Model Validation Framework: How to Ensure AI Model Accuracy
.avif)
Ilan Chemla

Model Validation Framework: How to Ensure AI Model Accuracy
Ilan Chemla
Most popular articles

Get structured, reliable data for your stack.
Model Validation Framework: How to Ensure AI Model Accuracy
Watching an AI model 'pass validation’ feels good for about five minutes, but anyone who has spent real time around messy systems knows that inputs wander almost immediately. Drifts happen: maybe something changes in the dataset, or the market decides to swing in the opposite direction. However, even small drifts can quietly erode model accuracy and lead to mispriced offers, incorrect approvals, degraded customer experiences, or quiet compliance failures.
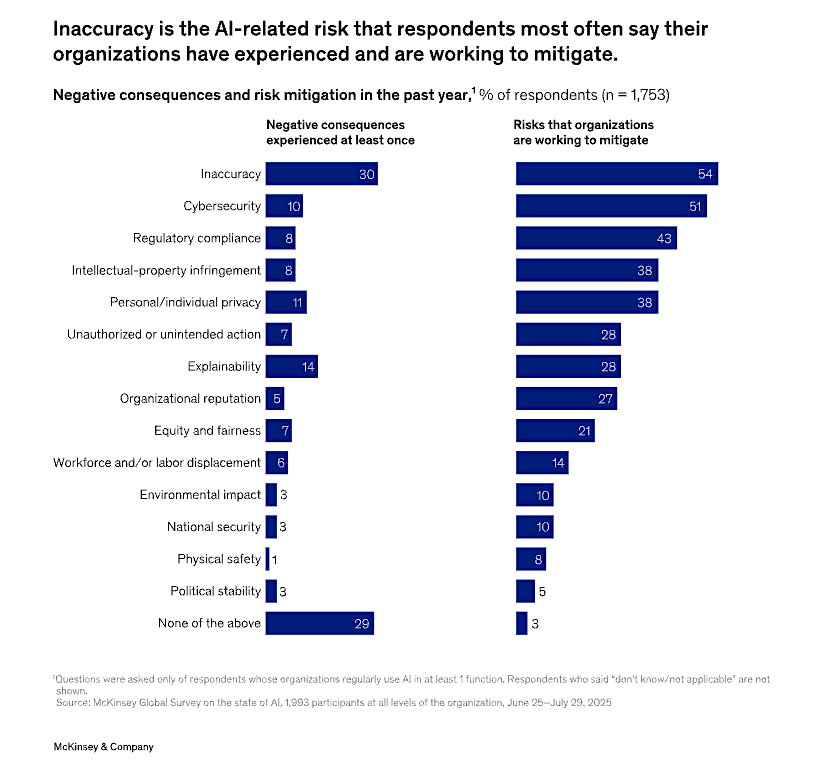
A recent survey revealed that inaccuracy was the top AI-related risk that organizations have experienced, with 54% of respondents making mitigation their top priority. The most effective way to do this is by using a model validation framework that treats validation as a disciplined, lifecycle practice for defining and preserving model accuracy. It transforms validation from a singular process into a continuous cycle by designing repeatable tests, comparing predictions against evolving ground truth, and feeding results back into retraining and governance.
Every team deploying AI models needs a validation framework. As models rely more on external and changing data, especially from the web, continuous validation becomes impractical without reliable and compliant data sources that remain current. Let’s explore what a model validation framework is and how to build one that keeps AI systems accurate and dependable long after they reach production.
What is model validation, and how does it relate to AI model accuracy?
AI model accuracy refers to the degree to which a model’s outputs align with actual outcomes in the context where the model is applied. It is not a fixed or universal measure. What counts as accurate depends on the task the model performs and the decisions its outputs inform. Accuracy also changes over time as data inputs and real-world conditions evolve.
Model validation is the process used to evaluate the accuracy of a model. It defines how performance is measured, tests a model on data it has not previously seen, and checks whether the results remain reliable once the model is exposed to real-world conditions. Validation applies before a model is released and continues after deployment.
Accuracy and validation are tightly linked. Accuracy is the outcome teams care about, but validation is what makes accuracy measurable and credible. Without proper validation, reported accuracy can be misleading, concealing weaknesses that only become apparent once a model is deployed in production.
What is a Model Validation Framework?
A Model Validation Framework (MVF) is a structured approach for assessing whether AI models continue to perform as intended under real-world conditions. It defines who is responsible for validation, when it occurs across the model lifecycle, and how performance, fairness, robustness, and ongoing health are evaluated as conditions change.
