10 AI Data Infrastructure Tools to Add to Your Stack

Tom Shaked
.png)
10 AI Data Infrastructure Tools to Add to Your Stack
Tom Shaked
Most popular articles


Get structured, reliable data for your stack.
The move toward autonomous AI agents has exposed a massive gap in the standard data stack. While the industry shifts toward agentic workflows, many AI teams remain trapped in "scraper debt" by spending more time maintaining brittle web extraction scripts than building core agent logic. When data retrieval fails or returns unstructured noise, even the best AI models will produce unreliable results and hallucinations. This failure creates a quality barrier that prevents many agents from moving into production.
Fortunately, there’s a solution. AI data infrastructure tools are platforms designed to replace these broken workflows in the tech stack with automated pipelines. They focused on two critical needs: the real-time retrieval of live information and the structured extraction of that data into usable formats.
As organizations increasingly look to treat the live web as a governed, queryable database to provide their agents with high-fidelity inputs, the demand for AI data infrastructure is expanding rapidly. The market for these tools is expected to hit $90 billion in 2026 and grow to $465 billion by 2033.
Building a reliable AI data infrastructure stack means moving toward autonomous systems that navigate the web at scale. But sustained success depends on self-healing tools that bridge the gap between raw web sources and AI-ready storage. Establishing this foundation is the first step toward building agentic workflows that are both scalable and production reliable. To help your team build a better tech stack, let’s explore the top ten AI data infrastructure tools and how to choose the right ones for your organization.
What are AI data infrastructure tools?
AI data infrastructure tools are the specialized software components required to collect, clean, and deliver data specifically for AI & LLM model training and real-time inference. Unlike traditional data stacks, this infrastructure is engineered to handle massive-scale unstructured data and high-velocity real-time streams.
These tools function as the essential bridge between "live" external sources, such as the public web, and internal AI systems like Retrieval-Augmented Generation (RAG) or autonomous agents.
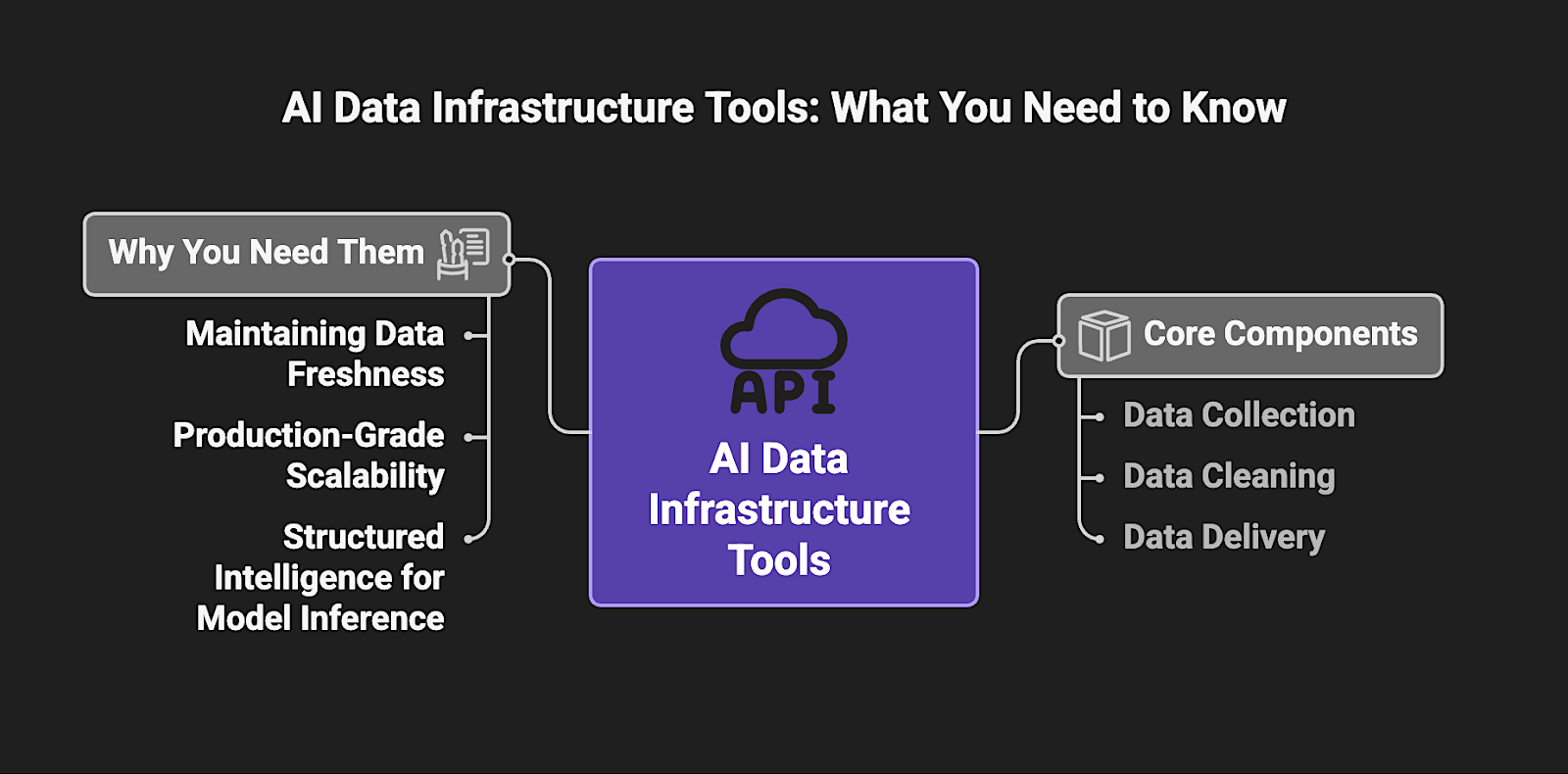
Investing in these specialized tools is essential for:
- Maintaining Data Freshness: Grounding LLMs in real-time external data provides a factual anchor for model reasoning because it ensures agentic outputs remain accurate and relevant as market conditions or web sources shift.
