9 Data Governance for AI Strategies to Implement Today | Nimble

Tom Shaked
.png)
9 Data Governance for AI Strategies to Implement Today | Nimble
Tom Shaked
Most popular articles

Get structured, reliable data for your stack.
9 Data Governance for AI Strategies to Implement Today
AI initiatives are scaling at a pace that far outstrips the data foundations supporting them. While many organizations are eager to move models into production, they are often building on fragmented, poorly governed data, effectively scaling risk rather than competitive advantage. As these systems transition to live decision-making workflows, any data failure immediately translates into business, regulatory, and trust failures.
Data governance for AI establishes control over how data is sourced, validated, structured, and consumed across both training and real-time inference. Weak governance is frequently cited as a contributing factor in failed AI initiatives. A recent industry study shows that 75% of organizations admit they lack a well-defined governance foundation for their AI projects. Without this level of oversight, AI systems amplify existing data issues at scale, which turns minor data gaps into production-level failures.
Traditional governance models were built for static, internal datasets and periodic oversight. AI systems now depend on continuous governance that extends to external and real-time data sources used in both training and live inference. Governance is what allows organizations to move from isolated AI experiments to stable, production systems. Here are nine data governance for AI strategies that support long-term reliability and operational control.
What is data governance for AI?
Data governance for AI is a framework for managing data across the full AI lifecycle from initial ingestion to final inference. It establishes rules for handling data to ensure that the responses produced by models are grounded in verified, authorized, and representative information.
Unlike traditional governance, which often treats data as static assets, data governance for AI treats data as dynamic. It must be managed through a continuous loop of training and real-time application.
AI data governance establishes lifecycle control over training and inference data. It defines how data is collected, classified, ingested, structured, validated, and accessed at every stage of the machine learning pipeline, whether the data originates internally or from external sources.
In practice, data governance for AI requires:
- Defining approved data sources
- Securing legal rights of use for AI
- Tracking which data informs live model decisions
- Assigning ownership of AI-critical datasets
- Archiving or deleting data when consent is withdrawn
Who relies on data governance for AI?
Data governance for AI connects model development with oversight of data sourcing and use:
- AI/ML teams can use it to ensure they build models on reliable, high-integrity foundations.
- Security leaders can use data governance to protect against data poisoning and leakage of proprietary information.
- Compliance stakeholders and executive leadership can also use AI data governance to ensure the organization meets legal requirements such as the EU AI Act by governing how training and inference data is handled across the AI lifecycle.
What are the 7 core elements of data governance for AI?
To build a production-ready AI system, you need a structured environment where data is treated as a high-stakes asset. Here are the core elements that form the backbone of data governance for AI:
1. Data Quality and Freshness
Data quality ensures that training and inference inputs are accurate, complete, and structurally consistent. Freshness prevents model drift, where an AI’s performance degrades because it is making decisions based on stale or infrequently updated information, particularly when external data sources are refreshed on a different schedule than the model assumes.
2. Data Lineage and Traceability
Lineage allows teams to track how data moves through the machine learning pipeline. Traceability ensures that model outputs can be linked back to the data that informed them, which is vital for debugging errors and providing explainability for AI-driven decisions.
3. Access Control and Permissions
Access controls and permissions restrict who can access AI training and inference data and under what conditions. They reduce the risk of sensitive personally identifiable information or proprietary data being exposed or incorporated into models without authorization.
4. Compliance and Regulatory Alignment
Data governance for AI aligns data practices with applicable regulatory frameworks such as the GDPR and CCPA. It ensures that training and inference data comply with the relevant standards throughout the AI lifecycle.
