Top 9 AI Enterprise Search Solutions for 2026

Tom Shaked
.png)
Top 9 AI Enterprise Search Solutions for 2026
Tom Shaked
Most popular articles


Get structured, reliable data for your stack.
Enterprise AI systems are only as reliable as the data they can access. LLMs may be powerful, but static training data is not enough for enterprise tasks that depend on current business context. When an enterprise agent needs access to live web pricing or the latest update inside a private company system, it needs a retrieval layer that can access that data in real-time.
But if that layer does not deliver current, usable context, the system has to respond without the information the task requires. Without fresh, accessible data, business AI is more likely to hallucinate, miss important facts, or fail in production.
AI Enterprise Search Solutions remedies that issue by acting as the automated retrieval layer between AI systems and the data they need. They bridge the context gap by connecting models to scattered internal data and live public web data, then translating that information into formats AI systems can use. The context gap is already affecting enterprise AI in production, with at least 50% of Gen AI initiatives abandoned last year in large part due to poor data quality.
For agent builders, production-grade AI depends on retrieval that is current, reliable, and frictionless. The strongest platforms retrieve fresh information at request time and deliver it in structured outputs that fit directly into workflows. They also solve different retrieval problems based on the data source and the job the system needs to perform. Let’s take a closer look at the top AI enterprise search solutions for 2026, categorized into four distinct architectures.
Top 9 AI Enterprise Search Solutions for 2026 [by Category]
Enterprise Search (Internal)
- Best for unifying internal apps: Glean
- Best for AI-driven internal & external portal search: Coveo
AI Search APIs
- Best AI web search API for live web browsing and structured JSON delivery: Nimble
- Best for quick RAG integration & text summaries: Tavily
- Best for semantic, neural-based web discovery: Exa
Real-Time Web Search
- Best for cited, conversational web research: Perplexity (Enterprise)
- Best for customizable, privacy-first search modes: You.com
Infrastructure (Vector / Hybrid)
- Best for scalable hybrid search architecture: Elasticsearch
- Best for vector infrastructure powering custom semantic search: Pinecone
What Are AI Enterprise Search Solutions?
AI enterprise search solutions are retrieval systems that connect LLMs to internal company data or the live public web. Their job is to retrieve, extract, and format current information into outputs that models, AI data pipelines, or internal knowledge bases can use.