- Production-Grade Scalability: Standardizing the ingestion architecture replaces fragile one-off scripts with resilient pipelines that can handle the high-throughput demands of enterprise-wide deployment without constant downtime.
- Structured Intelligence for Model Inference: Automated extraction normalizes messy, unstructured web sources into machine-readable JSON, which removes the brittle custom-coding bottlenecks that typically disrupt the LLM data loop.
For Data Engineers, AI Architects, and CTOs, AI data infrastructure represents the shift from tactical, one-off data collection to a strategic asset that supports the high-throughput requirements of agentic workflows. Establishing this specialized foundation creates the backbone of enterprise reliability by providing the governed, transparent data flows necessary for rigorous auditability and regulatory compliance.
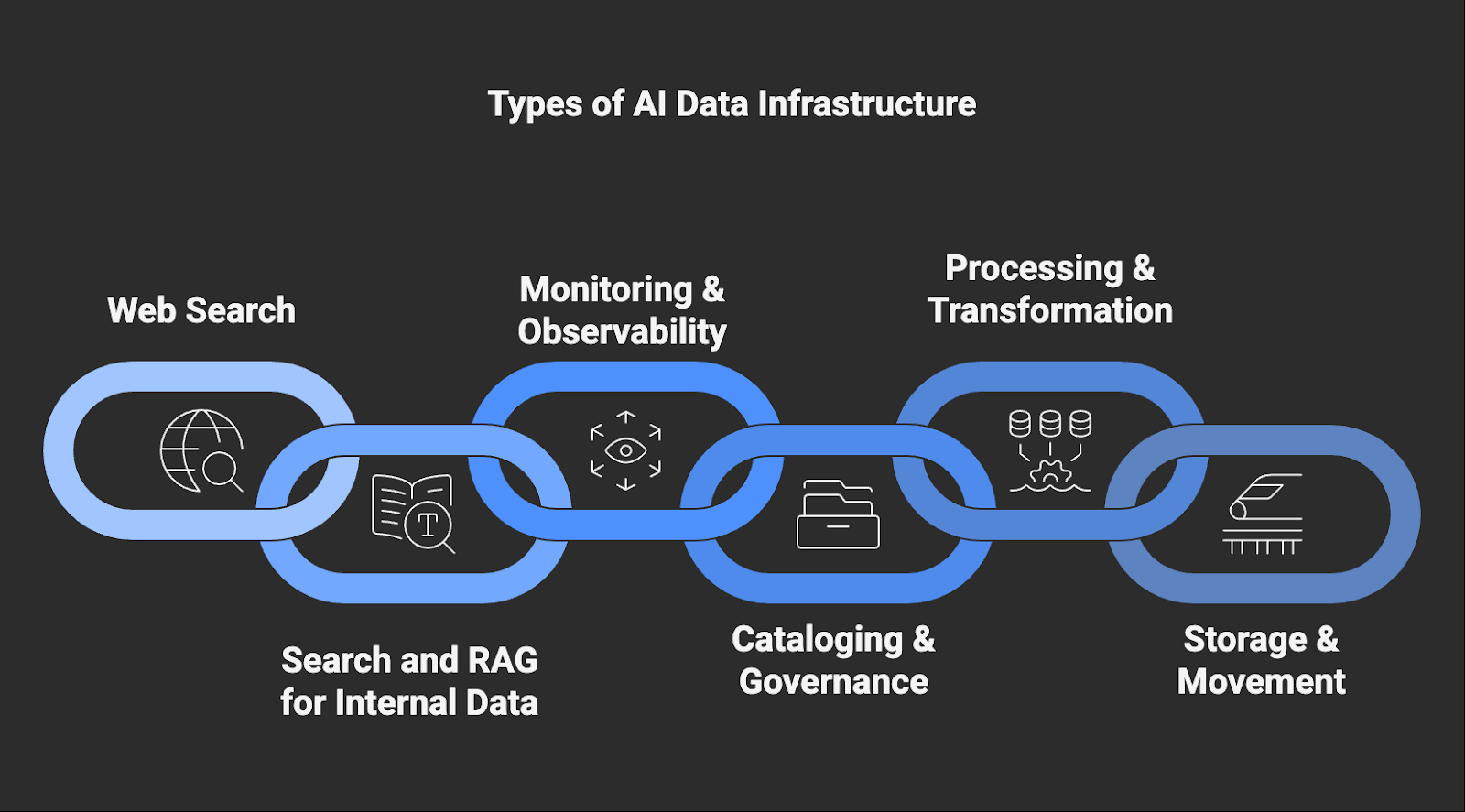
Types of AI Data Infrastructure Tools
Building a production-ready AI stack requires several specialized layers to manage the journey from raw web data to model inference:
- Web Search: Tools and agents that connect AI systems to the live web at request time, enabling access to current external information for LLM grounding, AI search, and autonomous agent reasoning.