Instead of seeing validation as separate checks, the framework makes the whole process consistent. It covers data quality tests, performance metrics, documentation, approval steps, production monitoring, and when to re-validate.
A clear validation structure helps data scientists, risk teams, and business stakeholders communicate more easily. It also creates a record that shows how model quality and trust were checked, making audits easier.
A robust framework enables model validation to be a continuous process. It helps you spot problems early, keep everyone accountable, and move from development to production more quickly and safely. An MVF helps you keep models accurate and reliable while still allowing for innovation.
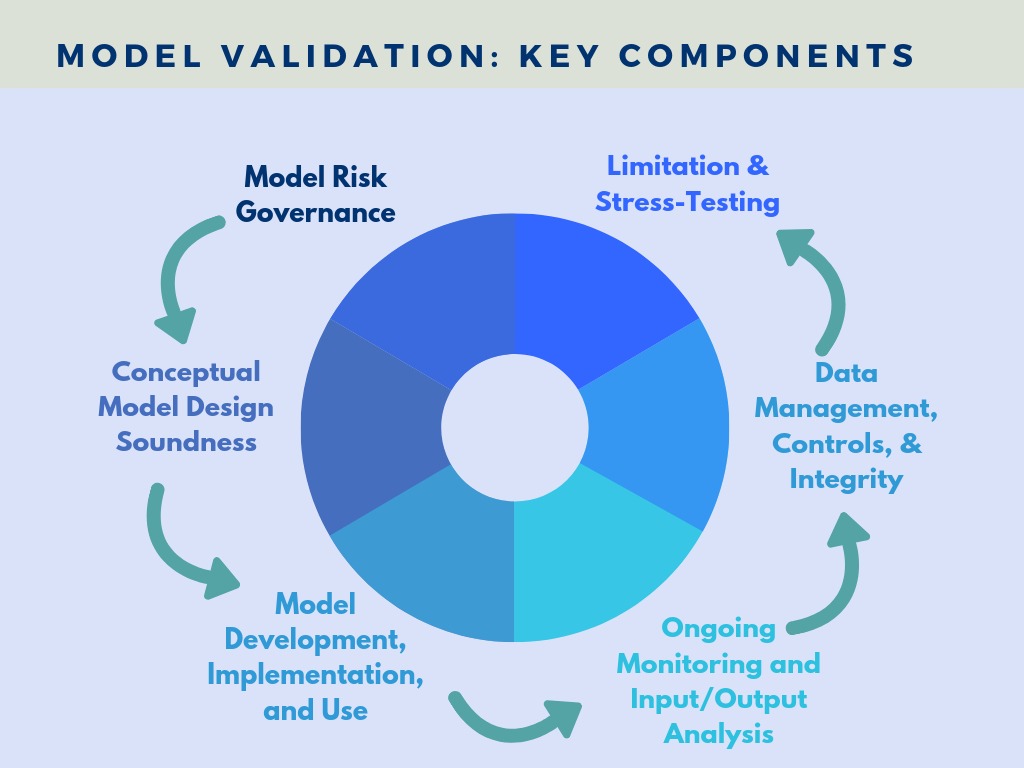
10 Elements of an Effective Model Validation Framework
Here are the ten essential components of an effective MVF:
1. Governance and Roles
Every reliable framework starts with ownership. Without clarity of responsibilities, validation either breaks down in practice or turns into a box-checking exercise. Clear roles establish accountability: A model needs a clear owner, an independent reviewer, and a defined decision-maker for when to deploy or roll back. This separation of duties is what keeps validation objective by preventing teams from approving their own models without independent review.
How to implement:
- Assign roles, such as Model Owner, Independent Validator, Risk or Compliance Partner (including a vCISO), and Product Sponsor.
- Draft a one-page validation policy outlining when reviews are needed, what evidence requires documentation, and who signs off.
- Embed validation gates into your SDLC.
- Review and update roles quarterly as your model inventory grows.
2. Model Inventory and Risk Tiering
This step involves developing a single, living registry that captures each model’s purpose, inputs, owners, dependencies, and risk rating in one place. A living inventory brings visibility and context to every model you’re testing and deploying.
How to implement:
- Create a spreadsheet with columns for Model Name, Owner, Use Case, Data Sources, PII Involvement, Third-Party Components, Last Validation, and Next Review.
- Add a tiering rubric ( e.g., Tier 1–3) based on impact and regulatory exposure.