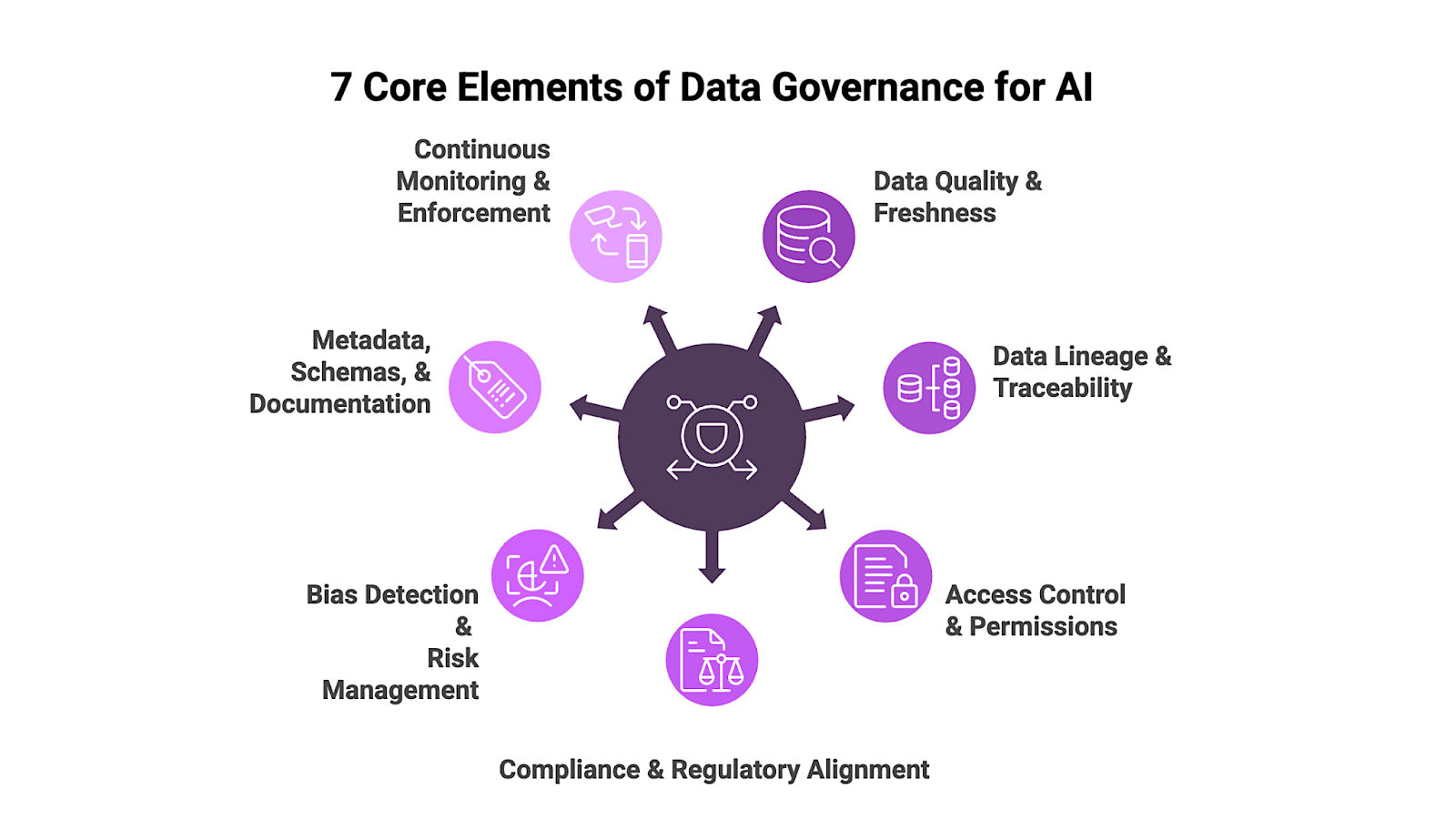
5. Bias Detection and Risk Management
Proactively auditing datasets for underrepresentation or skewed patterns helps detect and mitigate bias before it enters model training and inference. Risk management requires defining acceptable data standards and correcting datasets that fall outside those standards before they are used in production.
