9 AI Web Scraping Use Cases and Suggested Tooling

Tom Shaked

9 AI Web Scraping Use Cases and Suggested Tooling
Tom Shaked
Most popular articles

Get structured, reliable data for your stack.
Isn't AI amazing?! It seems to be able to do so much with little more than a short prompt. An AI agent can provide a competitive edge by researching companies, tracking markets, and identifying competitive signals. However, AI is only as good as the data it is being provided. Every large language model (LLM) has a training cutoff, and everything that happened after it is a blind spot.
If the data is not timely, when you ask your agent what a product costs today or what a competitor announced last week, it will either guess or admit it does not know. For AI engineers building production agents, data freshness imposes a fundamental constraint on what their systems can actually do.
AI web scraping solves these issues by connecting AI systems directly to the live web. Instead of reasoning from static training data, agents can retrieve current information from public web sources at the moment they need it. This capability extends across any area where teams need structured, real-time web data and can’t afford for it to be stale, such as data engineering, competitive intelligence, retail analytics, and financial research. That’s why the AI-driven web scraping market is growing rapidly, from $7.79 billion in 2025 to a projected $47.15 billion by 2035.
What separates AI web scraping from traditional data scraping approaches is the intelligence layer added on top of crawling and extraction. Machine learning models interpret page structure, normalize inconsistent data, and orchestrate complex multi-step collection workflows without the brittle, hand-coded scrapers that break every time a website updates its layout, and purpose-built platforms can handle these workflows at scale.
Let's break down nine of the highest-value AI web scraping use cases, what each one involves, and the tooling stack typically used to execute it.
What is AI web scraping?
AI web scraping is the process of using artificial intelligence to automate data extraction from websites, enabling systems to collect and process web data more effectively than manual or rule-based methods. It is particularly useful for AI and data teams that rely on fresh, structured data to power agents, analytics, and machine learning (ML) workflows.
