7 Firecrawl Alternatives by Use Case

Charlie Klein
.png)
7 Firecrawl Alternatives by Use Case
Charlie Klein
Most popular articles
Get structured, reliable data for your stack.
With more AI agents moving into production and those agents requiring even more high-quality data, AI web scraping and content extraction tools are having a moment. But selecting the right one is critical, because it directly impacts what your AI agents can do with the data they retrieve: how accurately they reason, how much post-processing your pipeline requires, and whether your system holds up under production load.
The web scraping market is projected to rise from $1.16 billion in 2026 to $2.23 billion in 2031, buoyed by the 2026 shift from brittle, selector-based scraping and raw HTML/markdown dumps to AI-driven, self-healing extraction that delivers structured, agent-ready data directly into RAG pipelines and agent workflows. Many developers started with Firecrawl for content extraction, but are coming up against bottlenecks around output structure and analysis-readiness, reliability on JavaScript-heavy or bot-protected sites, and scalability for production data.
That’s why we put together this guide that compares seven AI web scraping and content extraction tools. Choosing the right one is an architectural decision that determines how your system handles live web data under a production load. Tools like Nimble, Apify, and Bright Data solve the specific structural and access bottlenecks that basic scrapers leave behind. Here, we evaluate seven Firecrawl alternatives based on buyer priorities like extraction depth, reliability, and AI compatibility to help you find the layer that actually fits your use case.
What is Firecrawl?
Firecrawl is a developer-focused web scraping and content extraction API for AI workflows. It occupies a specific niche in the AI agent infrastructure stack: turning web pages into clean, LLM-ready data without requiring teams to build and maintain their own scraping pipeline.
The process is straightforward: you feed Firecrawl a URL, and it hands back cleaned Markdown or semi-structured JSON. It’s essentially a shortcut for getting web data straight into your retrieval systems without the usual mess.
This approach is vital for RAG and knowledge base development. Firecrawl handles browser-level work like JavaScript rendering and pagination automatically, reducing the selector maintenance that often plagues custom scrapers. Instead of parsing the DOM, you get structured content that is much easier to chunk, embed, and index for your agents.

For teams needing to deploy prototypes right now, Firecrawl collapses the extraction pipeline into a single step that gets readable content into your pipeline as fast as possible. For text-heavy workflows, the reduction in engineering overhead is significant, allowing you to focus on the AI logic rather than the scraping infrastructure.
When Firecrawl May Not Be the Right Fit
Teams usually start looking beyond Firecrawl when their use case requires more structured outputs, more predictable production economics, or a more managed data delivery model. Typical issues include:
Structured Data at Scale
Firecrawl does offer a JSON mode via its /scrape endpoint that lets you pass a schema and get structured data back from a single URL that is useful for one-off extractions or prototyping. The problem surfaces when you need that same structured output across thousands of pages. At that point, single-URL JSON mode isn't a viable path, and the tool that is designed for scaled structured extraction is the /agent endpoint, which operates at 5 credits per action rather than 1 credit per page.
For pipelines that need schema-defined data across large page volumes, that cost multiplier makes production economics difficult to predict and hard to justify. Teams that start with Firecrawl's JSON mode for structured extraction often hit this ceiling quickly once they move beyond prototyping into production-scale workflows.
Cost Predictability
Credit-based pricing is standard across the web scraping space, so the model itself isn't the issue. What matters is how credits are consumed relative to your actual workflow. Those multipliers compound quickly at production volume: a combined crawl-and-extract workflow runs to 7 credits per page, meaning a 500-page site can exceed an entire Hobby plan allowance in a single job.
Unused credits don't roll over, and there's no pay-as-you-go option, so teams that hit a crawl-and-extract workload will burn through a tier faster than the headline credit count suggests before facing a significant price jump to the next plan.
