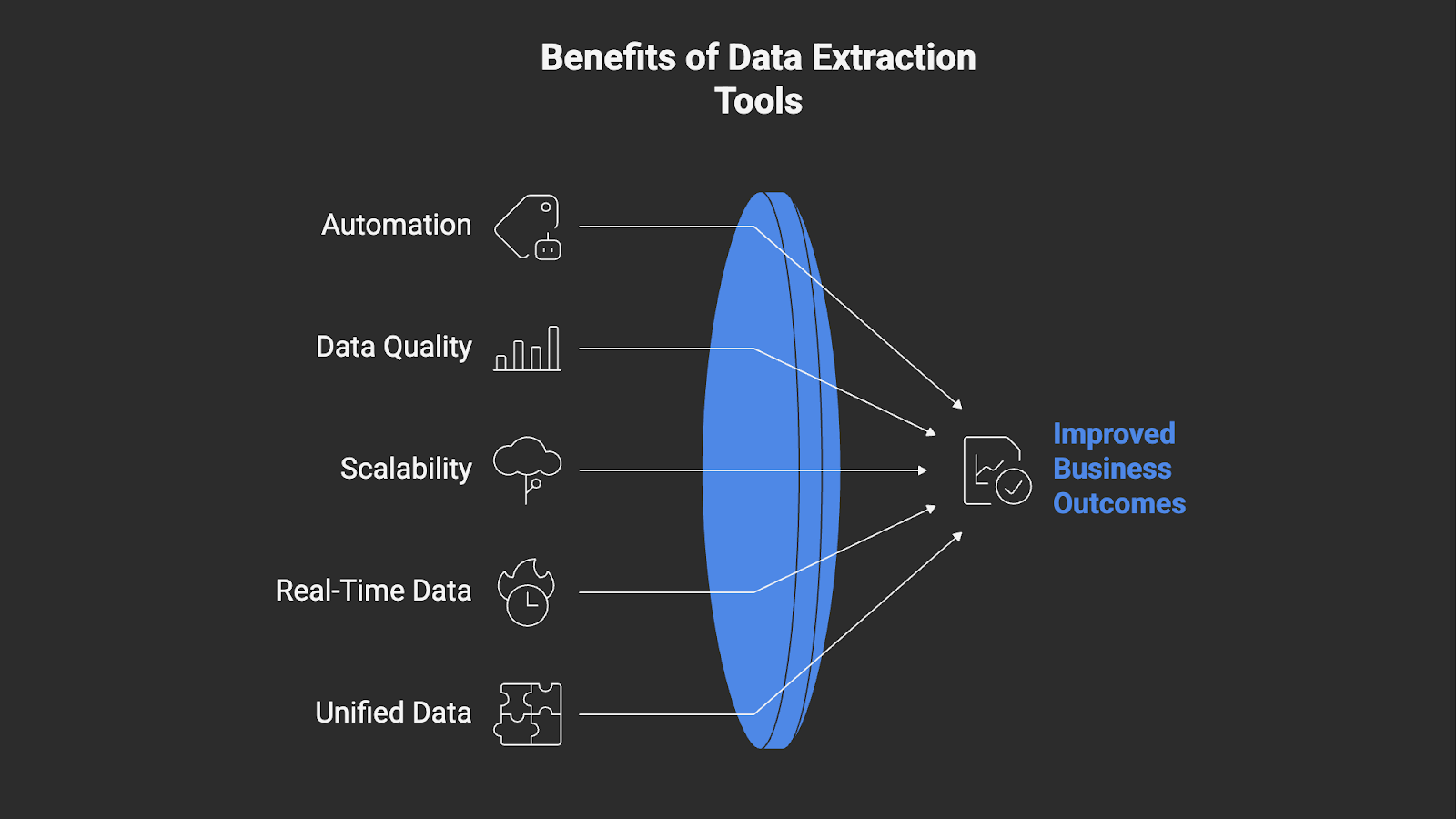
Benefits of Data Extraction Tools
Data extraction tools offer many advantages, including:
- Automating manual data workflows – Automation replaces repetitive copy-paste tasks and manual data collection with scheduled or continuous data pipelines. It allows your teams to focus on analysis and strategy instead of maintaining fragile scripts.
- Ensuring clean, trusted data at scale – Built-in validation, deduplication, and quality checks maintain data accuracy and consistency, while automated monitoring and error handling preserve trust across every source. These systems sustain that reliability even as datasets grow, ensuring teams work with analysis-ready information.