AI web scraping extends traditional scraping by adding ML and automation layers that help interpret page content, normalize data across inconsistent sources, and support complex, multi-step collection workflows. A key advantage is that it can turn unstructured web pages into structured outputs, such as JSON or tabular datasets, making the data immediately usable in downstream systems without extensive additional parsing.
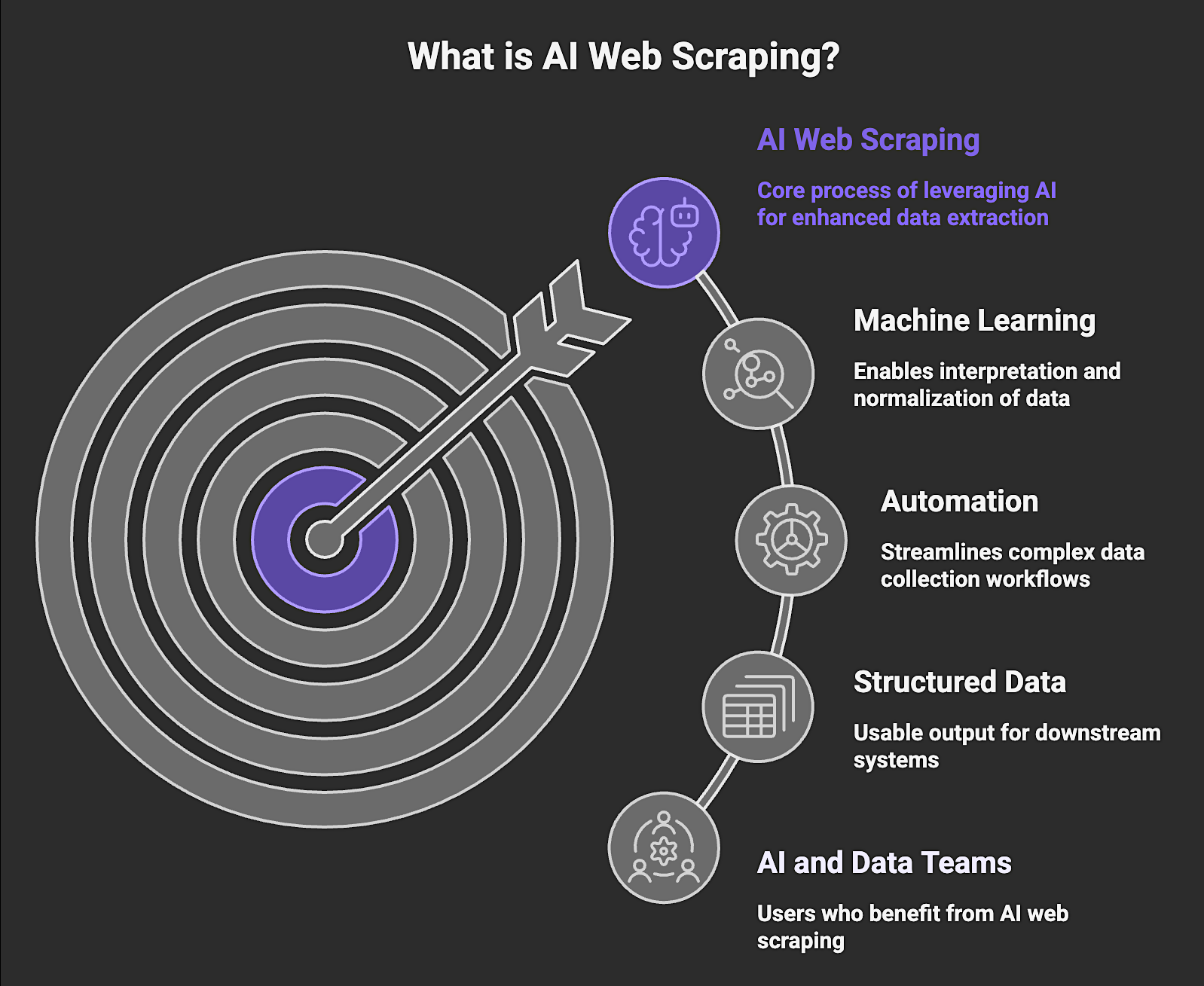
Traditional scrapers depend on fixed selectors tied to specific HTML elements, but they often break when a website changes its layout or class names. AI-powered extraction replaces or augments these fragile rules with models that better understand page structure, making pipelines more resilient and easier to maintain at scale.
At the same time, AI does not replace the infrastructure required to access web content reliably. Crawling systems, headless browser rendering, proxy networks, and anti-bot handling remain essential, especially as more websites rely on JavaScript and deploy stronger detection systems. The most effective AI web scraping systems combine intelligent extraction with infrastructure that can retrieve data consistently across dynamic and protected web environments.
7 Advantages of AI Web Scraping
AI web scraping improves on traditional web scraping and manual data extraction across several dimensions that matter for production deployments, including:
1. Ability to Extract Structured Data from Unstructured Pages
Most web pages are designed for human readability, and not for machine consumption. AI models can interpret layout, infer field relationships, and return clean, structured records even when the underlying HTML is inconsistent or lacks semantic markup, which eliminates the need for custom parsing logic on a site-by-site basis.
2. Faster Development of Data Pipelines
Defining extraction logic for new data sources traditionally requires significant manual effort. AI-powered scraping can generalize across similar page types to reduce the time engineers spend writing and maintaining site-specific scrapers, while also accelerating the path to a working data pipeline.
3. Improved Data Normalization and Cleaning
Web data is inherently inconsistent. Product prices appear in different formats, dates use different conventions, and field names vary across sources. AI layers can identify and normalize these inconsistencies at extraction time and deliver cleaner data that requires less downstream processing before it is ready to use.