6. Metadata, Schemas, and Documentation
Metadata captures key attributes about a dataset, including its source and format, while schemas formally define its structure and field types. Documentation provides the context needed for consistent interpretation to ensure that both humans and AI models handle data correctly.
7. Continuous Monitoring and Enforcement
Continuous monitoring detects changes in data sources, schema structures, or access patterns, while enforcement mechanisms prevent non-compliant or degraded data from entering training and inference workflows.
For example, if an external product feed silently drops a required pricing field or modifies its schema, monitoring systems should flag the deviation and fail the ingestion or feature materialization job before the dataset is committed to the feature store or training pipeline. Without automated enforcement, these changes can propagate into models and degrade output quality before teams detect the root cause.
AI engineering teams typically implement monitoring through schema validation frameworks such as JSON Schema or Protobuf validation, data quality platforms such as Great Expectations or Soda, and pipeline-level observability integrated into orchestration systems like Airflow, Dagster, or managed ML platforms.
These validation layers should be integrated directly into ingestion and feature pipelines so that failed checks automatically trigger quarantining, rollback, or alerting workflows rather than relying on manual review.
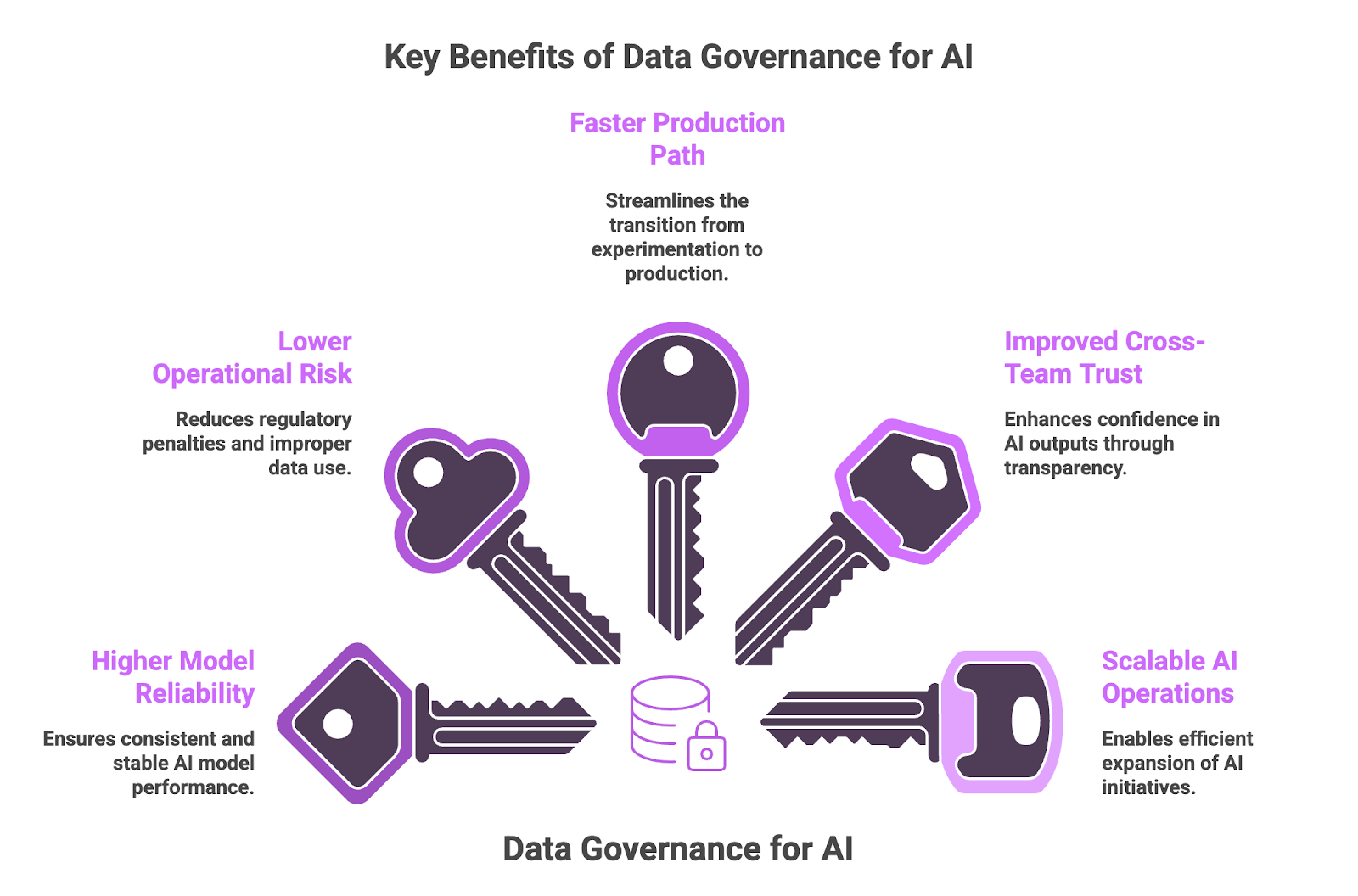
What are the key benefits of data governance for AI?
Data governance offers many benefits for AI models, including:
- Higher Model Reliability – When training and inference data are governed, models perform more consistently in production. Reliable inputs lead to more stable outputs and reduce unexpected performance shifts over time.