- Assign validation frequencies like T1: monthly, T2: quarterly, T3: semiannual.
- Evolve to an internal model registry or governance platform as volume scales.
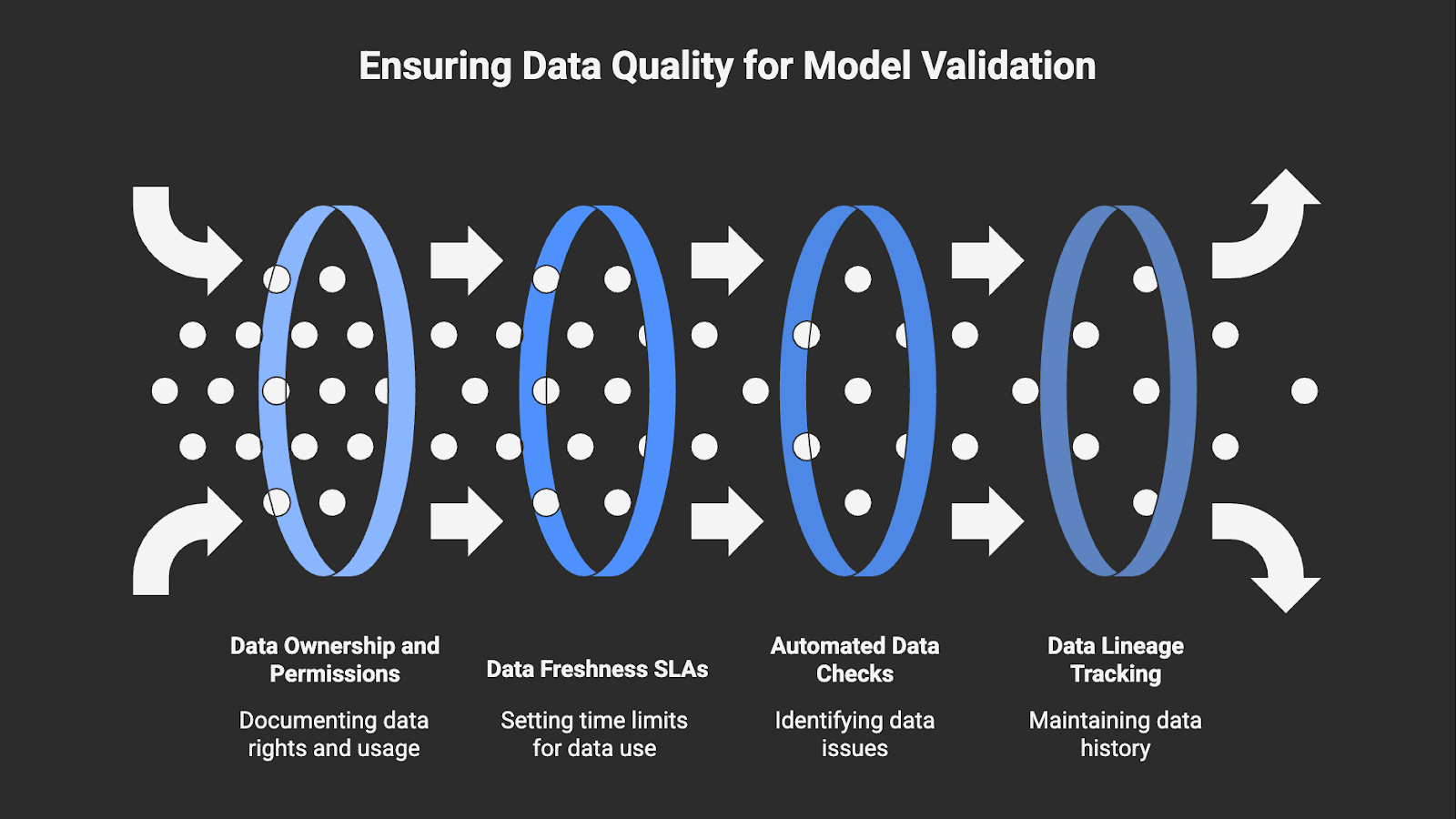
3. Data Quality, Provenance, and Lineage
In practice, model validation begins with confidence in the underlying data. You need to know where it came from, how fresh it is, and whether you’re legally allowed to use it. Clear AI data classification supports this by defining what types of data are involved, how they may be used, and where compliance or risk constraints apply.