4. Better Handling of Dynamic and JavaScript-Heavy Websites
A large share of the modern web renders content through JavaScript after the initial page load. AI scraping systems built on headless browser infrastructure can render these pages as a real browser would. This ability makes content accessible that traditional HTTP-based scrapers cannot reach at all.
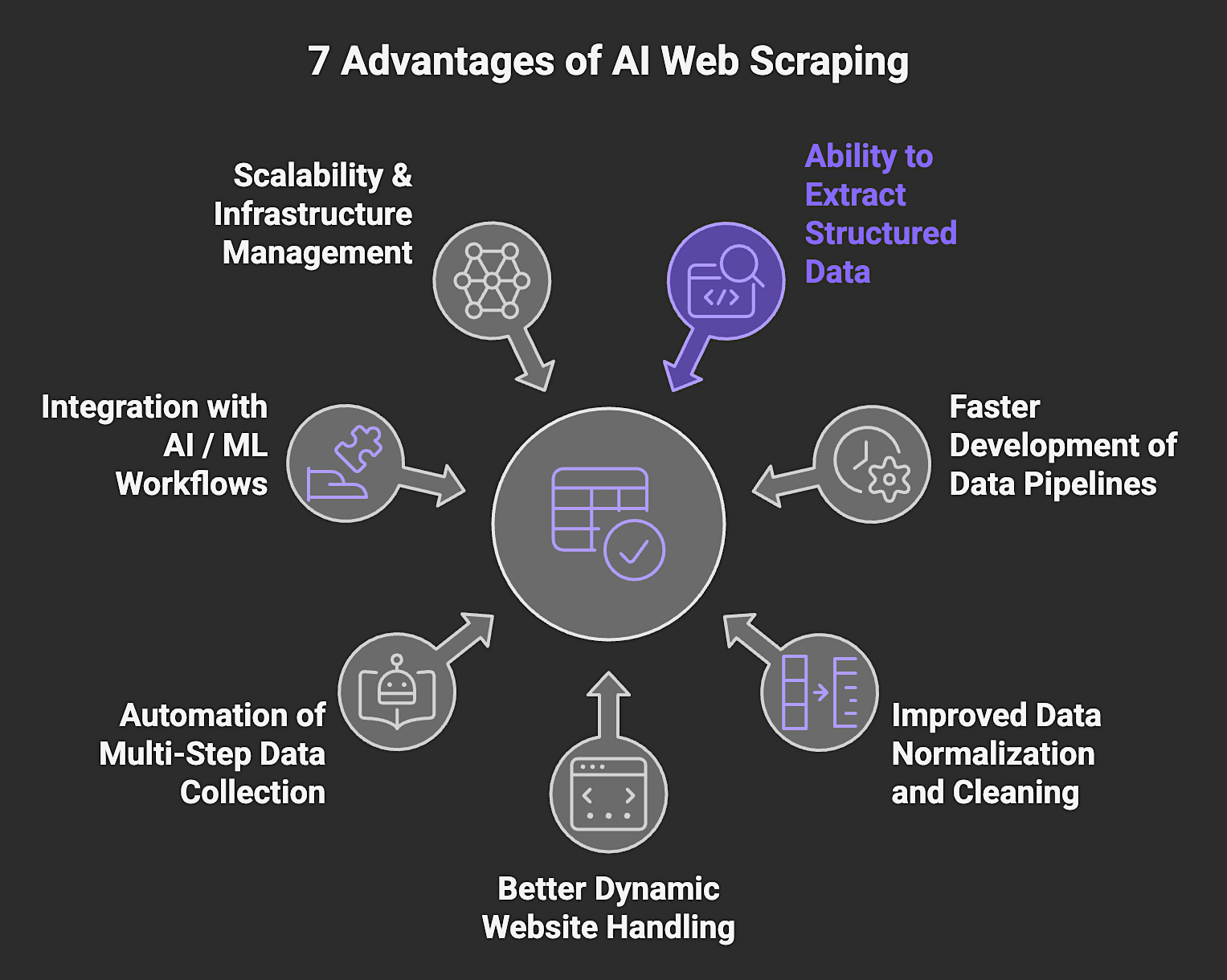
5. Automation of Multi-Step Data Collection
Some data collection tasks require navigating sequences of pages, interacting with filters, or following pagination logic. AI agents can plan and execute these multi-step workflows autonomously, handling complexity that would otherwise require custom automation scripts for every target site.