- Lower Operational and Compliance Risk – Clear governance reduces exposure to regulatory penalties and improper data use. It also provides documented oversight that strengthens audit readiness and supports defensible AI deployment decisions.
- Faster Production Path – Many AI projects stall because data standards are unclear or inconsistent. Established governance removes that friction, allowing teams to move models into production without reworking data pipelines late in the process.
- Improved Cross-Team Trust in AI Outputs – Transparency around data sourcing and usage makes AI outputs easier to evaluate. Business stakeholders gain visibility into how models are informed, which increases confidence in operational decision-making.
- Scalable AI Operations – As AI initiatives expand, governed data practices prevent teams from recreating datasets and controls for every new project. Shared standards make it possible to scale AI programs without increasing oversight complexity at the same pace.
9 Data Governance for AI Strategies
Employ these AI data governance strategies to reduce data-related risk in AI training and production deployment:
1. Define Explicit Ownership for AI-Critical Data
Assign specific individuals or business units formal responsibility for datasets used in AI training and real-time inference. Ownership should extend across the complete data lifecycle, from ingestion through retirement. When datasets lack clear accountability, quality and privacy controls degrade over time, increasing the risk of model instability and misuse.
How to Implement:
- Create an AI data asset register that links every model to a designated data owner.
- Require owners to approve data freshness standards and usage policies before datasets are introduced into production workflows.
- Require periodic review of AI-critical datasets before retraining or model updates to confirm they still meet defined quality and usage standards.