JavaScript Rendering and Bot Protection
Firecrawl's success rate drops on sites with aggressive bot protection or advanced anti-scraping measures. Its Enhanced Mode addresses this, but it is a separate, higher-cost option rather than a default capability. Teams scraping heavily protected domains will encounter failure rates that require retry logic or additional tooling, adding engineering overhead that the API is otherwise designed to eliminate.
Data Delivery
Finally, while Firecrawl is built for extraction, it isn't designed to be a managed delivery service. This limitation is fine for some use cases, but teams requiring SLAs and high-level monitoring will find it limiting. When reliability is non-negotiable, you need a platform that manages the entire lifecycle of your web data as an end-to-end delivery pipeline.
Key Terms
In 2026, evaluating Firecrawl alternatives means focusing on the technical criteria that determine whether a tool can move beyond basic content extraction into reliable AI web scraping for RAG pipelines and agent workflows. Key terms to know include:
- Extraction Depth: Extraction depth varies wildly between tools. Some basic scrapers only pull visible text from the surface of a page. More advanced platforms go much deeper, mapping nested data into specific schemas even when the layout is complex.
- Output Structure: Refers to the format and usability of returned data, ranging from raw HTML to Markdown to fully structured JSON that can be used directly in downstream systems without additional transformation.
- Reliability on Complex or Protected Sites: Tracks how well a tool maintains performance across JavaScript-heavy, dynamically rendered, or bot-protected sites.
- AI Agent and RAG Compatibility: How easily the extracted data fits into agent frameworks and retrieval pipelines without additional transformation.
- Ease of Integration: Whether the tool offers SDKs, framework support, documentation, and API design that help engineering teams move from setup to production with less implementation friction.
Top Firecrawl Alternatives by Use Case
- Recommended for production AI agents requiring real-time, structured web data at enterprise scale: Nimble
- Recommended for managed scraping with pre-built actors for specific platforms: Apify
- Recommended for enterprise proxy infrastructure and pre-built dataset delivery: Bright Data
- Recommended for self-hosted, LLM-optimized crawling with full pipeline control: Crawl4AI
- Recommended for structured entity extraction and knowledge graph enrichment: Diffbot
- Recommended for lightweight, zero-setup URL-to-Markdown conversion: Jina Reader
- Recommended for reliable HTML rendering on bot-protected sites: ScrapingBee
Comparison Table: Best Firecrawl Alternatives Compared
Selecting the right Firecrawl alternative depends on how your extraction layer needs to perform in production. For AI web scraping and content extraction, the correct choice comes down to structure, extraction depth, site access, RAG compatibility, and implementation effort. The table below compares seven tools across those dimensions for AI engineers building production agent workflows.
How We Compared These Tools
We compared these Firecrawl alternatives against a common technical baseline to ensure the comparisons are actually useful for buyers and AI engineers. The data is current as of 28 April 2026, and comes from official sources and third-party user reports.
What we reviewed:
- Official Sites: We looked at how each vendor actually positions itself in the RAG space and what they claim to solve.
- Technical Docs: We reviewed available documentation, API pages, and feature descriptions related to extraction, rendering, structured outputs, and integration.
- Pricing & Plans: We reviewed public pricing pages and plan details where available.
- Competitor Comparisons: We analyzed the vendors' own "Us vs. Them" pages to see where they claim to beat Firecrawl.
- Developer Feedback: We reviewed selected third-party reviews and software directories where relevant.
How we compared tools:
We looked at extraction quality, web access, output structure, and production fit. Our focus was on whether each tool can support RAG pipelines and agentic workflows with usable outputs, reliable access to complex or protected sites, and a practical path from evaluation to production.
7 Firecrawl Alternatives by Use Case
Requirements for AI web scraping and content extraction change once systems move from prototype to production. As AI agents and RAG pipelines scale, the extraction layer has to deliver consistent structure, reliable access, and outputs that are usable without heavy post-processing. Choosing a Firecrawl alternative comes down to which capability your workflow depends on most, and how reliably the tool can deliver it at production scale.