6. Integration with AI / ML Workflows
Data collected through AI web scraping arrives in formats that integrate directly with AI and ML infrastructure. Structured JSON outputs can feed vector databases, feature stores, training pipelines, and agent frameworks without intermediate transformation steps that add latency and introduce additional failure points.
7. Scalability and Infrastructure Management
Scaling traditional scrapers across thousands of URLs and domains requires managing proxies, handling rate limits, rotating sessions, and monitoring for blocks. AI web scraping platforms abstract this infrastructure complexity to enable teams to scale data collection without building proxy networks, browser orchestration layers, or anti-bot systems in-house. Platforms like Nimble provide this as a managed layer that allows engineers to focus on data usage instead of infrastructure maintenance.
9 AI Web Scraping Use Cases with Suggested Tooling
These use cases represent where AI web scraping delivers the most concrete value across engineering, analytics, and business intelligence workflows:
1. AI Agent Research and Fact Retrieval
AI agents require access to current web data to answer questions about companies, products, markets, and events. Without a live web connection, agents are limited to what was true at their training cutoff, which makes them unreliable for any use case that depends on current facts.
AI web scraping enables agents to retrieve live information instead of relying on model training data. This capability transforms them from static knowledge bases into continuously informed systems.
Example tasks:
- Identify the current CEO or leadership team of a company
- Retrieve details on competitor product launches
- Collect company facts for automated research reports
- Validate statements against current web sources
Workflow and Tooling:
- AI agent sends a research query to a live web search layer [Nimble Search API]
- Relevant web pages are retrieved and rendered for structured extraction [Nimble Extract API]
- Structured data from multiple sources is aggregated and deduplicated [Python / Pandas]
- LLM reasoning synthesizes the results into a final answer [OpenAI or Anthropic]
- Agent framework manages the multi-step workflow [LangChain or CrewAI]
2. AI Training Data Collection
AI teams use public web data to build AI training datasets for machine learning models. The quality of what gets collected directly determines what models can learn. Once extracted, teams curate datasets by removing duplicates, applying labels, and filtering out low-quality or irrelevant records before training begins. AI web scraping makes it possible to collect data at the volume and consistency required for meaningful model training across a wide range of domains.
Example tasks:
- Gather product catalogs for training datasets
- Collect structured company data across industries
- Build labeled datasets from public web sources
- Capture structured domain knowledge for fine-tuning AI models
Workflow and Tooling:
- Large numbers of web pages are discovered and collected at scale [Nimble Crawl API]
- Page content is rendered and structured into datasets [Nimble Extract API]
- Extracted records are deduplicated, labeled, and quality-filtered [Python / Pandas]
- Curated datasets are stored in scalable data infrastructure [Databricks, Snowflake, or S3]
- Models are trained on the resulting datasets [Hugging Face]
3. Competitive Intelligence and Market Monitoring
Organizations monitor competitors to track product launches, pricing changes, hiring signals, and messaging updates. Doing this manually is slow, inconsistent, and impossible to scale across multiple competitors and domains.
AI web scraping enables automated, continuous monitoring that surfaces changes as they happen rather than when an analyst happens to check. The result is a competitive intelligence operation that is faster, broader in coverage, and less dependent on human effort to stay current.