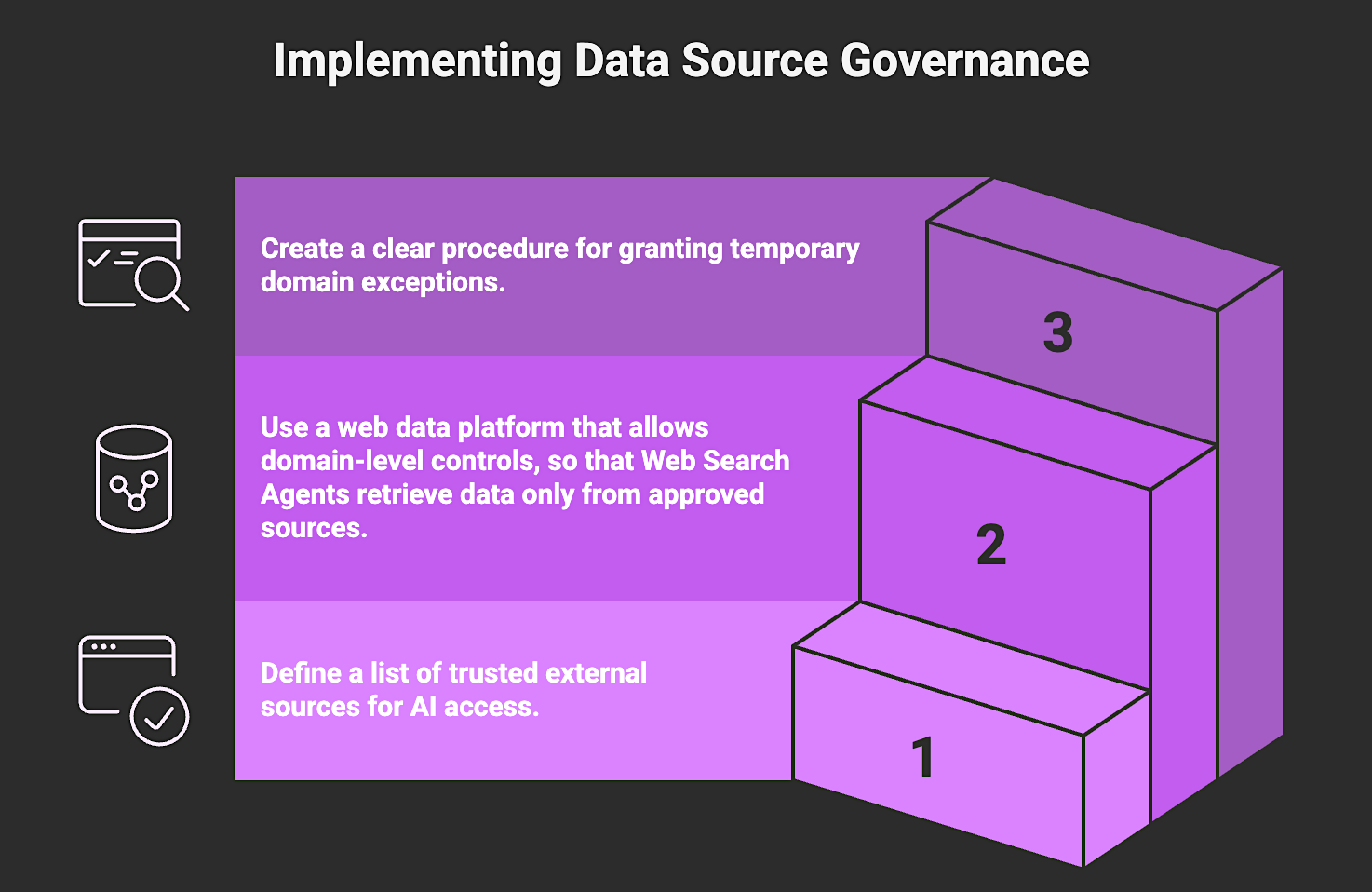
2. Govern External Data Sources and Domain Access
Governing external data sources means defining and enforcing clear controls over which public web sources AI systems are permitted to access and how that data is retrieved. This includes approved domains, allowed content types, retrieval frequency, geographic targeting, and required validation standards before external data is incorporated into training or real-time inference workflows.
Without formal source governance, AI systems may ingest unreliable, outdated, or non-compliant content. Ingesting uncontrolled external data increases operational risk, weakens audit defensibility, and makes it difficult to explain or justify model decisions that depend on dynamically retrieved external data. Explicit source controls ensure that all external inputs are intentional, reviewable, and aligned with compliance and risk requirements.
How to Implement:
- Define and document an approved allowlist of external domains and data sources aligned with your use case and regulatory obligations.
- Restrict retrieval by approved URL patterns, content types, geographic parameters, or source categories where necessary.
