6 Tavily Alternatives in 2026 for enhanced web search

Charlie Klein
.png)
6 Tavily Alternatives in 2026 for enhanced web search
Charlie Klein
Most popular articles

Get structured, reliable data for your stack.
6 Tavily Alternatives in 2026 for enhanced web search
Moving AI agents from localized use into a scalable, Cloud-based, production environment remains a significant challenge in 2026. Many production agents need access to current web data. Relying on outdated or unverified data in these workflows is an operational risk that can stall deployments and compromise system reliability.
Tavily, a well-known AI/Agentic search API, is a common starting point for retrieval-augmented generation. But as systems move closer to production, teams start evaluating alternatives when they need stronger guarantees around freshness, structure, and reliability. With industry data showing that 94% of developers would consider switching vendors for stronger agentic AI capabilities, teams have a clear reason to reassess whether their current search API can support production workflows.
This guide compares six API options for AI/Agentic search. We evaluated these Tavily alternatives based on critical buyer priorities such as output format, reliability on complex sites, and token optimization. If you need real-time web data for production agents, start with Nimble; if you're looking for simple search and extraction workflows, try Firecrawl. The goal is to match the API to the job: discovery, research, extraction, private search, SERP data, or production web intelligence.
What is Tavily, and what does it do?
Most search engines prioritize the human eye, but Tavily focuses on the machine. It acts as a bridge for AI agents that allows them to pull real-time data from the web and feed it straight into LLM workflows.
As a dedicated retrieval layer, it streamlines the path from a live query to usable, ingested content. Tavily combines search, light extraction, and basic summarization into a single API call, allowing developers to quickly ground their models in real-time information without building complex AI web scraping infrastructure from scratch.

For many engineering teams, Tavily is the "day one" choice because it excels at providing a low-latency bridge between a prompt and the internet. Tavily is ideal for prototyping. When you need a chatbot to retrieve current external information for grounding or fact-checking workflows, it’s an easy way to accomplish it. It integrates with most orchestration stacks out of the box, so you aren't stuck writing custom scrapers.
When Tavily May Not Be the Right Fit
When AI moves into production, the data needs to change. Simple search works at first, but teams eventually hit a "complexity wall." At that point, standard search results can't keep up with the demands of a high-level agentic workflow, forcing a shift toward more specialized data sources.
Tavily may no longer be the right fit if you require:
- Structured data fields: You need structured, clean data for immediate ingestion.
- Reliable extraction for JS heavy sites: Your agents need deeper extraction across many dynamic or JavaScript-heavy sources
- Fresh data: You real-time web search with data that isn’t cached or indexed
- Production data pipelines: Your agents need to stream web datasets that can be structured, validated, and passed into downstream RAG pipelines or business systems.
Key Terms
In 2026, evaluating the AI/Agentic search API landscape means focusing on the technical benchmarks that actually matter when things scale. Key terms to know include:
- Data Freshness refers to whether a tool retrieves live web data at the exact moment of the request or relies on a cached index. In agentic workflows, "freshness" is the difference between an agent knowing about a market shift that happened five minutes ago versus one that happened five days ago.
- Output Format defines how the data is delivered to your model. While many services return basic links and text snippets, advanced alternatives provide fully structured data (such as JSON) that can be mapped directly to a database schema or used by agents without expensive post-processing.
- Reliability on Complex Sites is a measure of how consistently a tool can navigate the modern web. High-reliability tools can handle dynamic, JavaScript-heavy environments and maintain access across protected websites where simpler APIs are often blocked.
- Setup Effort is the level of technical work required to get an API integrated and returning usable data within an existing AI or agentic stack.
Top Tavily Alternatives by Use Case
- Recommended for production AI agents requiring real-time web data: Nimble
- Recommended for semantic search and research-heavy retrieval: Exa
- Recommended for simple search and extraction workflows: Firecrawl
- Recommended for real-time search and cited research workflows: You.com (YDC APIs)
- Recommended for private, secure search: Brave Search API
- Recommended for structured SERP data extraction: SerpApi
Comparison Table: Best Tavily Alternatives for 2026 Compared
Choosing the right Tavily alternative depends on your specific production requirements, whether you need the massive scale of an independent index, the semantic depth of neural search, or the structured precision of real-time web intelligence. The table below breaks down the top
How We Compared These Tools
We evaluated these Tavily alternatives using a consistent set of criteria so readers can compare them more easily. Everything here is based on what was publicly available on 28 April 2026. We reviewed product pages and API docs for the fine print, but also looked at third-party reviews and comparison sites to see how each tool stacks up against the competition.
What we reviewed:
- Official Sites: We looked at how each vendor actually positions itself in the AI/Agentic search API space.
- Technical Docs: Beyond the marketing, we dug into the API endpoints and how they handle data parsing.