Example tasks:
- Monitor competitor product releases and feature announcements
- Track pricing page changes across SaaS companies
- Detect hiring signals from job postings
- Track messaging changes on product and landing pages
- Detect brand misuse and misleading comparisons for brand protection
Workflow and Tooling:
- Web crawling collects relevant pages from competitor domains on a defined schedule [Nimble Crawl API]
- Page content is rendered and extracted into structured data [Nimble Extract API]
- Data warehouse stores historical competitor datasets for trend analysis [Databricks or Snowflake]
- Processing layer detects changes and calculates trends [Python / Pandas]
- Dashboards surface competitive insights to relevant teams [Looker or Tableau]
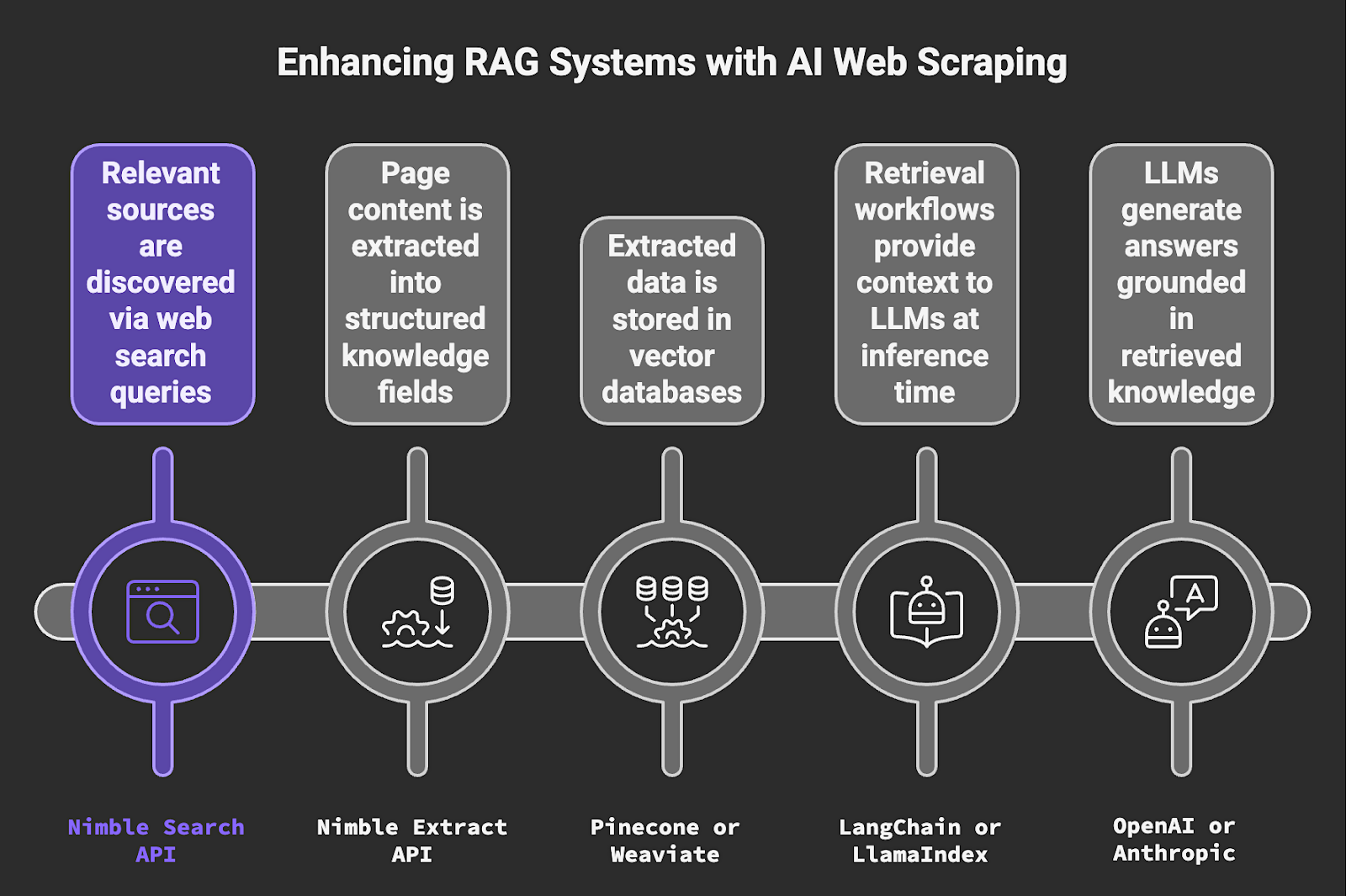
4. RAG Knowledge Base Enrichment
Retrieval-augmented generation (RAG) systems extend LLMs by grounding their responses in external knowledge retrieved at inference time. For RAG to work reliably, the knowledge base it draws from needs to be current and accurate.