- Search and RAG for Internal Data: Systems that retrieve and inject relevant context from internal data sources into LLM prompts to ground responses in proprietary information.
- Monitoring & Observability: Tooling that monitors LLM/app behavior (latency, evals, traces) and data pipeline health (freshness, embedding drift, extraction failures) to prevent silent accuracy regressions.
- Cataloging & Governance: Systems used to organize, label, and track the lineage of data to ensure compliance and auditability.
- Processing & Transformation: Systems that prepare raw or retrieved data for downstream AI and analytics use by cleaning, validating, and converting it into usable formats.
- Storage & Movement: High-velocity data pipelines and vector databases that handle the physical transfer, chunking, and embedding (vectorization) of data to ensure it is indexed correctly for AI retrieval.
5 Key Benefits of AI Data Infrastructure Tools
Implementing AI data infrastructure tools provides several critical advantages across the production lifecycle:
- Maximizes Model Accuracy – Grounding AI reasoning in fresh, extracted data provides a factual anchor that ensures outputs remain accurate as external conditions change.
- Enables Production-Grade Scaling – AI data infrastructure tools maintain consistent performance across enterprise-wide deployments as query volumes and data complexity increase.
- Accelerates Time-to-Value – Pre-built extraction and retrieval layers reduce engineering hours to allow for faster deployment of agentic workflows.
- Lowers Operational Overhead – Automated infrastructure systems eliminate the technical debt and manual intervention required to maintain custom scraping and cleaning scripts.
- Ensures Compliance & Trust – Comprehensive metadata and lineage tracking provide the transparent audit trails necessary for regulatory oversight.
Key Features to Look for in AI Data Infrastructure Tools
When choosing AI data infrastructure tools to add to your AI organization’s tech stack, be sure to consider these criteria:
Top 10 AI Data Infrastructure Tools by Category
Web Search
1. Nimble AI Web Search – Best for Delivering Real-time, Structured Web Data Directly to AI Agents
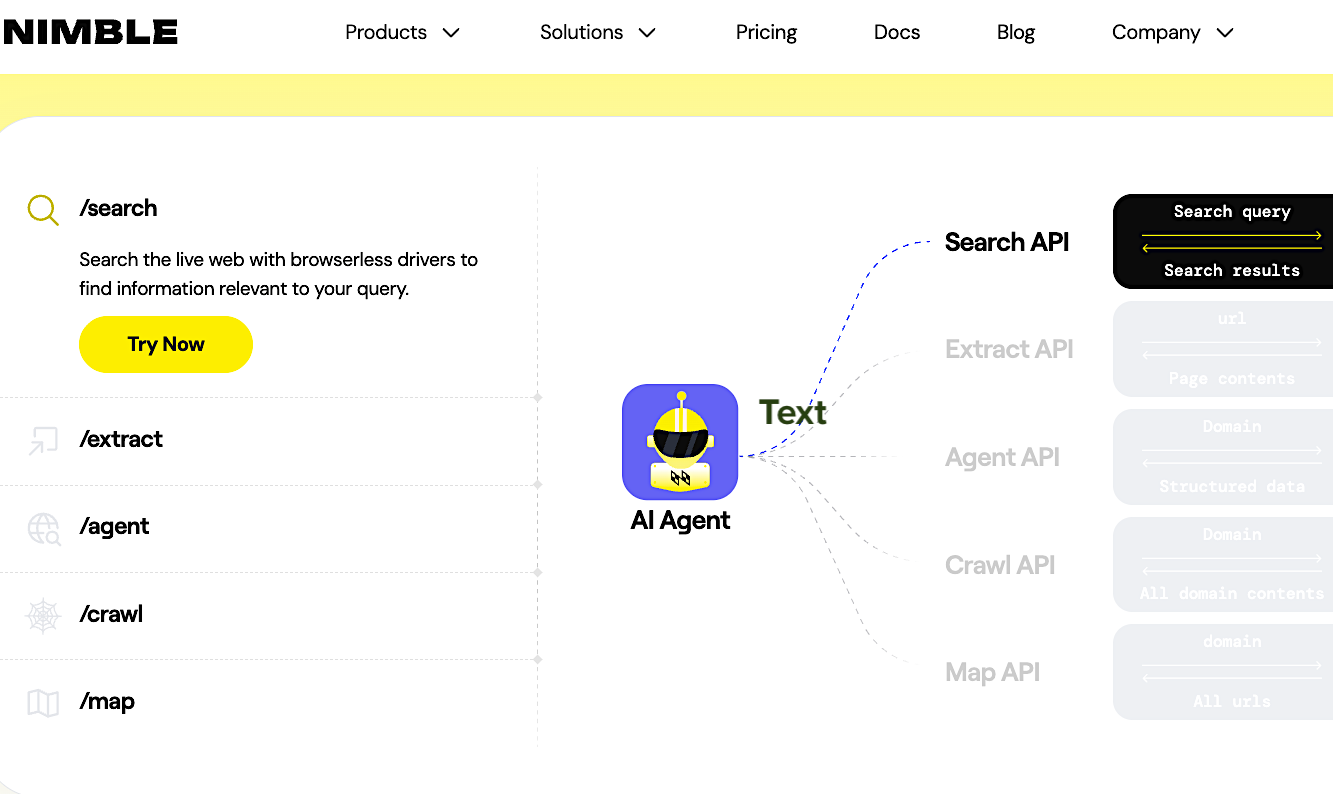
The Nimble AI Web Search API is a specialized retrieval tool that transforms AI agents into real-time web intelligence systems. Engineered for production-grade research and market analysis, it connects LLMs directly to the live web. Unlike tools relying on cached indexes that may offer lower latency for lightweight use cases, Nimble uses headless browsers to navigate websites at request time. This process ensures access to current data, effectively grounding model inference in the most accurate and up-to-date information available.