- Pricing & Plans: We checked the fine print on cost to see which ones actually scale based on pricing transparency and plan structure.
- Competitor Comparisons: We analyzed the vendors' own "Us vs. Them" pages to see how they position themselves against Tavily.
- Developer Feedback: We checked third-party reviews and directories to see reported strengths and limitations.
How we compared tools:
We focused on the areas most likely to shape a buying decision, including core web search API capabilities, data freshness, output structure, AI agent and RAG support, coverage of dynamic websites, developer experience, pricing transparency, and overall fit for production use.
We did not run hands-on testing for every tool. If a capability was not clearly documented, or if sources conflicted, we avoided definitive claims and noted the limitation in the write-up.
6 Tavily Alternatives for 2026
General performance alone is not enough for production systems. Once you’re in production with AI models or Agents, architectural fit is what matters. Choosing a Tavily alternative is really about picking your priority, whether that’s the depth of the web crawl, semantic accuracy, or the structural integrity of the data you’re getting back.
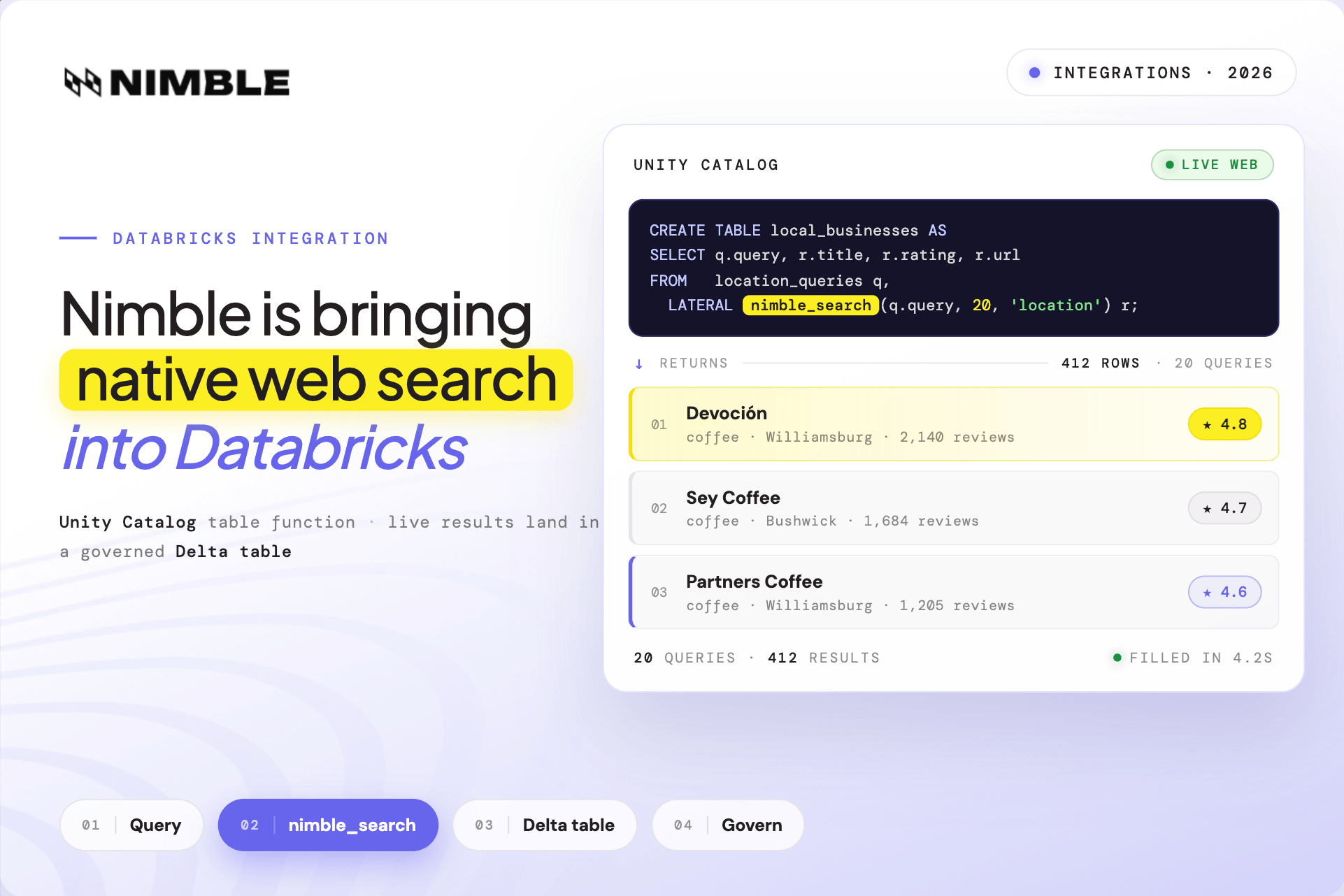
1. Nimble Search API – Recommended for production AI agents requiring real-time web data
Nimble’s Search API provides AI web intelligence for production-scale agentic workflows that need precise, live web data. Instead of relying on pre-built indexes, Nimble uses real-time, browser-based agents to navigate the live web and retrieve structured, ready-for-ingestion data.