Stale or incomplete knowledge bases produce confident but incorrect answers, which is the exact failure mode RAG is supposed to prevent. AI web scraping provides the mechanism to keep those knowledge bases continuously refreshed from public web sources, with data stored in formats compatible with vector retrieval architectures.
Example tasks:
- Extract structured company profiles for knowledge bases
- Collect product information for retrieval systems
- Maintain updated external data sources for AI assistants
- Build knowledge graphs from public web data
Workflow and Tooling:
- Relevant sources are discovered via web search queries [Nimble Search API]
- Page content is extracted into structured knowledge fields [Nimble Extract API]
- Extracted data is stored in vector databases [Pinecone or Weaviate]
- Retrieval workflows provide context to LLMs at inference time [LangChain or LlamaIndex]
- LLMs generate answers grounded in retrieved knowledge [OpenAI or Anthropic]
5. Lead Generation and Sales Intelligence
Sales teams use AI web scraping to collect company and contact information from public websites and build structured prospect lists. Manual research is too slow to produce lists at the volume modern sales motions require, and static purchased lists go stale quickly.
AI web scraping makes it possible to generate lead data programmatically by pulling structured records from relevant sources, enriching them with additional attributes, and loading them directly into CRM systems ready for outreach.
Example tasks:
- Extract company profiles and contact details from public sources
- Identify potential buyers by industry, company size, or technology signals
- Build structured lead lists for sales teams
- Enrich company records with additional data points
Workflow and Tooling:
- Lead data is extracted from public web sources at scale [Nimble Search API]
- Additional company attributes are enriched [Clay]
- Lead records are validated and deduplicated [Python / Pandas]
- Leads are stored and managed within CRM systems [HubSpot or Salesforce]
6. E-commerce Price Monitoring
Retail and CPG companies track product prices, promotions, and availability across online retailers and marketplaces to inform pricing strategy and respond quickly to competitive moves. E-commerce sites are among the most difficult to scrape reliably because they are JavaScript-heavy, frequently updated, and actively protected against automated access.
AI web scraping provides the infrastructure to collect structured pricing data from these sites consistently and at scale, without degradation over time as site structures change.