1. Nimble – Recommended for production AI agents requiring real-time, structured web data at enterprise scale

Teams building production AI agents and RAG pipelines use Nimble when they need real-time, structured web data from the live web, not cached results or raw page content. The platform’s Web Search Agents access complex sites, extract schema-defined data, validate outputs, and return structured JSON that AI systems can use with less post-processing. That makes it a strong fit for enterprise teams that need web data collection to run reliably at production scale.
Key Strengths
- Delivers structured data that maps directly to the specific schemas required by production-ready agentic workflows.
- Prioritizes live web access over cached search results so AI agents and RAG systems operate on current data.
- Navigates complex sites and hard-to-reach data that typically trigger blocks or anti-bot measures.
Key Limitations
- Designed for production AI web scraping and content extraction workflows, so it may be more than needed for simple, single-page content extraction use cases.
- Pricing is tailored to usage and scale, so exact costs are typically determined based on production requirements.
Why Choose It Over Firecrawl
Move to Nimble when your system outgrows Firecrawl’s Markdown-first approach. While Firecrawl is an efficient choice for converting URLs into clean text for LLMs, it isn’t designed for every schema-rigid, high-volume production environment. Nimble replaces simple extraction with Web Search Agents that deliver structured JSON and the access reliability needed when web data becomes a mission-critical input.
Pricing
Pricing is customized based on usage and scale. A pay-as-you-go free trial is also available.
Review