If you can’t trust your data, you can’t trust your validation results. You must verify that the data used for training, evaluation, and monitoring is compliant, representative, fresh, and traceable from source to feature
How to implement:
- Build a source allowlist that documents data ownership, permissions, and update frequency.
- Define freshness SLAs for training and evaluation data (e.g., “no older than 30 days for time-sensitive models”).
- Run automated checks for missing values, duplicates, and unbalanced segments before retraining or validating.
- Maintain a simple lineage record: Source → Cleaning or Transformation → Feature Store → Model Input, and keep it updated with each model or data change.
4. Requirements and Acceptance Criteria
Next, AI organizations need to translate business intent and expected outcomes into measurable technical thresholds, and ensure everyone agrees on what “good” looks like before a model goes live. Model validation fails when “success” is subjective. Requirements and acceptance criteria give validation its backbone.
How to implement:
- Be clear about the business outcomes the model influences, such as profitability, fraud reduction, customer experience, or service speed.
- Translate those into technical metrics and acceptable bounds (e.g., recall ≥ 0.85, fairness gap ≤ 3%, latency ≤ 200ms).
- Establish explicit re-validation triggers, such as metric degradation, policy updates, or significant data-source changes.
- Document all of this information in a one-page acceptance sheet, signed by both the model owner and independent validator. This document becomes your contract between data science and the business, and it’s also your audit trail when regulators or executives ask why a model got approved.
5. Experimental Design and Resampling
Experimental design defines how you structure and repeat model testing so that performance estimates are statistically valid. Resampling supports this by repeatedly drawing new splits of the data, such as k-fold cross-validation or bootstrapping, to estimate how performance varies across samples.
Without a disciplined design, validation metrics can give a false sense of confidence. Random splits may leak future information, test sets may overlap with training data, and overly narrow samples can exaggerate performance. Experimental design guards against these traps by forcing deliberate data handling and independent evaluation.
How to implement:
- Select a resampling strategy that suits your data. Use k-fold cross-validation for general tabular data, time-series cross-validation or rolling windows when temporal order matters, and bootstrapping to estimate confidence intervals on small datasets.
- Apply stratified sampling so each split maintains class balance or key demographic proportions.
- Ensure no target or post-event features appear in training folds.
- Report the mean and standard deviation across resamples to make performance stability visible.
- Save random seeds, fold definitions, and software versions so another reviewer can reproduce the experiment exactly.
6. Performance Metrics by Use Case
Performance metrics are the quantitative measures used to evaluate how well a model performs its intended task. In a validation framework, they serve as the evidence that a model meets its acceptance criteria. The choice of the correct metrics depends on the model type and should reflect the real-world decisions the model supports.
Validation relies on tailored, problem-aware metrics to reveal how models behave under the conditions that matter to the business, and there’s no single definition of “good.” For example, a fraud model with high overall accuracy may still fail if it misses most real fraud cases, and a chatbot with fluent answers can still mislead users if it hallucinates facts.
To be meaningful, performance metrics must be evaluated against current and representative data. When evaluation data becomes stale or unrepresentative, performance metrics can give a false sense of confidence. Nimble’s real-time, structured web data pipelines help ensure that evaluation sets reflect the live environment in which models actually operate.
How to implement:
- Match metrics to model type and business impact.
- Always measure metrics across subpopulations, such as customers, regions, seasons, or traffic sources, to identify hidden inconsistencies.
- Pair metrics with qualitative observations or edge-case analysis; numbers alone rarely tell the whole story.
- As part of element nine’s production monitoring, track metric drift over time to understand whether performance holds as inputs evolve.
7. Fairness, Bias, and Explainability
This step focuses on evaluating fairness, bias, and explainability as part of the model validation process.
- Fairness means a model’s performance and outcomes are consistent across groups that are comparable for the given use case. There is no single universal fairness metric, so teams must choose (and document) the definition that fits the use case.
- Bias refers to systematic skew introduced through data collection, labeling, or feature design that can lead to uneven outcomes.
- Explainability is the ability to understand and communicate how input features influence a model’s predictions in a way that supports review by both technical and non-technical stakeholders.