Used by teams running production AI systems, especially AI engineers, agent builders, and data teams supporting those workflows, these solutions are crucial because model quality depends on retrieval quality. When an LLM is grounded in stale or incomplete data, output quality drops and hallucination risk rises. Effective AI enterprise search reduces that risk by closing data freshness gaps, connecting siloed information, and making retrieved context usable inside production workflows.

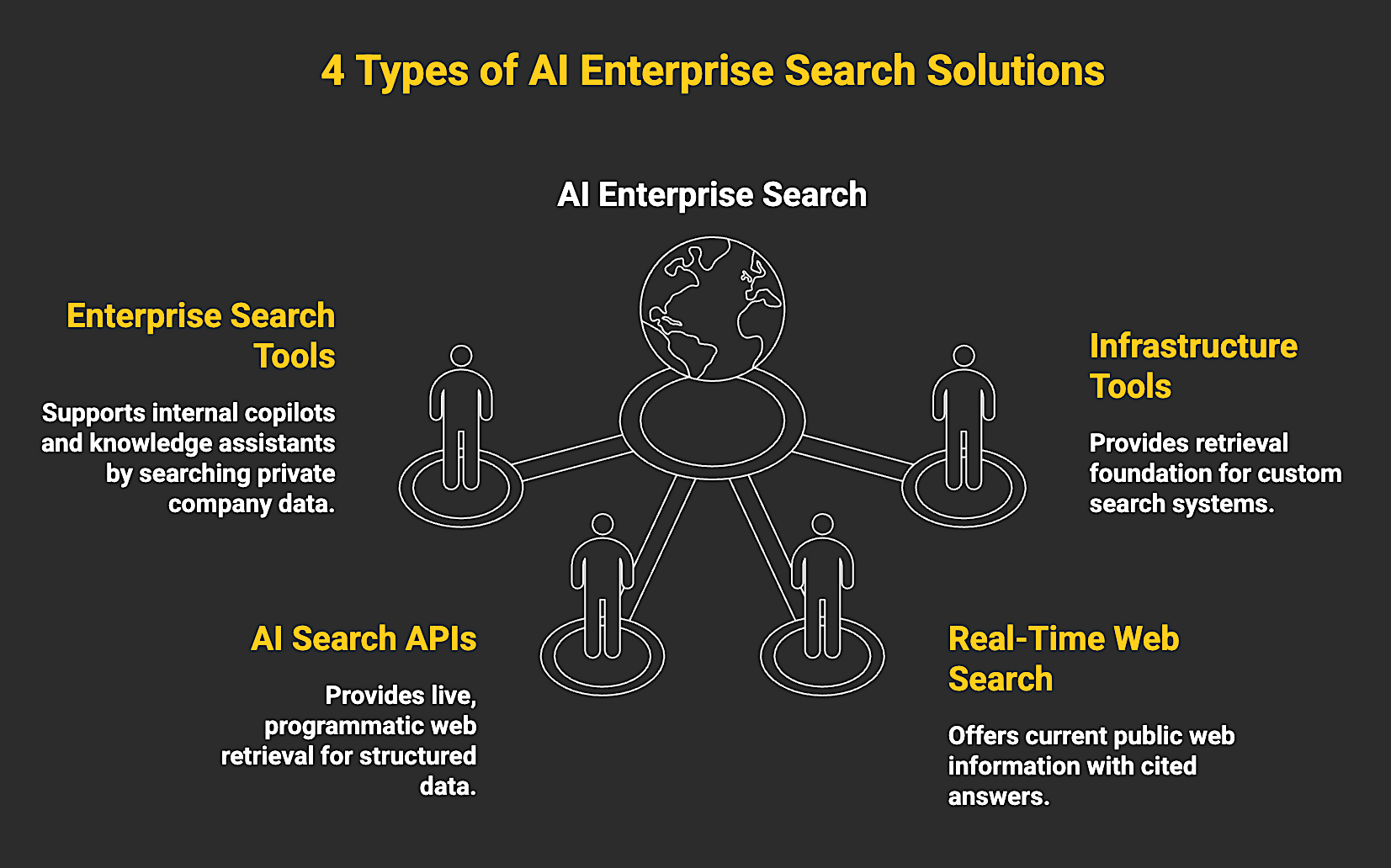
4 Types of AI Enterprise Search Solutions
The label "AI enterprise search" covers several retrieval architectures that sit at different layers of the stack and solve different problems. For agent builders, these systems are not interchangeable. They differ in data freshness, output format, and how much engineering work is required to make them usable in production. Here’s how the four types break down:
- Enterprise Search (Internal) tools pull together private company knowledge from systems like Slack, Google Drive, Jira, and document management platforms, then make it searchable within existing permission boundaries. Their role is to support internal copilots and knowledge assistants.
- AI Search APIs are developer-facing interfaces for live, programmatic web retrieval. They are built for production agents that need current external data returned in structured formats like JSON, with outputs that move directly into pipelines and downstream systems without additional parsing.
- Real-Time Web Search solutions retrieve and synthesize live public web content into cited, conversational responses. While some products support agent workflows, in general their output is designed for human consumption. They are most useful for analyst and research workflows where readability and source visibility matter more than machine-ready structure.
- Infrastructure (Vector / Hybrid) tools provide the retrieval foundation for custom search systems. They support semantic and hybrid search over proprietary datasets, but teams still need separate ingestion and freshness layers.
Benefits of AI Enterprise Search Solutions
AI enterprise search solutions offer many benefits to agent builders and enterprise AI teams, including:
- Eliminates Data Staleness – Real-time retrieval helps decisions and agent behavior stay grounded in current information rather than cached snapshots.
- Reduces AI Hallucinations – Current, verifiable data gives the model a stronger factual basis, improving output accuracy and lowering hallucination risk.
- Unifies Fragmented Knowledge – Connects siloed internal systems and scattered sources into a shared retrieval layer that agents can access.
- Delivers More Machine-Ready Outputs – Returns cleaner, more structured outputs that reduce downstream cleanup and make data easier to use in pipelines.
- Reduces Engineering Overhead – Managed retrieval infrastructure reduces the need to maintain custom scrapers, connectors, or indexing layers as sources change.