Nimble differentiates itself by delivering structured JSON rather than unstructured text snippets, which removes the need for downstream parsing logic or additional model calls to extract usable fields. For AI teams deploying agents in production, structured outputs reduce engineering overhead and improve model inference reliability. While indexed tools often provide data that is several hours or days old, Nimble retrieves information directly from the live web to ensure freshness. Its proprietary infrastructure handles complex anti-bot protections and dynamic JavaScript rendering, offering native integrations with major frameworks like LangChain and CrewAI.
Key Features:
- Five Specialized Endpoints: Includes dedicated tools for web search, full-page extraction, domain crawling, URL mapping, and autonomous agents.
- Structured Transformation: Automatically cleans and converts noisy webpage content into itemized JSON fields for immediate machine consumption.
- Real-Time Browsing: Accesses live data at the moment of request to ensure agents never rely on outdated or cached information.
- Query Focus Modes: API parameters that optimize search strategies for specific data types, such as Shopping, Social, News, or Company Research.
- Enterprise-Grade Access: High-performance infrastructure designed to navigate complex sites and render dynamic web applications successfully.
Review: "For our organization, up-to-date financial data is crucial. Nimble API’s intuitive interface made it easy for us to integrate and pull data from multiple sources without the steep learning curve we faced with other tools. It streamlined our data gathering processes, allowing us to adjust strategies in real-time."
Search and RAG for Internal Data
2. Sinequa – Best for Internal Enterprise Search and RAG Across Complex, Multilingual Data Environments
Sinequa is an enterprise AI search and retrieval platform that connects an organization's entire corpus of internal content into a single unified, searchable index. It functions as the retrieval layer that grounds LLM responses in proprietary internal knowledge, enabling employees and AI systems to query across siloed data sources in natural language and receive precise, sourced, and traceable answers. The platform combines semantic search, NLP-based entity extraction, and RAG into a single governed platform designed for large, complex enterprise environments with strict security and compliance requirements.
Key Features:
- 200+ Connectors for Internal Data Sources: Indexes structured and unstructured content across enterprise systems including SharePoint, Salesforce, SAP, and proprietary repositories, without requiring data to be moved or replicated.
- RAG Copilot with Full Traceability: Natural language queries return sourced, contextualized answers with full citation of the underlying documents.
- Automated Content Enrichment: Automatically extracts entities, concepts, relationships, and classifications from documents, audio, and video at indexing time.
- Sovereign and Secure Deployment: Deployable on-premises, in a private cloud, or air-gapped, with granular access controls, SSO, ACL enforcement, and full audit traceability built in.
Review: “It improves engineering timelines, transforms maintenance & support efforts, and accelerates ROI by connecting industrial documents, applications and people.”
3. Nimble Web Search Agents – Best Platform for Streaming Structured Data from Any Site via Autonomous Agents
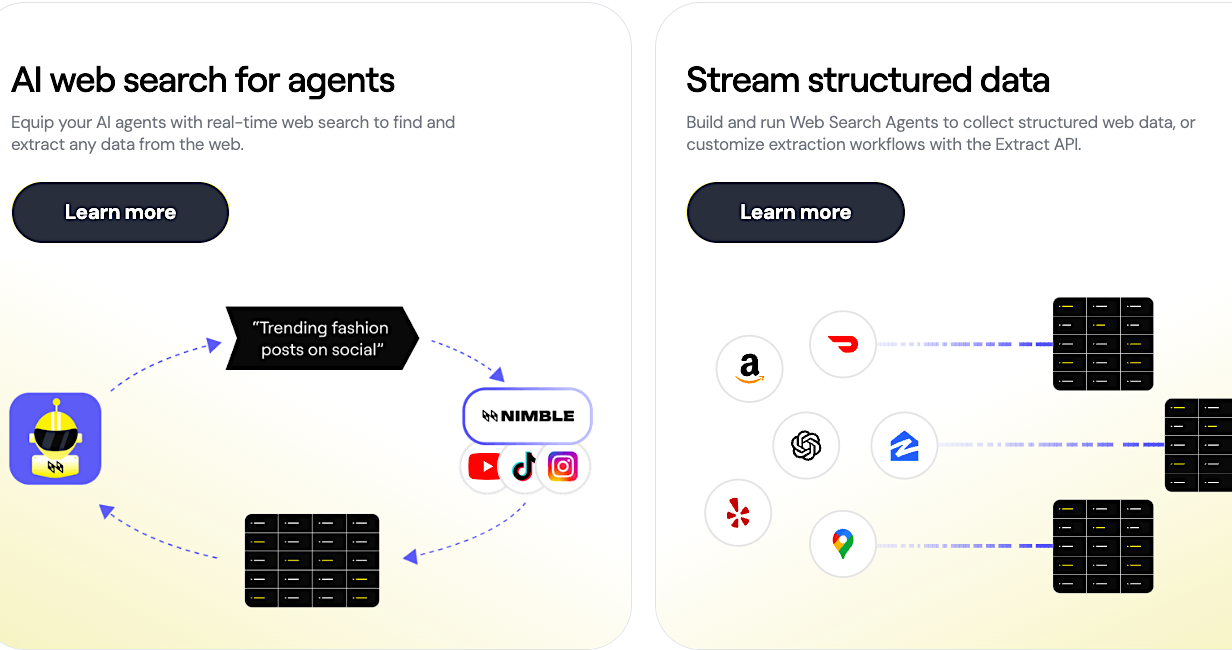
Nimble Web Search Agents are managed, purpose-built autonomous agents that transform the live web into structured, governed intelligence for AI systems and enterprise decision-making. They act as a sophisticated data layer that replaces traditional scrapers and static data vendors by enabling real-time browsing, rendering, and extraction workflows that produce current, reliable data.