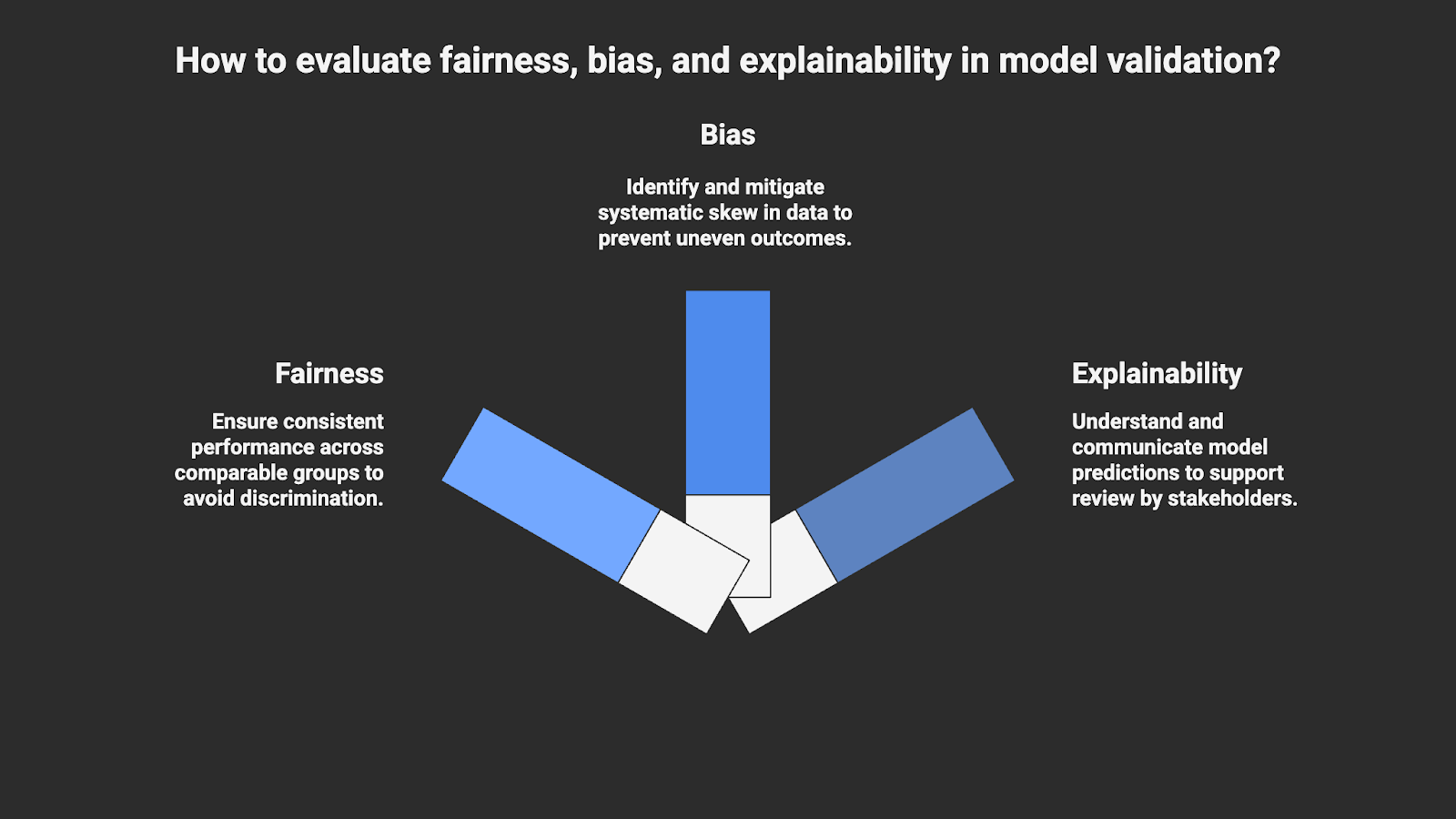
These considerations matter because validation is not only about whether a model performs well, but also whether its decisions can be understood and justified. Fairness and explainability help ensure that validation findings can be reviewed, discussed, and defended when model behavior is questioned.
How to implement:
- Identify cohorts meaningful to your domain (regions, customer types, product lines, or protected attributes) where applicable.
- Compare key metrics (error rates, approval ratios, predicted values) across these subgroups. Flag deviations beyond acceptable thresholds.
- Trace where bias could enter, in data collection, feature engineering, or labeling, and record mitigation steps such as re-weighting or balanced sampling.
- Utilize interpretability tools (SHAP, LIME, feature importance plots) to reveal feature contributions. Translate results into concise plain-language summaries for business and compliance audiences.
- For high-impact models, schedule a pre-release “fairness review” where you discuss findings, log trade-offs, and document approval.
8. Robustness and Stress/Adversarial Testing
Robustness and stress testing evaluate how a model behaves when faced with imperfect, extreme, or deliberately manipulated inputs. Adversarial testing examines how a model responds to intentionally crafted or malicious inputs, such when validating a tampering detection AI engine against attempts to bypass detection.