Nimble can access dynamic, JavaScript-heavy public web pages that often challenge traditional data collection tools, while reducing the need for extensive post-processing of messy snippets. It provides a reliable AI infrastructure tool for teams that need high levels of data accuracy and freshness for production AI agents.
Key Strengths
- Retrieves live, real-time data instead of relying on outdated indexes.
- Delivers fully structured, schema-based JSON, eliminating the need for expensive LLM post-processing of raw text.
- Uses enterprise-grade scraping infrastructure to support reliable access across JavaScript-heavy and complex websites.
Key Limitations
- Advanced configuration and higher-volume use cases may require custom pricing or enterprise support.
- The rich feature set may be unnecessary for simple RAG experiments that don't require deep site interaction.
Why Choose It Over Tavily
Choose Nimble if you are moving past the prototyping phase and require a "browser-first" approach. While Tavily is useful for retrieval workflows, Nimble is built for teams that need live browsing, structured outputs, and reliable access to complex public websites at production scale.
Pricing
A “pay-as-you-go” free trial is available, with custom pricing available by inquiry and with a demo.
Review
“The technology at Nimble is very effective at scale (we make millions of requests per month) and works for a good number of our use cases. Nimble packs a lot of features and power behind their API and it's pretty easy to use out of the box and we were able to integrate it into our existing scraping operations without much trouble.”
2. Exa – Recommended for semantic search and research-heavy retrieval
Exa (formerly Metaphor) is a neural AI web search engine that uses an embedding-based index to understand the semantic intent of a query rather than just matching keywords. It is designed for AI consumption, prioritizing semantic relevance over keyword matching.
The API is ideal for research tasks that require finding high-quality, semantically similar content across the web, making it a favorite for RAG pipelines that prioritize context and relevance over broad SERP data.
Key Strengths
- Exceptional semantic precision; it finds high-quality links that keyword-based engines often miss.
- Returns content that can be used for embedding and vector database integration.
- Features a "Find Similar" endpoint to discover content based on existing URLs.
Key Limitations
- Currently text-only with no multimodal support.
- Not intended for deep crawling of a single domain; it is a web-scale discovery tool.
Why Choose It Over Tavily
Choose Exa over Tavily when your agent needs semantic discovery more than general web retrieval. Exa is better suited for finding conceptually related sources, similar pages, and research material where relevance depends on meaning rather than direct keyword matches.
Pricing
Offers a free tier for prototyping (1,000 requests/month); paid plans start at $7/1K requests for standard neural search.
Review
“Exa's strong coverage and flexible API have been a key differentiator for us…The ability to customize search based on the use case easily, is important.”
3. Firecrawl – Recommended for simple search and extraction workflows
Firecrawl is an API-first tool that converts any URL or website into clean, LLM-ready Markdown. The API allows AI agents to search the web and retrieve clean, structured content from results in a single workflow. It is specifically designed to handle the "crawl and convert" pipeline for AI developers, with support for JavaScript rendering and workflows for building knowledge bases from web content.
Key Strengths
- Converts complex HTML into clean Markdown, which is highly efficient for LLM context windows.
- Supports multi-page site crawling with simple API parameters.
- It can be self-hosted via an open-source (AGPL) version for complete data control.
Key Limitations
- Extraction quality can vary depending on page complexity.
- Slower than HTTP-only search APIs because it often renders full JavaScript.
Why Choose It Over Tavily
Tavily works well for broad discovery; Firecrawl is engineered for crawling websites and converting pages into clean Markdown for LLM integration. If the target source is identified, Firecrawl is the more efficient (and simpler) tool for comprehensive page extraction and ingestion, removing the need for manual scraper development.
Pricing
Four flexible plans are available based on credits: Free at 500 credits (one-time); Hobby at $16/3,000 credits/month; Standard at $83/100,000 credits/month; and Growth at $333/500,000 credits/month.
Review
“Started using Firecrawl for a project. Wished I had used this sooner.”
4. You.com Search API – Recommended for real-time search and cited research workflows
You.com’s Search API provides programmatic access to real-time web and news search results optimized for LLM grounding. By delivering structured results with source URLs, the API helps developers build applications that prioritize factual accuracy and transparency. It is a strong fit for developers building AI assistants or research tools that need real-time search results with clear source attribution.
Key Strengths
- Provides high-quality snippets that are optimized for model consumption.