The platform operates through a four-step autonomous process designed to deliver high-quality data without manual intervention. First, the agents spin up headless browsers to navigate the live web as a human would, rendering complex pages and executing JavaScript to capture dynamic content. Next, rather than querying a static index, the agents browse the web at request time to ensure data freshness (typically 0–5 seconds old).
Then, the system's parsing engine transforms messy HTML and raw web content into analysis-ready JSON, which reduces latency, operational costs, and the risk of hallucinations. Finally, a dedicated validation layer performs anomaly detection and data cleaning to ensure accuracy before streaming the results directly into infrastructure like Databricks, Snowflake, or S3.
Key Features:
- Self-Healing Capabilities: Unlike brittle DIY scripts, these agents are engineered to automatically adapt to changes in a website’s structure, drastically reducing engineering maintenance overhead.
- Focus Modes: Domain-specific search agents optimized for specialized categories, including Shopping, Social, News, and Company Research.
- Depth Control: Users can choose between Fast Search for rapid lookups or Deep Search for comprehensive full-page content extraction.
- Enterprise-Grade Resilience: A proprietary residential IP proxy network and high-performance JS engine bypass anti-bot protections and access complex sites that block other crawlers.
- Automated Data Streaming: Scheduled delivery and continuous data streaming are supported to eliminate batch-style ingestion delays.
Review: "Nimble’s data platform met our massive data needs out of the box, feeding our large Language models with relevant, high-quality data. This scalability has been crucial in developing more robust and reliable AI systems."
Monitoring & Observability
4. Arize AX – Best for Tracing Agent Reasoning and Evaluating LLM Performance in Real-time
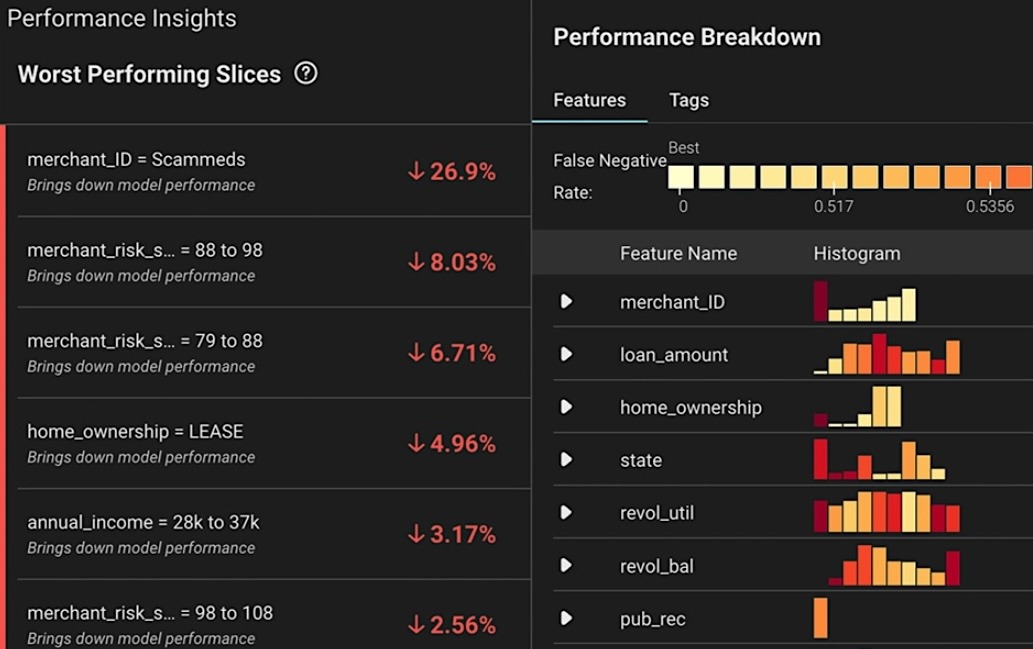
An enterprise AI and Agent engineering platform, Arize AX offers a unified environment for the development, observability, and evaluation of AI applications. It is designed to close the loop between development and production by ensuring that real production data informs a continuous, data-driven iteration cycle. Built on OpenTelemetry (OTEL) and OpenInference conventions, Arize traces agents and frameworks with high speed and flexibility. Its evaluation models and libraries are open-source, which allows engineers to apply them with total transparency.