- Document expected update frequencies for each approved source and align retrieval timing with those schedules.
- Capture and store retrieval provenance at ingestion, including resolved URL, timestamp, query context (if applicable), and extraction logic version.
- Establish a documented change-control process for adding, modifying, or temporarily approving sources, including an assigned owner and review criteria.
3. Establish Data Versioning and Snapshot Control
Data versioning and snapshot control require that every model training run be tied to a fixed, immutable dataset or feature set captured at a specific point in time. Each training cycle must be associated with an identifiable dataset state and versioned feature definitions so the exact inputs used to produce a model can be retrieved and reproduced.
Without explicit version control over datasets and feature definitions, model behavior cannot be deterministically reproduced. The absence of reproducibility slows performance investigations and limits the organization’s ability to defend model decisions, support audit or regulatory review, or execute controlled rollbacks in production.
How to Implement:
- Create immutable dataset or feature snapshots for each training cycle and retain them under defined governance and retention policies.
- Record dataset version identifiers, artifact locations, table versions, or cryptographic hashes in experiment tracking systems alongside the associated model version.
- Version feature definitions and transformation logic so that changes to feature engineering are explicitly tracked and reviewable.
- Freeze training datasets at job execution time to prevent background data updates from altering dataset composition during model training.
- Document and test rollback procedures that allow teams to redeploy a prior approved dataset–model pairing if new data introduces instability, bias shifts, or compliance exposure.
4. Standardize Analysis-Ready, Structured Data Outputs
Standardizing structured outputs ensures that AI systems receive data in consistent, predefined formats across all pipelines. When data enters training or inference workflows in raw or semi-structured form that requires additional parsing, downstream processing becomes inconsistent and harder to govern.
How to Implement:
- Define required schemas and field-level standards for datasets used in AI training and deployment.
- Version schema changes and document them so training and inference workflows can track structural updates over time.
- Utilize a web data platform that delivers externally sourced data as structured, analysis-ready outputs compatible with governed AI workflows.
5. Implement Continuous Data Validation
Continuous data validation is the process of automatically verifying that data meets predefined structural and statistical requirements before it is used in training or live inference. It establishes explicit acceptance criteria for AI-critical datasets and enforces those criteria directly within ingestion and feature pipelines.
AI systems depend on inputs that can change without notice. External sources may alter schemas, internal transformations may introduce null values, and upstream updates may shift feature distributions. Without enforced validation, these issues propagate into feature stores and model workflows, increasing the risk of degraded performance, bias shifts, and production instability.
Structural validation addresses whether data is correctly formed and logically acceptable. For example, a product ingestion workflow may require that every record includes a valid identifier, a numeric price greater than zero, and an approved currency value. If a rule fails, the ingestion job stops and the affected batch is blocked from reaching the feature store.
Teams enforce structural validation using schema frameworks such as JSON Schema, Avro, or Protobuf and rule-based data quality platforms like Great Expectations or Soda embedded in orchestration workflows such as Airflow or Dagster.
Statistical validation addresses whether data remains behaviorally consistent over time. For example, if the average price within a product category has historically remained within a defined range and suddenly deviates significantly, monitoring systems flag the shift before retraining or inference proceeds.
Statistical monitoring is implemented through feature monitoring libraries or ML observability tools integrated into training and inference pipelines.
How to Implement:
- Define explicit structural validation rules for each AI-critical dataset, including required fields, type constraints, value thresholds, and freshness standards.
- Embed schema validation into ingestion and feature materialization pipelines so structural changes automatically fail jobs before data is committed to the feature store.
- Implement statistical monitoring for high-impact features and define quantitative thresholds that trigger investigation before retraining or production inference continues.
- Configure pipelines to quarantine invalid batches and trigger automated alerts rather than allowing downstream AI processes to proceed.
- Use Nimble’s Web Search Agents to maintain continuous validation of external data. They apply built-in validation layers and self-healing extraction logic to preserve data quality as public web data sources change.