“Effortlessly deriving impactful insights from complex web data, Nimble’s advanced technology simplifies my role as a data engineer with its seamless and powerful platform. The ease of extracting and utilizing structured data is transformative.”
2. Apify - Recommended for managed scraping with pre-built actors for specific platforms
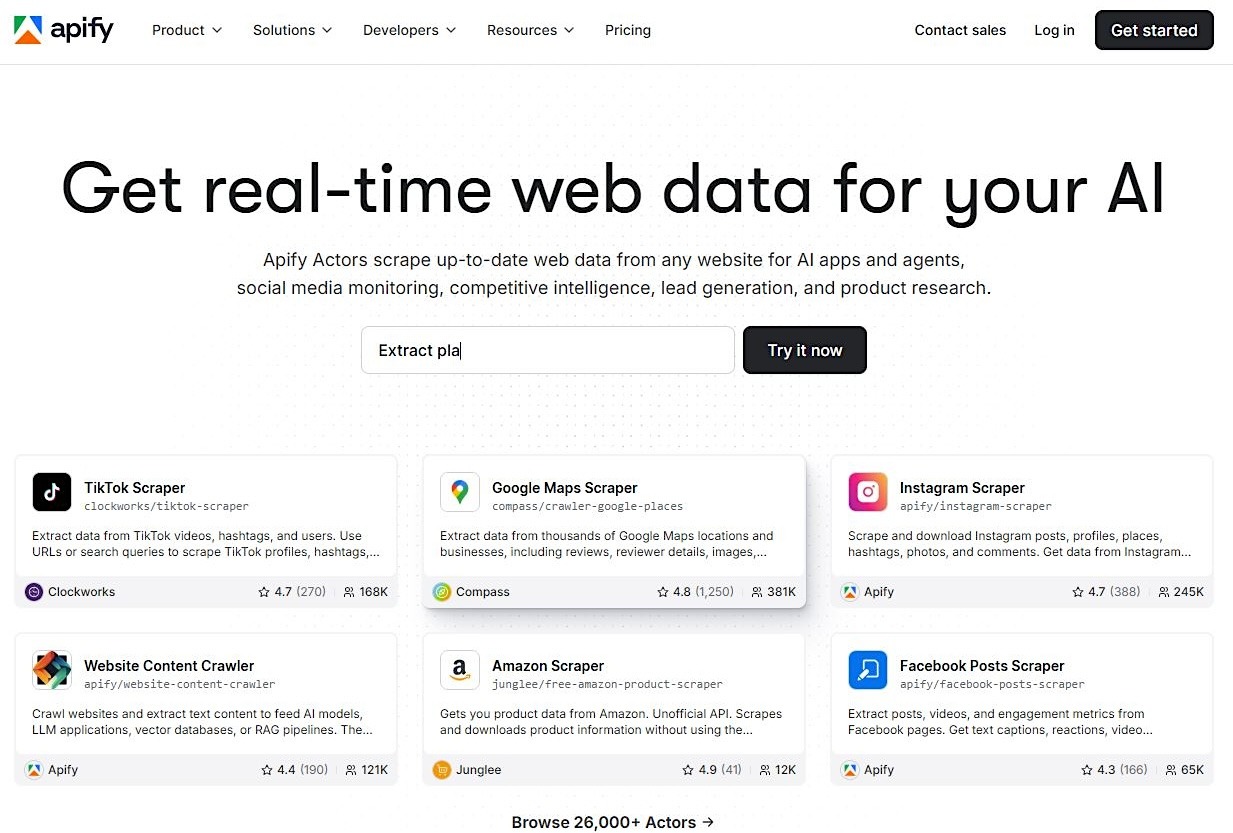
Apify is a cloud platform where developers run scraping jobs as hosted programs called Actors. Each Actor contains the logic for interacting with a specific site or workflow, including navigation, extraction, and data formatting. Because that logic is packaged and reusable, teams can run proven scrapers for known sources or deploy their own without managing servers or job orchestration.
Key Strengths
- Large marketplace of pre-built Actors for specific sites and data sources.
- Enables teams to run site-specific scrapers without building extraction logic from scratch.
- Supports scheduled runs, API-triggered jobs, and automated scraping workflows.
Key Limitations
- Actors are often community-maintained or domain-specific, so data quality depends on how well each script is maintained.
- While Actors reduce initial builds, complex or highly customized workflows still demand regular developer oversight to handle site changes or script failures.
Why Choose It Over Firecrawl
Firecrawl is designed for general page extraction, while Apify is built around reusable, site-specific scraping logic. An Apify Actor is more efficient than building a new scraper from scratch. Using pre-built scripts shifts your focus from the mechanics of extraction to the actual management of the resulting data pipeline.
Pricing
Apify offers a free plan, then paid plans starting at $29/month, with usage charged through platform credits and compute units.