- Scaling efficiently without extra engineering load – Data extraction tools adapt to new sources and higher volumes without additional engineering staff or infrastructure management, allowing teams to grow operations while keeping complexity low.
- Making faster decisions with real-time data – Continuous delivery of real-time structured data provides live insights as information becomes available, helping organizations act quickly instead of relying on outdated reports.
- Unifies data sources for a single source of truth – Consolidating data from multiple internal and external systems into one governed repository creates a consistent company-wide view, which improves collaboration and confidence in decision-making.
Key Features to Look for in Data Extraction Tools
Here’s what to look for when choosing data extraction tools for your organization:
Data Source Compatibility
Choose tools that connect directly to the systems your business already uses, such as databases, APIs, websites, and document repositories. Broad connectivity lets teams extract information from multiple sources through a single platform, reducing the need for custom code or manual setup.
Change Data Capture (CDC) and Incremental Loading
Select platforms that capture only new or modified records instead of reprocessing entire datasets. This approach keeps data current, shortens sync times, and lowers processing costs while maintaining accuracy across all sources.
Built-in Data Validation and Quality Control
Look for solutions that automatically check incoming data for completeness and accuracy before it enters storage or analytics systems. Validation at the field and format level prevents unreliable data from reaching dashboards or machine-learning models.
Scalability and Performance Optimization
High-end data extraction tools should handle growing data volumes and additional sources without manual reconfiguration. Built-in scaling and load balancing allow teams to maintain performance as workloads expand.
Structured Outputs and Integration Formats
Reliable tools deliver data in structured, standardized formats so it can be used immediately in data warehouses or analytics tools. Consistent formatting eliminates extra transformation work after extraction.
Security and Compliance Features
Robust data extraction tools must provide role-based access control, data encryption, and compliance with regulations like SOC-2, HIPAA, and GDPR to protect sensitive information.
User-friendly, Low-code Capabilities
An intuitive interface lets analysts and business users build or modify extraction workflows without writing complex code. It improves agility and reduces reliance on engineering resources for routine updates.
Top 10 Data Extraction Tools
Web Scraping Tools
1. Best for Real-time Web Data at Scale: Nimble
Nimble is a data extraction solution designed for teams that need real-time, structured web data at scale. It operates as web data infrastructure rather than a basic scraper, using autonomous Web Search Agents that browse, render, and extract data from public websites.
Web Search Agents adapt automatically when site structures change and deliver validated, analysis-ready outputs through APIs or pipelines. Automating the entire extraction process gives organizations a continuous flow of current, compliant web data that scales effortlessly with demand.
Key features:
- Global residential IP network with built-in rotation and session management
- Real-time data delivery through APIs and online pipelines
- Integrated validation layer for accuracy and completeness
- Central dashboard for performance analytics and resource controls
- High-concurrency support for large-scale data operations
- GDPR and CCPA-aligned collection of only public information
Review: “Nimble’s data platform met our massive data needs out of the box, feeding our large language models with relevant, high-quality data. This scalability has been crucial in developing more robust and reliable AI systems.”
ETL/ELT Integration Platforms
2. Best for Automated ELT Integration: Fivetran
Fivetran automates the entire ELT process, handling connector management and schema updates while maintaining reliable pipelines with minimal engineering effort. Its zero-maintenance design allows teams to centralize and prepare data without building or maintaining custom integrations.
Key features:
- 500+ prebuilt connectors for SaaS and database sources
- Real-time change data capture for continuous updates
- Built-in data transformation and orchestration tools
- Automated schema management and version control
- Enterprise security and compliance certifications
Review: “Great set-it-and-forget-it solution for ELT workloads.”
3. Best for Open Source Flexibility: AirByte
Airbyte is an open-source alternative to proprietary ELT platforms that gives teams control over how they move and manage data. Its architecture allows full customization of pipelines and benefits from ongoing community contributions and development.
Key features:
- Open-source platform with more than 300 connectors
- Connector Development Kit (CDK) for custom integrations
- Supports self-hosted and managed cloud deployments
- Docker-based design for scaling and portability
- Active community with frequent updates and new connectors
Review: “It is very customizable, (and) other no-code, low-code ETL tools do not offer such flexibility.”
4. Best for Data Sync: HevoData
Hevo Data provides automated integration for teams that need real-time movement between sources and destinations without heavy engineering. Continuous replication keeps data current, making it practical for analysts and non-technical users who manage operational pipelines.