Most real-world failures come from AI models that behave unpredictably under unusual or shifting conditions. For example, a risk model might crumble when transaction patterns shift, or a recommendation engine could fail when new product types emerge. Stress testing exposes those vulnerabilities early. Robustness validation also defines operational boundaries by letting you see how far the model can be trusted before accuracy, fairness, or safety degrade.
Many models depend on real-time web data, where upstream changes can cause silent breakages. Use a data platform featuring browser agents that can emulate dynamic site behaviors like layout shifts and content variations, so that your model validation process includes exposure to the same volatility the model will face in production.
How to implement:
- Build datasets that include noise injection, outliers, missing values, and out-of-distribution (OOD) samples.
- For time-dependent models, accurately represent real-world scenarios by recreating seasonal surges, abrupt policy changes, or data interruptions.
- Utilize adversarial testing methods, such as perturbation techniques or red-teaming, to identify inputs that cause instability or unsafe responses.
- Deploy in shadow or canary mode to observe real traffic behavior under low risk before full release.
- Record when and how model performance degrades to define “safe operating limits” for production.
9. Production Monitoring and Drift Management
Production monitoring and drift management form the continuous validation layer that ensures a model remains reliable long after launch. Monitoring tracks live model behavior, while drift management detects when the relationship between data and predictions begins to shift.
Even a perfectly validated model will degrade once the world around it changes. Without continuous monitoring, drift creeps in quietly until accuracy drops or business decisions are impacted. Drift detection closes this gap between static validation and dynamic environments.
Because models increasingly depend on live or web-derived data, early drift detection requires visibility into upstream changes. Nimble’s real-time web data pipelines can flag shifts in content, structure, or patterns across source sites.
How to implement:
- Log key inputs, predictions, outcomes (where available), and metadata such as timestamps and source systems.
- Monitor accuracy proxies when true outcomes lag, along with data quality indicators (such as missingness and outliers) and statistical divergence scores (e.g., PSI, KS).
- Define automated triggers for review or retraining.
- Hold monthly or quarterly model health reviews for high-impact models; document drift findings, remediation actions, and owner sign-offs.
- Automate alerts and triage when drift persists (e.g., investigate upstream data changes, pipeline issues, seasonality, or label delays), then retrain only when warranted and require re-validation before redeployment.
10. Third-Party/LLM and Agent Validation
Modern AI stacks often combine in-house models with third-party, open-source, or hosted components. Third-party, LLM, and agent validation ensures that external components like APIs, pretrained models, or autonomous agents continue to meet your organization’s quality, safety, and compliance standards.
Each external dependency introduces uncertainty because model updates, hidden retraining tied to LLM training, or subtle prompt changes can shift behavior overnight. Without structured validation, these blind spots can create reputational, financial, or regulatory risk.
Autonomous agents and LLMs often rely on dynamic web context to make or justify decisions. Nimble’s browser and agent orchestration capabilities provide reproducible evaluation runs and safe sandboxes for testing these components under live web conditions.

How to implement:
- Create a vendor validation checklist with questions on model versioning, security posture, data handling, retraining cadence, SLAs, and bias testing evidence.
- Periodically review a random sample of predictions or completions using your internal evaluation rubric (factuality, tone, compliance, safety).
- Before rolling out updates or new agents, test them in an isolated environment that mirrors production to observe changes safely.
- Simulate misuse, prompt injection, or adversarial attacks to reveal vulnerabilities before attackers or customers do.
- Define clear guardrails for when third-party outputs fail validation, whether that means disabling an endpoint, switching providers, or reverting to a cached version.
Maintaining Model Confidence in a Changing World
AI models often fail after validation due to changes in real-world conditions. A Model Validation Framework provides organizations with a structured approach to confirm that models continue to perform as intended under changing data, market, and regulatory conditions. It aligns data science, risk, and business teams around measurable standards for accuracy, fairness, and resilience.
For teams whose models depend on live, external web context, maintaining this discipline at scale requires reliable, compliant, and continuously updated data. Nimble delivers that foundation with structured, real-time web data pipelines and browser/agent capabilities that enable the simulation of real-world conditions, early detection of upstream changes, and automation of ongoing checks across your validation cycle.
Try a Nimble demo to see how real-time, compliant data supports an effective model validation framework.
FAQ
Answers to frequently asked questions




.png)
.png)
.png)