Key Features:
- Real-Time Evaluations: The platform utilizes Online Evals (AI evaluating AI) and LLM-as-a-Judge to automatically assess prompts and agent actions at scale, and catch problems instantly in production.
- Prompt Management & Serving: There’s a developer-focused playground environment to manage, replay, and perfect prompts.
- Optimized Data Foundation: The system supports real-time ingestion and sub-second queries that enable observability and evaluation at a petabyte scale, and features a purpose-built datastore optimized for generative AI workloads.
- Agent Tracing & Debugging: The reasoning and execution flow of complex AI agents can be visualized to pinpoint failure modes.
Review: "The platform's ability to provide actionable insights into model drift, data issues, and performance degradation is particularly impressive."
Cataloging & Governance
5. Atlan – Best for Active Metadata Management and Automated AI Data Lineage
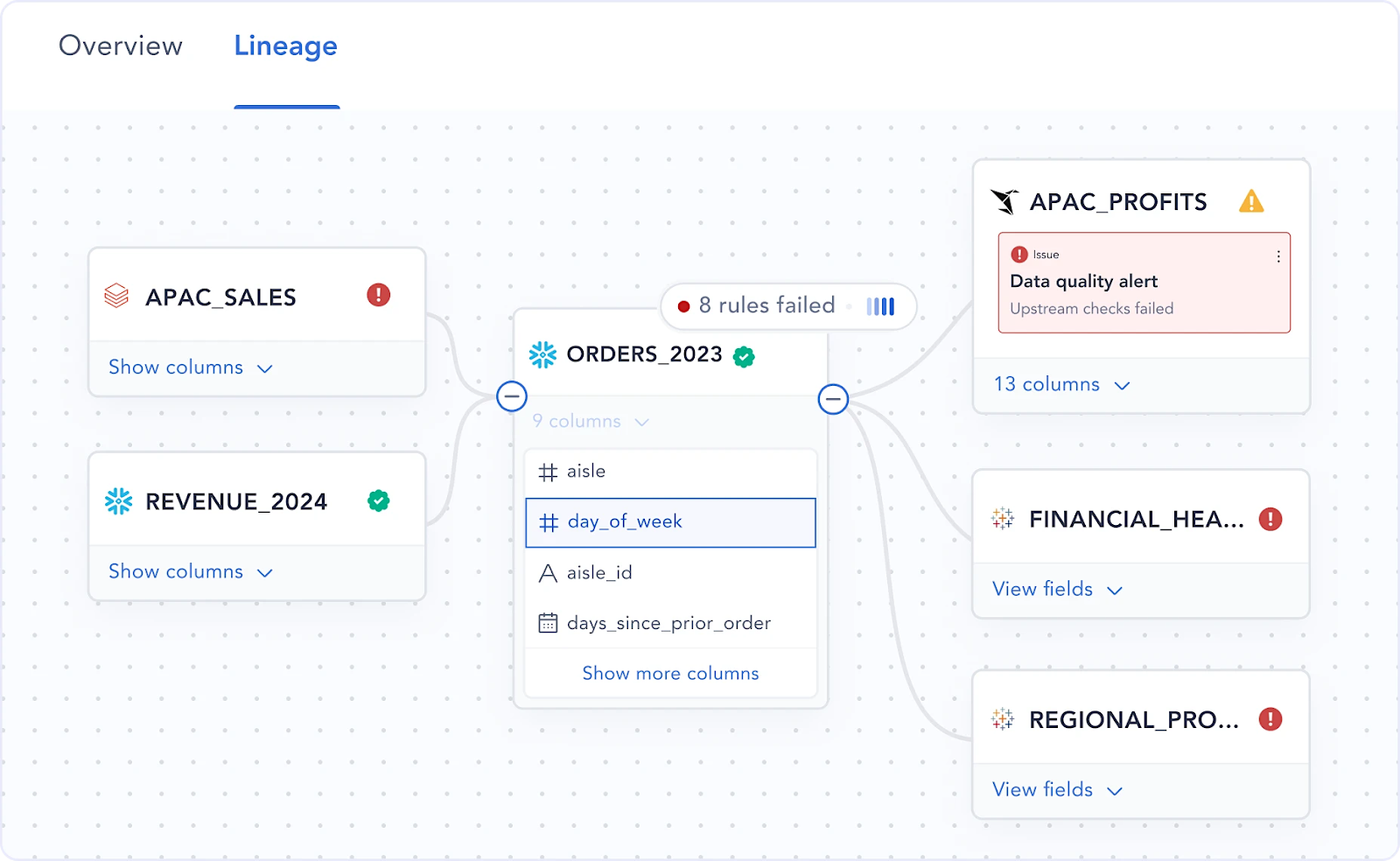
Atlan is an AI-native governance, catalog, and metadata platform described as the "missing context layer" for data and AI. It organizes and tracks data by acting as a metadata plane that sits across the tech stack, independent of where specific data resides. The platform builds column-level lineage to help both humans and AI understand exactly how data flows and how it is transformed, then uses DIY, no-code connectors to ingest metadata from diverse systems and create a single source of truth for all data and AI assets.