- Log validation results and maintain a history of rule failures and remediation actions to support audit review and root cause analysis.
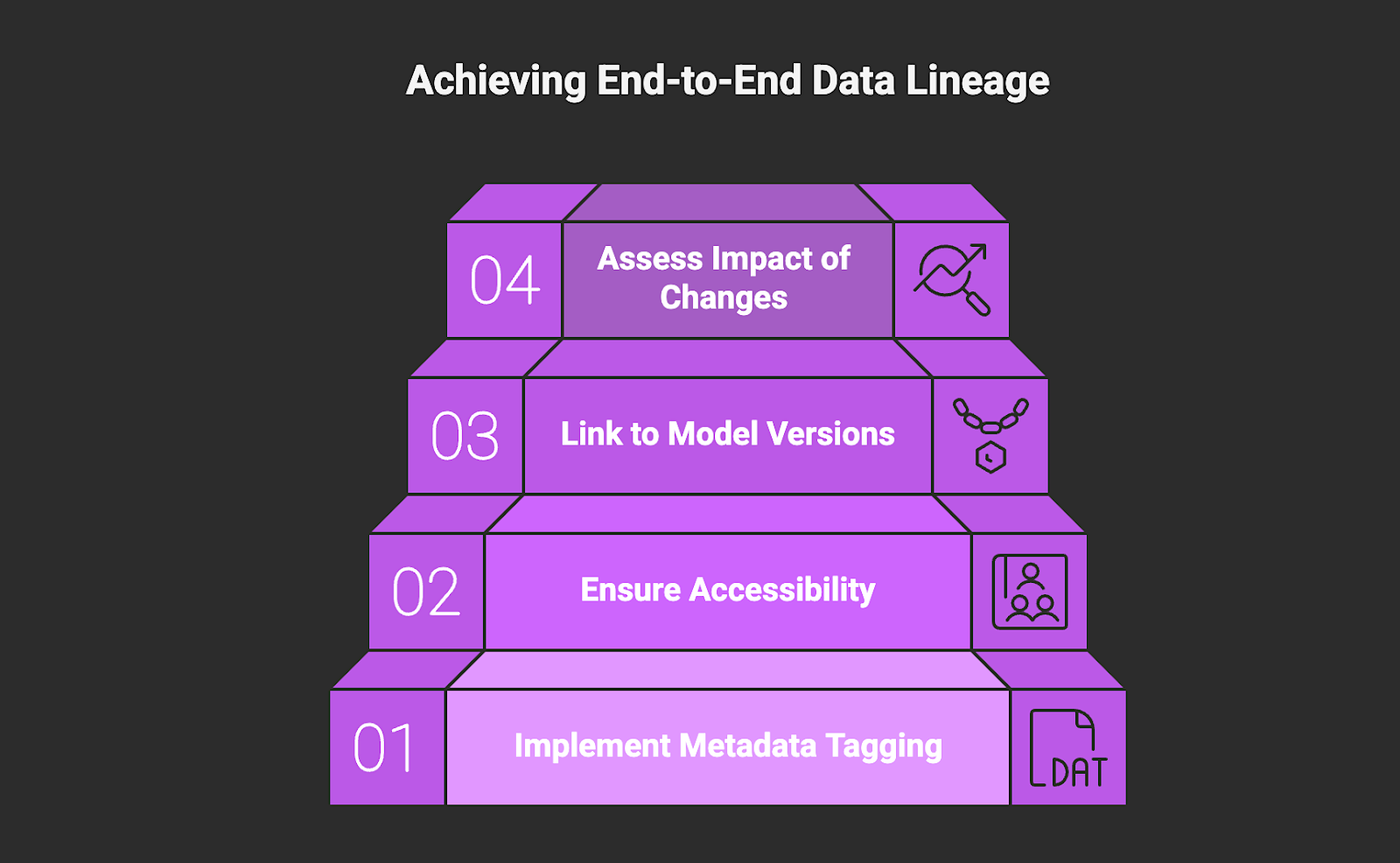
6. Maintain End-to-End Data Lineage for AI
End-to-end data lineage tracks how data moves from its source through transformation and into model training and inference workflows. It provides visibility into which datasets influenced specific model outputs and how those datasets were modified along the way. This level of traceability supports explainability and enables effective audit and investigation when changes affect model performance.