Example tasks:
- Track SKU-level price changes across retailers
- Detect promotional discounts and bundle offers
- Monitor stock availability across marketplaces
- Compare price positioning against competitors
- Track pricing & promo changes affecting conversion optimization
Workflow and Tooling:
- Product data is collected from retailer websites at scale [Nimble Web Search Agents]
- Structured product fields (price, promo status, availability, etc.) are extracted [Nimble Extract API]
- Data warehouse stores historical pricing datasets for trend analysis [Databricks, Snowflake, or S3]
- Processing layer computes price changes and promotion frequency [Python / Pandas]
- Dashboards visualize pricing trends and surface alerts [Looker or Tableau]
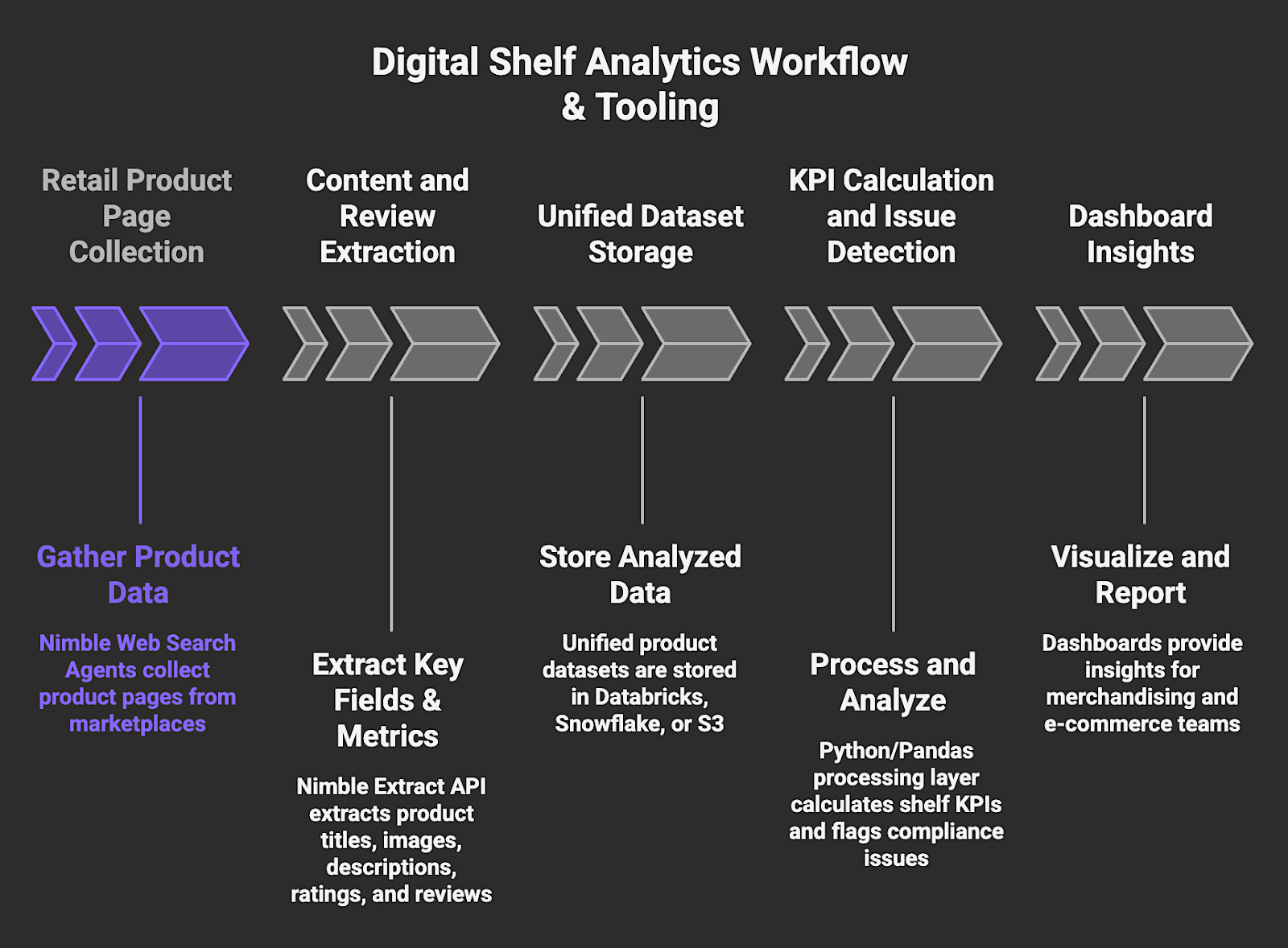
7. Digital Shelf Analytics
Digital shelf analytics tracks how products appear across retailer sites and marketplaces, and covers product content quality, ratings, reviews, pricing, and availability. For brands selling through third-party retailers, the digital shelf is the equivalent of in-store placement and presentation, and it changes constantly.