- Offers specialized endpoints for news and real-time events.
- Provides source-linked search results that can support grounding and citation workflows.
Key Limitations
- Consumer-facing roots mean customer support can sometimes be slow for technical API users.
- Credit-based systems can lead to "vanishing credits" if not used within the monthly cycle.
Why Choose It Over Tavily
If your agent needs clear, cited answers, You.com’s Search API is the better move than Tavily. In agentic systems, context quality directly impacts output quality, making reliable, source-linked retrieval critical. It’s a strong fit when source attribution and real-time web or news results are central to the workflow, and saves you from having to build your own summarization and citation logic.
Pricing
The Search API has a free plan to get started, and a base cost of $5.00/1k calls on the paid plan.
Review
“Unlike traditional search APIs that were designed primarily for human consumption and then awkwardly retrofitted for machine use, You.com's Search API was architected from the ground up with retrieval-augmented generation (RAG) pipelines and agentic workflows as the primary use case.”
5. Brave Search API – Recommended for private, secure search
Brave Search is one of the few truly independent search indexes in the world, with over 35 billion pages. Its API provides a privacy-focused search layer for grounding AI models without relying on Google or Bing. It can be a strong fit for security-conscious organizations due to its Zero Data Retention (ZDR) option and privacy-focused search model.
Key Strengths
- Highest level of privacy with options for Zero Data Retention (ZDR).
- Independence from Google and Bing reduces reliance on third-party search scraping and downstream platform dependencies.
- Features a specific LLM Context endpoint that returns pre-formatted data chunks for easier grounding.
Key Limitations
- The standard Web Search endpoint returns index-based snippets and metadata; full-page content extraction requires the separate LLM Context endpoint.
- An independent index may have slightly lower "long-tail" coverage than Google in specific niche categories.
Why Choose It Over Tavily
Brave is built on its own search index rather than scraping Google or Bing. This makes it a strong option for production apps that want an independent index rather than a retrieval layer dependent on third-party search results. It’s especially useful for regulated industries, as its ZDR policy supports compliance and AI risk management by ensuring user data isn't cached or tracked.
Pricing
Transparent pricing at $5 per 1,000 requests for the Search plan.
Review
“The Brave Search API provides accurate search results for our academic citation services. It delivers high-quality data at a reasonable price, and with intuitive data structuring.”
6. SerpApi – Recommended for structured SERP data extraction
If your primary goal is to capture what appears on a search engine results page (SERP), SerpApi is a strong option. It provides structured JSON for organic rankings, paid ads, featured snippets, Knowledge Graph panels, and “People Also Ask” boxes across Google, Bing, and other engines. SEO and marketing teams use it to track keyword rankings across regions, monitor competitor ad strategies, and support AI SEO tool workflows.
Key Strengths
- Extracts dozens of SERP features, including Featured Snippets, Knowledge Graphs, and "People Also Ask".
- Offers granular geolocation (at the zip code level) to see exactly what users in a specific area see.
- Includes a "Legal Shield" to handle the compliance aspects of search scraping.
Key Limitations
- Only provides search engine data; it does not crawl the actual websites listed in the results.
- Higher price-per-query compared to simpler APIs.
Why Choose It Over Tavily
For tasks like competitive analysis or SEO, teams often need structured SERP data rather than general web retrieval. While Tavily handles standard retrieval, SerpApi pulls the specific "search intelligence" data like Knowledge Graphs and local results. It’s the difference between getting a list of links and seeing the actual structure of the SERP.
Pricing
There are six pricing tiers, including a Free plan at 250 searches/month; Starter at $25/1,000 searches/month; Production at $250/15,000 searches/month; and custom pricing for Enterprise.
Review
“Super-easy-to-use Google Sheets and Make.com integration. You can be up and running in an hour or two (by) automating your own ranking reports. Pricing is competitive with other similar products.”
Moving Beyond Search to Web Intelligence
The shift from experimental RAG pipelines to autonomous agentic workflows requires more than just a list of search links. As we have seen throughout this guide, the ideal Tavily alternative depends entirely on your specific production goals. Whether your priority is semantic search, simple crawl-and-extract workflows, private search, cited research, SERP data, or production web intelligence, there is an AI/Agentic search API for every stage of the development lifecycle.
For teams outgrowing basic retrieval experiments, Nimble is an ideal solution. It uses real-time, browser-led access instead of relying on pre-built indexes, helping teams retrieve current public web data. Getting fully structured data back means your production agents can operate with far more reliability than they would with a standard search API. When quality and data freshness are the primary barriers to your production success, moving to a purpose-built web intelligence layer is no longer optional.
Book a demo today to see how Nimble can power your production AI agents with structured, real-time web data.
FAQ
Answers to frequently asked questions
.png)
.png)
.avif)

.png)
.png)