Top 9 AI Enterprise Search Solutions for 2026 [by Category]
Enterprise Search (Internal)
Buyers Care About:
Buyers in this category need to support internal AI assistants and employee search without crossing security boundaries. They are typically looking for strong permissions enforcement, identity-aware retrieval, and broad coverage across enterprise tools.
1. Glean – Best for Unifying Internal Apps
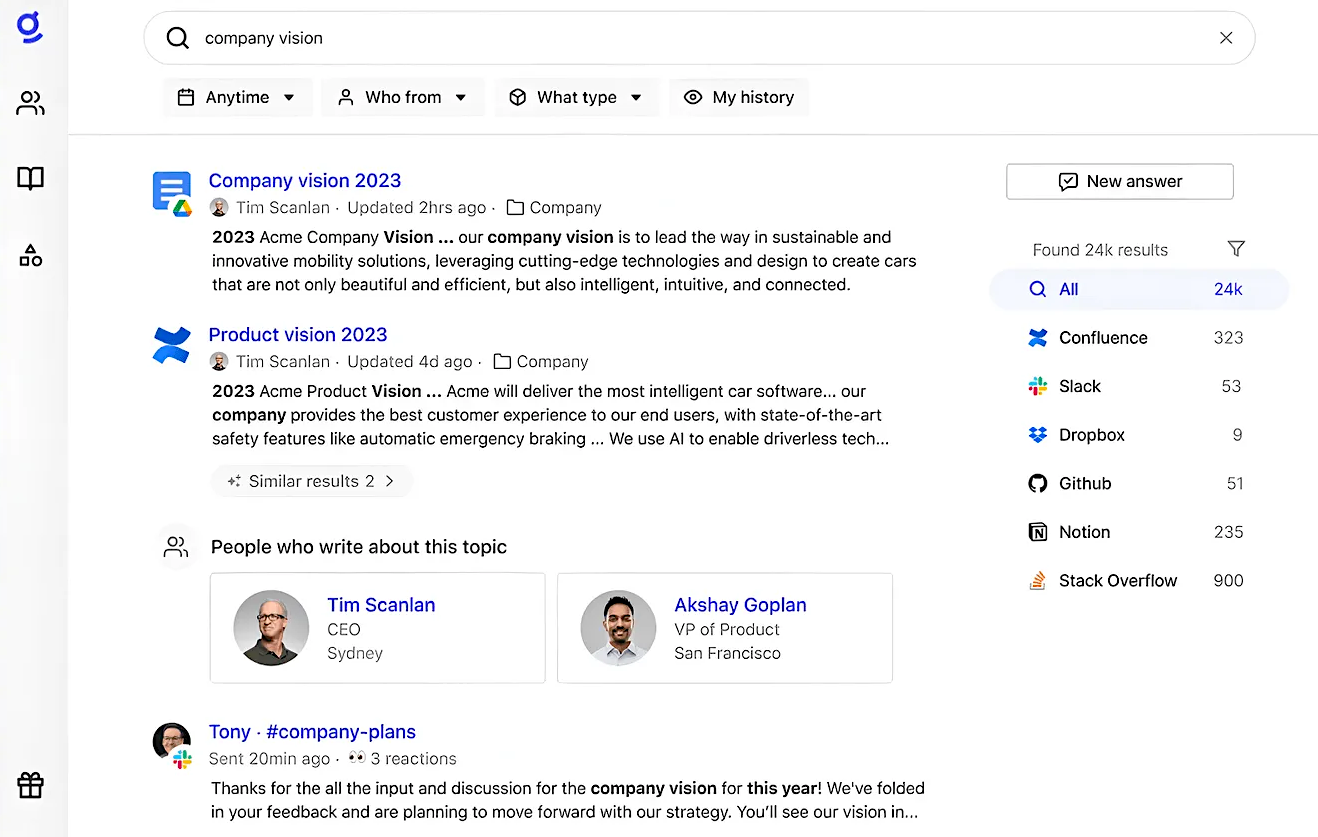
Glean pulls content from 100+ enterprise systems into one real-time, permissions-aware search layer. Its knowledge graph helps shape retrieval around user context, so results reflect both relevance and access boundaries. Enterprise Graph actions allow users to create agents that leverage organizational knowledge and context.