AI web scraping makes it possible to monitor shelf presence systematically across hundreds of SKUs and multiple retail environments. It gives merchandising and e-commerce teams the visibility they need to act on content issues before they affect conversion.
Example tasks:
- Audit product titles, images, and descriptions for content compliance
- Track ratings and review volume changes over time
- Monitor product availability across retail channels
- Detect content compliance issues before they affect conversion
Workflow and Tooling:
- Retail product pages are collected at scale across marketplaces [Nimble Web Search Agents]
- Product content fields and review metrics are extracted [Nimble Extract API]
- Unified product datasets are stored for analysis [Databricks, Snowflake, or S3]
- Processing layer calculates shelf KPIs and flags compliance issues [Python / Pandas]
- Dashboards provide insights for merchandising and e-commerce teams [Looker or Tableau]
8. SERP Monitoring and Search Intelligence
Organizations collect search engine results to monitor search visibility, track how competitors appear in results, and analyze keyword performance across markets and geographies. Search results change frequently because they are driven by algorithm updates, new content, and competitor activity.
The high variability makes periodic, manual SERP checks insufficient for any team that depends on organic search as a channel. By enabling continuous, systematic SERP data collection, AI web scraping provides SEO and growth teams with a reliable foundation for tracking and strategic decision-making.
Example tasks:
- Track rankings for target keywords across geographies
- Uncover geo-specific search result variations
- Monitor competitor appearances in search results
- Detect SERP feature changes and new result types
- Compare search visibility across geographic markets
Workflow and Tooling:
- Search results are collected at scale for defined keywords and locations [Nimble Web Search Agents]
- SERP datasets are stored for historical tracking and trend analysis [BigQuery, Snowflake, or Databricks]
- Ranking changes and competitor visibility are calculated [Python / Pandas]
- Dashboards visualize search performance trends over time [Looker or Tableau]
9. Financial and Alternative Data Collection
Financial analysts and investment research teams collect structured signals from public web sources to identify market trends, track company activity, and generate alternative data insights that are not available through traditional financial data providers.
The value of alternative data is its timeliness because hiring trends, product announcements, and pricing changes are observable on the web before they appear in earnings reports or financial filings. AI web scraping provides the infrastructure to collect these signals systematically and structure them for quantitative analysis.
Example tasks:
- Track hiring activity across companies and geographies as a growth signal
- Monitor product launches and corporate announcements
- Extract structured signals from company websites
- Build time-series datasets for market and trend analysis
Workflow and Tooling:
- Public web sources are monitored continuously for relevant signals [Nimble Web Search Agents]
- Relevant pages are extracted into structured datasets [Nimble Extract API]
- Historical data is stored for financial analysis and backtesting [Databricks or Snowflake]
- Analytical features are generated from raw signals [Python / Pandas]
- Insights are visualized for analysts and research teams [Looker or Tableau]
Choose the Right Infrastructure for the Web Data You Need
AI web scraping is now a core capability for engineering and data teams that need real-time web data to power agents, pipelines, analytics, and intelligence systems across the enterprise. The use cases above share a common requirement: the data must be accurate, current, and structured well enough to be used without extensive downstream cleanup. That combination is harder to achieve than it appears, and it depends heavily on the quality of the infrastructure doing the collection.
Nimble provides the infrastructure layer that makes AI web scraping reliable at scale. Its Web Search Agents autonomously navigate the live web, extract structured data, and deliver analysis-ready outputs, eliminating the need for brittle scrapers and complex in-house pipelines. The platform handles the infrastructure complexity of rendering dynamic pages, bypassing anti-bot protection, and delivering clean outputs so engineering teams can focus on the applications and workflows that create business value.
Book a Nimble demo to see how its AI web scraping capabilities turn the live web into structured, real-time data pipelines for your AI and analytics workflows.
FAQ
Answers to frequently asked questions
.avif)
.png)
.png)
.png)
.png)