Key features:
- No-code data integration with 150+ source connectors
- Real-time data replication and streaming
- Pre-built transformations and custom Python support
- Auto-schema detection and mapping
- Built-in data quality monitoring and alerts
Review: “A very affordable option for cross-platform ETL.”
Intelligent Document Processing (IDP) / OCR Tools
5. Best for Enterprise Automation: UiPath

UiPath combines robotic process automation (RPA) and AI to automate document-heavy workflows. It classifies and extracts information from a wide range of documents, then connects to RPA systems for process automation at scale.
Key features:
- Document Understanding with multiple OCR engines
- Supports 200+ languages, including CJK
- AI-based document classification and field extraction
- Integrates with RPA workflows for full automation
- Available for on-premises or cloud deployment
Review: “The most helpful part of it was its ability to extract data from various documents.”
6. Best for AI-driven OCR: Nanonets
Nanonets also uses AI technology to solve complex document processing challenges with a recently released 3B parameter OCR model. It’s a solid choice for organizations that process a variety of document types but maintain a high threshold for accuracy.
Main features:
- Custom machine learning models for specific document types
- Recently released Nanonets-OCR-s (3B parameter model)
- Advanced features: LaTeX equations, signature detection, watermark extraction
- API access for custom integrations
- Supports 30+ million documents processed annually
Review: “Nanonets played a pivotal role in AP automation at Asian Paints. Document extraction was key to the overall automation.”
7. Best for Invoice Processing: Rossum
Rossum automates the entire invoice and document workflow, from receipt to Enterprise Resource Planning (ERP) system integration. It combines data extraction with process orchestration, allowing mid-market and enterprise organizations to manage document validation and approval within a single platform.
Key features:
- End-to-end document automation platform
- Custom business rules and workflow management
- Master data matching and duplicate detection
- AI-based data capture that improves through user feedback
- Configurable dashboards for tracking accuracy and throughput
Review: “The AI feature that adapts to each individual PDF is impressive, as it means that with every new document, less human intervention is needed over time.”
Open Source Data Solutions
8. Best Python Web Scraping Framework: Scrapy
Scrapy is an open-source Python framework for building fast, scalable crawlers. It runs asynchronously on Twisted and supports distributed workloads for handling large-scale extraction. A modular design makes it easy to extend and adapt for complex crawling projects.
Key features:
- Build spiders in Python and tailor them to any site or data model.
- Asynchronous and concurrent request processing
- Built-in support for handling forms, cookies, and session management
- Extensive middleware system for customization
- Active open-source community and detailed documentation
Review: “Scrapy transforms complex web extraction tasks into swift, streamlined operations that save time and maximize output.”
9. Best for JavaScript-heavy Sites: Puppeteer

Puppeteer is a Node.js library that automates Chrome and Chromium through the DevTools Protocol to extract data from JavaScript-rendered websites. It gives developers precise control over browser behavior and enables interaction with dynamic pages that traditional scrapers can’t access.
Key features:
- Programmatic control of browser actions through the DevTools Protocol
- Full JavaScript execution and DOM manipulation support
- Built-in emulation for devices, viewports, and user agents
- Network interception for request modification or blocking
- Screenshot, PDF, and HTML capture for content validation
Review: “(Puppeteer’s) documentation is extensive, with clear examples and a well-organized API reference.”
10. Best for Cross-browser Automation: Playwright
Playwright automates browser actions across Chromium, Firefox, and WebKit. It gives teams a single framework for testing and scraping dynamic websites. An auto-wait mechanism detects when elements are ready before interaction, which removes manual delays and improves reliability across browsers.
Key features:
- Device emulation for mobile and tablet testing
- Network interception and request mocking
- Headless or full-browser operation modes
- Parallel test execution across multiple contexts
- Multi-language support (JavaScript, Python, Java, C#)
Review: “Playwright offers a powerful and versatile toolkit for web scraping tasks with excellent documentation and a growing community.”
Turn Web Data into a Strategic Advantage
Data extraction tools have become essential for organizations that rely on accurate, current information. They simplify how teams collect and prepare data, turning what was once a manual process into a reliable part of daily operations. With the right tools, data can move quickly from source to insight.
Nimble gives teams a dependable way to extract structured web data at scale. Its Web Search Agents automate the process, keeping data accurate even as websites change. Using Nimble reduces engineering overhead, improves consistency, and shortens the time between data collection and decision-making.
Try a Nimble demo today to see how it turns web data extraction into a strategic advantage.
FAQ
Answers to frequently asked questions


.avif)

.png)
.avif)
.png)