Review
“The Actor marketplace is incredibly valuable…Apify handles all the web scraping infrastructure. Pre-built Instagram Actors give me structured data that I pipe directly into my AI scoring pipeline.”
3. Bright Data – Recommended for enterprise proxy infrastructure and pre-built dataset delivery
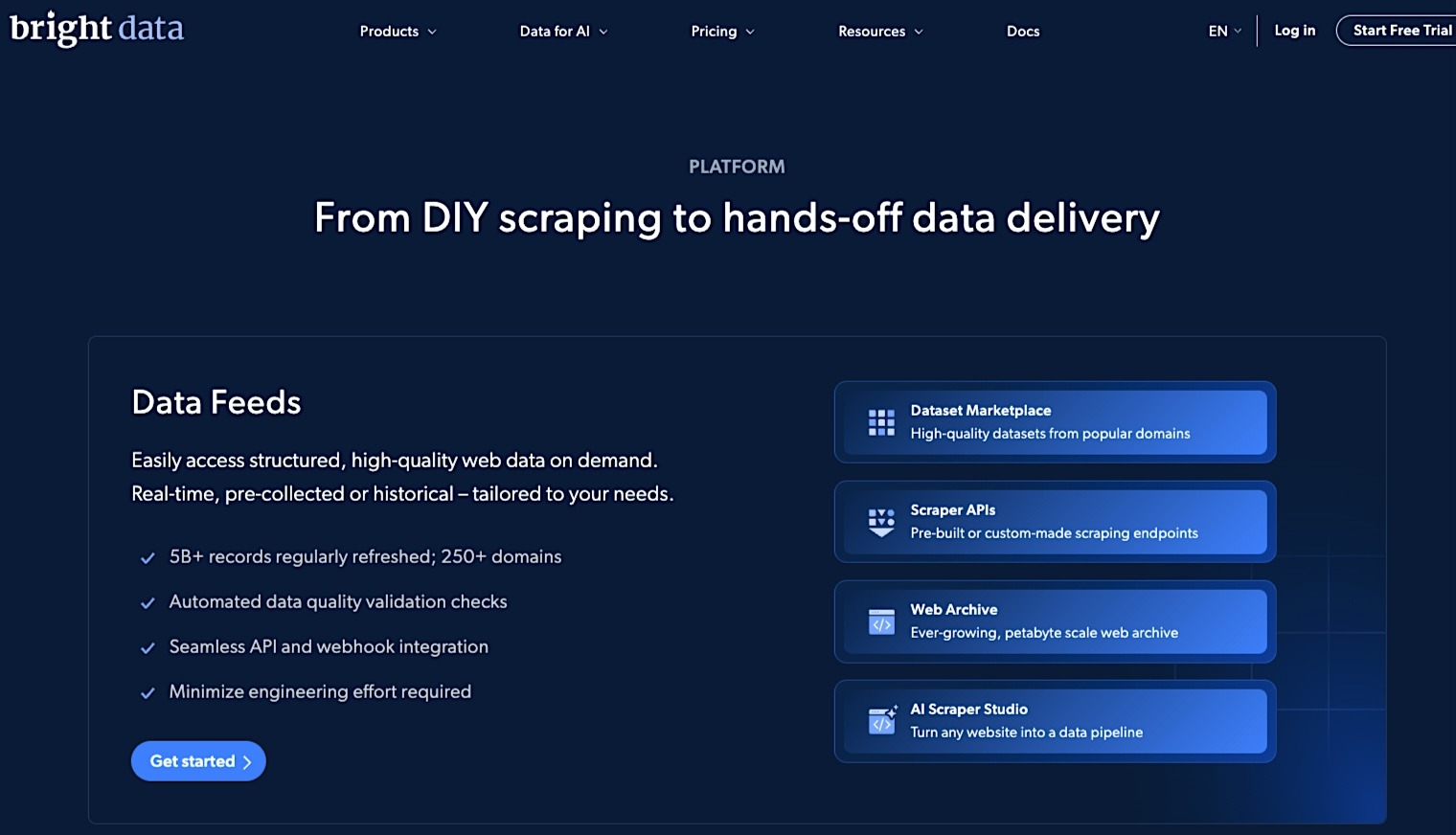
Bright Data is an enterprise web data platform built around proxy infrastructure, scraping tools, Web Unlocker, and ready-made datasets. It fits teams that need large-scale access infrastructure or pre-built data delivery rather than a lightweight URL-to-content extraction API. For AI teams, its main value is reliable access to difficult web sources and high-volume collection workflows.
Key Strengths
- Offers ready-made datasets and delivery options for teams that want web data without building every scraper or extraction workflow themselves.
- Provides large-scale proxy infrastructure for global web access and high-volume data collection.
- Handles CAPTCHAs, rate limiting, and 403 errors automatically through its “Web Unlocker” and browser-led scraping tools.
Key Limitations
- The platform spans proxies, scraping APIs, SERP tools, and datasets, so that the setup can require more configuration than developer-first content extraction tools.
- Proxy routing and unblocking overhead can result in higher latency compared to HTTP-only search layers.
Why Choose It Over Firecrawl
Choose Bright Data when site access, proxy infrastructure, or pre-built data delivery matters more than clean Markdown extraction. Firecrawl is stronger for turning pages into LLM-ready content, while Bright Data is built for teams that need enterprise-scale access infrastructure, unblocking, and large-volume collection.