How to Implement:
- Implement metadata tagging that records where data originated and how it was transformed before reaching model workflows.
- Ensure lineage records are accessible to both AI/ML teams and governance stakeholders responsible for oversight and audit review.
- Link lineage records to specific model versions and deployment cycles so governance teams can trace which datasets influenced particular production outputs.
- Assess the impact of significant dataset changes before retraining or redeploying models to understand how updates may alter system behavior or risk exposure.
7. Enforce Fine-Grained Access Controls for AI Data
AI systems should only access the data they are explicitly authorized to use. Fine-grained access controls apply the principle of least privilege to AI training and inference workflows, limiting dataset access based on defined roles and approved use cases. Without these controls, sensitive information such as PII can be incorporated into models unintentionally.
How to Implement:
- Separate experimental data environments from production environments to prevent unintended data crossover.
- Apply data masking or anonymization to sensitive fields used in model development and testing.
- Define role-based access policies that restrict dataset usage to approved teams and AI workflows.
- Monitor dataset access activity to ensure usage remains aligned with defined roles and approved AI workflows.
8. Align Data Governance with AI Regulatory Requirements
Data governance for AI must align internal data practices with regulations such as the GDPR and support compliance with system-level obligations under the EU AI Act. These frameworks influence how training data is sourced and retained within AI systems. Embedding compliance considerations into governance policies from the outset reduces rework and allows AI systems to move into production without avoidable delays.
How to Implement:
- Conduct Data Protection Impact Assessments for new AI use cases involving sensitive or high-risk data.
- Ensure your web data provider collects only publicly available data and maintains alignment with applicable data protection regulations.
- Maintain records of how data is sourced and retained so the organization can demonstrate compliance during regulatory review.
- Enforce defined data retention timelines and remove expired or revoked data from training and inference workflows in accordance with regulatory and internal policy requirements.
9. Automate Governance to Support Scale
As AI deployments scale, governance that is not embedded directly into data infrastructure becomes inconsistent and difficult to enforce. Automating governance ensures that validation and access controls operate consistently as workloads increase. Without automation, it becomes challenging to govern the data pipelines and controls that support training and inference as AI workloads expand across teams and use cases.
How to Implement:
- Deploy automated tools that scan incoming data for sensitive information and structural inconsistencies before it enters AI workflows.
- Use Nimble’s Web Search Agents to automate the validation, structuring, and delivery of analysis-ready public web data so governance controls remain enforceable at enterprise scale.
- Track measurable indicators such as validation failure rates or schema changes to confirm that governance automation remains effective as workloads expand.
Build Production-Ready AI Through Governed Data
Implementing a robust data governance for AI strategy is essential to moving AI systems from experimentation into reliable, real-world production. These strategies ensure that every piece of information feeding your models is controlled, trustworthy, and aligned with your broader business objectives. However, many governance breakdowns occur at the point of external data collection, particularly when AI systems depend on real-time inputs that may be cached, inconsistently structured, or refreshed on schedules outside the organization’s control.
Nimble solves this by operationalizing data governance for AI with Web Search Agents that collect publicly available web data. The data is delivered as structured, analysis-ready outputs with continuous validation and real-time freshness before it enters your AI pipeline. The result is governed, real-time web intelligence that scales with your AI operations without increasing risk.
Book a demo to see how Nimble helps you build production-ready AI with governed, real-time web data.
FAQ
Answers to frequently asked questions




.png)
.avif)
.png)