Key Features:
- Intelligence & Automation: The platform uses AI-powered and rule-based automations to scale metadata enrichment, ensuring that labeling and documentation are kept up-to-date without manual intervention.
- Context Activation: Through its Metadata Lakehouse and MCP Server, Atlan pushes this context directly into human and agentic AI experiences, such as AI agents, Slack, and GitHub.
- Data Products & Contracts: It includes tools for designing, developing, and scaling data as a product with clear definitions and quality standards.
- AI & Data Governance: The platform enables a comprehensive framework for security, compliance, and data quality management across the organization.
Review: "We’re defining our Data Governance and Data Product frameworks, and designing, developing, and scaling our data products, all with the use of Atlan."
6. Collibra – Best for Enterprise-scale Data Governance and Regulatory Compliance
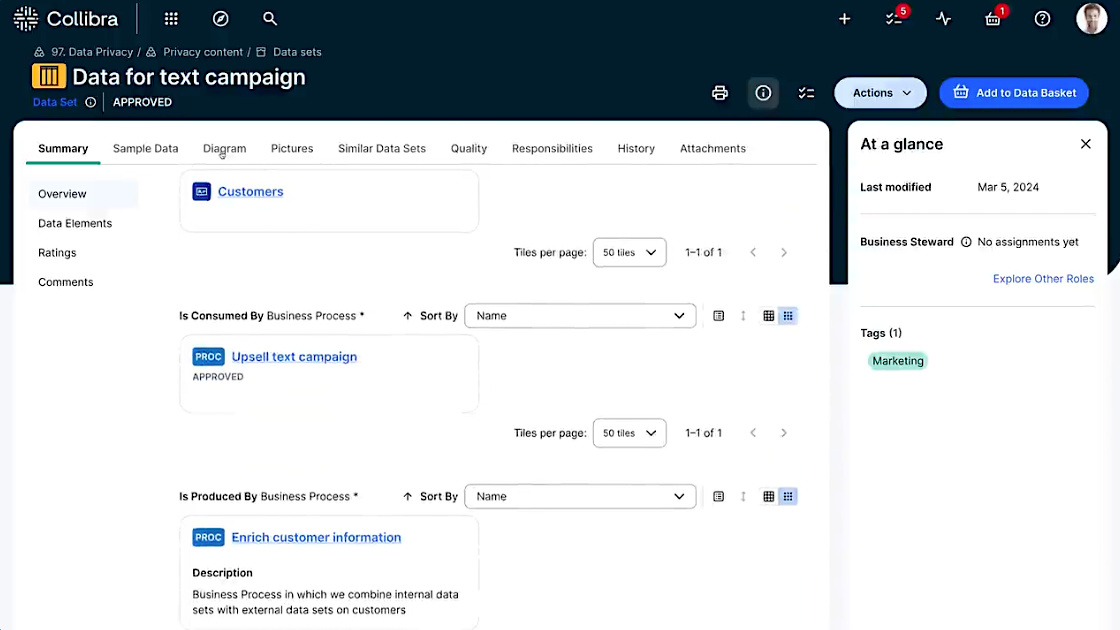
Collibra’s Data Intelligence platform operates as a "single system of engagement" that’s designed to help organizations deliver high-quality data and reliable AI. It provides governance, cataloging, and necessary quality layers to productionize AI use cases across a complex enterprise landscape. Collibra increases transparency into the data landscape to maximize usage while minimizing risk, while using no-code and self-service rules to continuously monitor data health and validate data quality.
Key Features:
- End-to-End Lineage: The tool visualizes how data flows, transforms, and is used across the entire data landscape, providing an integrated view that reduces compliance risk.
- Collaborative Access: It enables business-led collaboration, allowing teams to find, understand, and curate trusted data products quickly.
- Regulatory Specialization: It helps organizations comply with global regulations like BCBS 239 and Solvency II by automating risk reporting across every data source.
- Business Glossary: Standardizes data definitions across the enterprise to improve discoverability and common understanding.
Review: "It provides transparency, clear ownership, and a structured approach to managing data across the organization, while also supporting collaboration between business and IT."
7. Alation – Best for Collaborative Data Discovery through AI-driven Universal Search
The Alation Agentic Data Intelligence Platform is a data knowledge layer designed to scale and accelerate the delivery of AI initiatives by ensuring they are built with trusted data. It acts as a unified hub where cataloging, governance, lineage, and quality converge to transform siloed data into AI-ready assets. The platform unifies discovery via an AI-driven universal search that allows users to find data definitions, lineage, and trust signals using natural language. Specialized Alation Agents automate documentation and enforce policies.
Key Features:
- Active Metadata Graph: An Active Metadata Graph and over 120 connectors keep data current across warehouses and BI tools, so that decisions are based on the most recent information.
- Metadata-Aware Chat: Users can ask questions of enterprise data products in natural language. Behind the scenes, agents handle the SQL generation, cite their sources, and display the associated lineage and policies to provide explainable insights.