Pricing
- Offers a prebuilt Web Scraper API with a four plans: Free at 1K requests (one-time); Pay-as-you-go at $1.5/1K records; Scale at $499/month/384k records + pay-as-you-go for more; and a custom enterprise plan.
- There’s also an AI Scraper Studio that turns prompts into custom scrapers, with four plans ranging from a pay-as-you-go model to tiered subscriptions based on page loads.
Review
“What I like best about Bright Data is the breadth of features and how powerful the platform is for large-scale web data collection. It offers a wide range of proxy options and data collection tools, which makes it really useful for many different research and development needs.”
4. Crawl4AI – Recommended for self-hosted, LLM-optimized crawling with full pipeline control

Crawl4AI provides an open-source alternative for LLM-focused web crawling and extraction. It runs on Python and uses Playwright to load and interact with pages the same way a browser would, then lets developers define how content is selected and structured. Because it is self-hosted, teams control how crawling runs, how data is extracted, and how results are stored or passed into downstream systems.
Key Strengths
- Supports adaptive crawling features that help guide crawl depth and focus based on relevance, rather than relying only on fixed crawl rules.
- Offers multiple extraction strategies, including CSS, XPath, and LLM-based strategies that can be swapped without rewriting core crawl code.
- Supports markdown generation designed for LLM ingestion, so teams can move crawled content into retrieval workflows without starting from raw HTML.
Key Limitations
- Scaling is your responsibility. Crawl4AI gives you the framework, but your team still has to operate it reliably at production volume.
- Protected sites still require a separate access strategy. If a target starts blocking requests, Crawl4AI will not manage that infrastructure for you.
Why Choose It Over Firecrawl
Choose Crawl4AI when you want to avoid per-page managed API costs and keep more control over the extraction workflow. Firecrawl is optimized for quick, easy extraction, but it lacks the deep customization available in a self-hosted Python framework.
Pricing
Crawl4AI is an open-source, free-to-use Python library under the Apache 2.0 license. While the software is free, users must cover their own infrastructure costs
Review
“I feel that the crawling ability of this tool is better than many professional non-free crawling tools. It even solved many social networking sites with serious anti-crawling problems.”
5. Diffbot - Recommended for structured entity extraction and knowledge graph enrichment

Diffbot specializes in converting web pages into structured entities rather than simple, readable content. Its Extract API uses AI, computer vision, and natural language processing to classify pages and return structured JSON. The Knowledge Graph adds entity enrichment across sources, which is why Diffbot fits use cases where teams need records and relationships rather than page-level Markdown.
Key Strengths
- Moves beyond text scraping to identify and extract web data as distinct, schema-mapped entities.
- Specialized for extracting organizations, products, articles, people, and discussions for workflows that require linked entity data.
Key Limitations
- Significantly less lightweight than standard URL-to-Markdown tools; requires more integration effort to leverage its full relational capabilities.
- For simple RAG ingestion where you only need basic page text, the entity-mapping layer introduces unnecessary complexity.
Why Choose It Over Firecrawl
Firecrawl is a better fit when you need clean page content for an LLM. Choose Diffbot when your workflow depends on structured entities, linked records, or Knowledge Graph enrichment rather than Markdown extraction.
Pricing
Diffbot offers four pricing levels based on usage, features, and active crawls: Free, Startup at $299/month; Plus at $899/month; and Enterprise with bespoke pricing and features.
Review
“Overall, Diffbot's tools are simple to use and understand outside of more complex use cases. We use several of their features to deliver content insights to our clients. I would recommend Diffbot to any person or organization that needs to pull large amounts of data from arbitrary web sources.”
6. Jina Reader - Recommended for lightweight, zero-setup URL-to-Markdown conversion

Jina Reader keeps the extraction path deliberately narrow: give it a public URL, and it returns clean Markdown for LLM use. Its value is speed and simplicity at the page level, especially when the source content does not need schema extraction or a full crawl. For AI engineers, it is useful as a lightweight ingestion step for basic RAG and agent workflows where readable content is enough.
Key Strengths
- Generates clean Markdown by prepending the Reader endpoint to a URL
- Filters out common page noise, including navigation elements and scripts, so the returned Markdown is easier to pass into an LLM.
- Works well for quick page ingestion when the target output is readable Markdown.
Key Limitations
- Jina Reader is focused on page-level conversion, not managed multi-page crawling or site-wide extraction.
- It is not designed for schema-defined extraction where the required output is structured JSON.
Why Choose It Over Firecrawl
Firecrawl is better for broader crawl and extraction workflows. If you do not need that level of infrastructure, Jina Reader is a faster path for basic RAG ingestion. It gets page content into a model-readable format with less setup, which makes it a better fit when you only need clean URL-to-Markdown conversion.
Pricing
Jina Reader is an open-source project under the Apache 2.0 license. The hosted Reader API can be used for free (up to 10 million tokens) on the Toy Experiment plan without an API key, with API key options for higher usage on the Prototype Development plan ($50/month/up to 1 billion tokens) or the Production Deployment plan ($500/month/ up to 11 billion tokens).
Review
“Enter Jina Reader by Jina AI —an absolute game-changer! This simple tool dramatically improves the input quality for your AI systems, ensuring better, more reliable outputs.”
7. ScrapingBee - Recommended for reliable HTML rendering on bot-protected sites

ScrapingBee is a web scraping API designed to take the pain out of headless browsers and proxy management. It handles JavaScript rendering and proxy management on the backend so your team can pull rendered HTML without babysitting a massive browser infrastructure. For pages that block basic requests or load content through JavaScript, ScrapingBee gives developers a managed way to reach the rendered page before any downstream extraction happens.
Key Strengths
- It handles full JavaScript execution natively, which is non-negotiable for modern single-page applications where the data isn't even in the HTML until the scripts run.
- The service manages proxy rotation on its own, which makes it harder for anti-bot systems to spot and flag your requests compared to static IPs.
- Useful for accessing protected or dynamic pages that standard HTTP clients cannot reliably reach
Key Limitations
- ScrapingBee is still primarily an access and rendering API, so teams may need extra work to turn returned HTML, Markdown, or extracted fields into structured data for AI workflows.
- Turning on JavaScript rendering or using premium proxies consumes credits faster, so costs can rise depending on the target site's complexity.
Why Choose It Over Firecrawl
Use ScrapingBee when anti-bot resistance is the primary obstacle for your pipeline. While Firecrawl focuses on AI-ready Markdown, ScrapingBee is an access specialist for protected or dynamic domains.
Pricing
ScrapingBee’s paid plans start at $49/month, with higher tiers based on API credits, concurrency, JavaScript rendering, proxies, geotargeting, and support needs.
Review
“The product itself is strong. Premium Proxy with header forwarding and JavaScript rendering handled GraphQL scraping against a well-defended e-commerce platform reliably, with predictable per-call credit costs. My daily scheduled scrapes run cleanly.”
Choose the Right Firecrawl Alternative for Production AI Workflows
Firecrawl is a strong starting point for AI web scraping and content extraction, but production use cases often require a more specific fit. The right alternative depends on whether the team needs self-hosted control, platform-specific scraping, lightweight extraction, or enterprise-grade structured data for AI agents that depend on current web data.
Nimble’s AI Search Platform is ideal for teams that have outgrown extraction-focused tools and need Web Search Agents that access the live web, extract structured data, and deliver reliable outputs for production AI agents. Instead of relying on raw Markdown cleanup or fragile scraping workflows, Nimble turns live web pages into structured, agent-ready data that can support enterprise-scale AI web scraping and content extraction.
Book a Nimble demo to see how it supports production AI agents with real-time, structured web data.
FAQ
Answers to frequently asked questions

.png)
.png)
.avif)
.png)
.png)