- Agent Studio: Organizations can build emerging Agents designed to guide human decisions and coordinate actions.
- Automated Data Lineage: The data journey visualizer ensures compliance and audit-ready decisions.
Review: "The stewardship framework, policy center, and data quality integrations provide organizations with a structured, repeatable way to manage data. For teams focused on compliance or consistency across domains, this can be a major advantage."
Processing and Transformation
8. Cribl – Best for Transforming and Normalizing High-Volume Telemetry Into AI-Ready Data
Cribl’s platform has multiple AI data infrastructure functions, but its best use case is as a data transformation and pipeline platform designed for IT and security telemetry. It processes logs, metrics, and traces in-flight before they reach downstream AI and analytics systems. It functions as a universal translation layer between raw data sources and the tools that consume them by routing, reshaping, and reducing telemetry at scale so that only clean, structured, high-signal data arrives at your LLM stack. In the middle of the pipeline, the platform gives teams control over format, schema, and content before data is indexed or embedded for AI use.
Key Features:
- In-Flight Transformation: Rewrites field names, converts formats, and normalizes schemas as data moves through the pipeline, with no post-ingestion cleanup required.
- Noise Reduction and Filtering: Strips blank fields, drops redundant events, and samples metrics before data reaches a vector store or SIEM, reducing embedding costs and retrieval noise.
- PII Masking and Data Shaping: Redacts or masks sensitive fields in-flight, ensuring compliance requirements are met before data is indexed or surfaced in LLM responses.
- Universal Routing: Collect once, fan out to multiple destinations (vector databases, data lakes, and monitoring tools) simultaneously without duplicating ingestion infrastructure.
Review: “If you don't like the way the data looks, just change it. I used to work for the data, now the data works for me!”
Storage & Movement
9. Confluent – Best for Streaming High-Velocity Event Data Into AI Pipelines in Real-Time
Confluent is a fully managed data streaming platform that serves as the high-throughput backbone for moving events from operational systems into the downstream stores and pipelines that feed model inference and RAG retrieval. It sits at the ingestion layer of the AI data stack, ensuring that data arriving at your vector databases and LLM pipelines reflects current state rather than a stale batch export. Confluent adds a fully managed enterprise layer on top of Apache Kafka, the open-source distributed event streaming platform that was originally created by Confluent's founders and is now maintained by the Apache Software Foundation.
Key Features:
- 120+ Pre-Built Connectors: Pulls data from databases, data warehouses, and SaaS applications into streaming pipelines without custom ingestion code.
- Stream Processing with Flink: Built-in Apache Flink integration for filtering, joining, and transforming event streams before they land in downstream AI systems.
- Schema Registry and Stream Governance: Enforces data contracts and tracks lineage across topics, ensuring AI systems receive consistently structured, trusted data at the point of ingestion.
- Multi-Cloud Deployment: Runs across AWS, Azure, and GCP with cluster linking that mirrors topics across environments, keeping AI pipelines consistent regardless of where data originates or where models are hosted.
Review: “I also appreciate how Confluent offers a scalable and reliable solution for data streaming in my company, which allows me to integrate it smoothly with other platforms within my IT ecosystem…”
10. Informatica – Best for Orchestrating Complex Multi-cloud ETL and Enterprise Data Movement
The Informatica Intelligent Data Management Cloud (IDMC) is a comprehensive, AI-powered platform that manages the entire data lifecycle, from ensuring data health and trust to supporting enterprise-level AI use cases. An orchestration layer for multi-cloud and hybrid environments, Informatica facilitates enterprise data movement and ETL (Extract, Transform, Load) by leveraging AI to automate labor-intensive tasks and simplify data access. It utilizes over 50,000 metadata-aware connections to integrate data across diverse systems and clouds.
Key Features:
- API & App Integration: The platform allows APIs to connect, automate, and streamline data flows between various applications.
- End-to-End Orchestration: Beyond simple transfer, it cleanses, ingests, and integrates data while simultaneously applying governance and quality rules.
- AI Agent Engineering: Custom AI agents and agentic workflows can be built and managed in a dedicated environment.
- Data Quality & Observability: Real-time monitoring and validation ensure data trust and accuracy for AI models.
Review: "It automates and manages complete ETL processes, and is built to handle huge volumes of data with features like data partitioning and pushdown optimization."
Scaling with Structured Intelligence
Production-grade AI requires a unified stack of AI data infrastructure tools that spans retrieval, structured extraction, cataloging, governance, storage, movement, and observability. Successful implementation depends on selecting specialized providers that can bridge the gap between raw web sources and AI-ready storage, and ensure that data is both fresh and governed.
Nimble consolidates two critical layers of the AI data stack by offering powerful tools for both retrieval and structured extraction. The Nimble AI Web Search API enables real-time retrieval of structured, analysis-ready web data to improve model factuality, while Nimble Web Search Agents provide autonomous extraction through self-healing technology that streams cleaned data directly into enterprise storage. Combining live web discovery with automated data streaming, the platform eliminates the heavy maintenance overhead and technical debt inherent in legacy scraping.
Book a demo to discover how Nimble’s AI data infrastructure tools allow you to scale with structured intelligence.
FAQ
Answers to frequently asked questions

.png)

.png)
.png)
.avif)