Key Features:
- 100+ enterprise connectors (including Slack, Google Workspace, Microsoft 365, Jira, Salesforce, and GitHub) with document-level permissions
- Knowledge graph for personalized retrieval
- AI assistant and no-code agent builder
- Audit trails, SOC 2, and role-based controls
Review: "Glean makes finding answers effortless. I can ask natural questions and get direct, trustworthy summaries without hunting across SharePoint, Outlook, Teams, and docs."
2. Coveo – Best for AI-driven Internal & External Portal Search

Coveo applies one search and relevance layer across internal systems and external customer-facing experiences. It works well when the same platform needs to handle employee search alongside self-service, partner, and commerce use cases. The platform’s relevance engine adjusts ranking over time using behavioral signals and query context, which helps it serve different audiences more effectively.
Key Features:
- Unified search across internal and external channels
- Relevance tuning from behavior and query signals
- Connectors for Salesforce, ServiceNow, SharePoint, and commerce tools
- Analytics for search quality and success
Review: "Coveo allows us to create a unified index of all our product knowledge. Using Coveo's built-in permission models and customizations, we can then deliver that content in multiple ways."
Real-time web search for AI
Buyers Care About:
Buyers in this category are choosing a retrieval layer for production agents. The core questions are whether the API accesses the live web at request time or relies on cached indexes, whether it returns structured outputs agents can use directly, and whether it can handle JavaScript-heavy and protected sites where weaker tools return stale or partial data.
3. Nimble – Best AI Web Search API for Live Web Browsing & Structured JSON Delivery
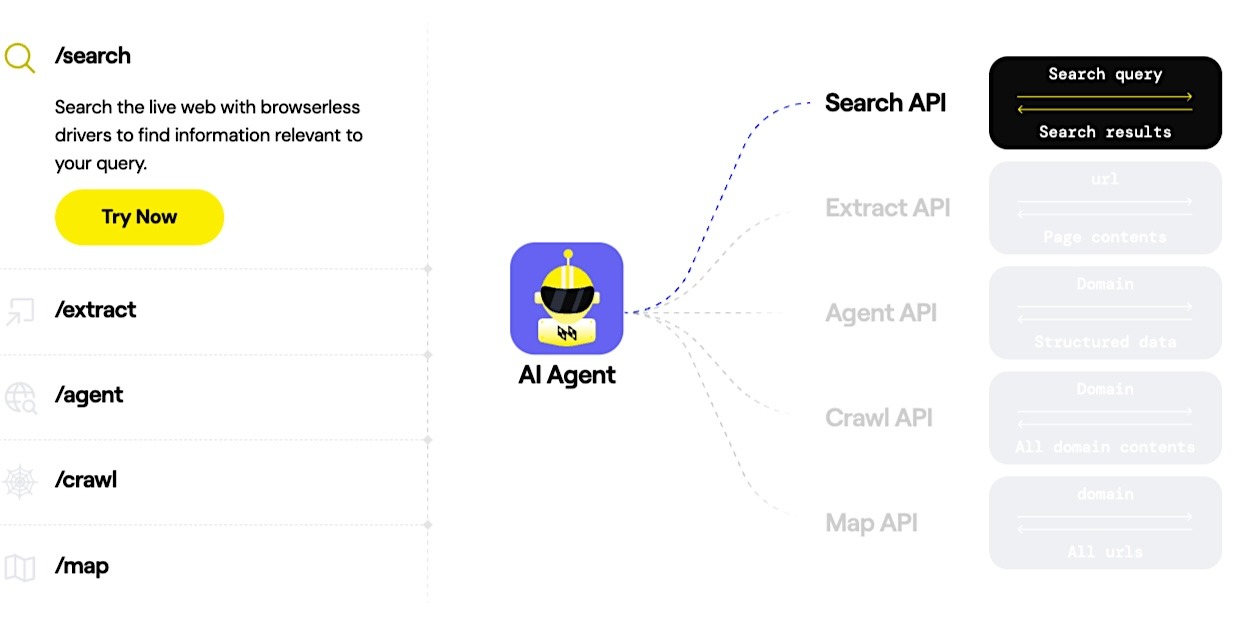
Nimble is the Web Data Agent platform behind AI systems that rely on real-time web data. Its AI web search API gives agents direct access to the live public web at request time, with retrieval handled by purpose-built Web Search Agents.
The Web Search Agents navigate sites in real-time, render JavaScript, and extract the data needed for the task. The output is returned as structured JSON so that data can move directly into agent workflows without another parsing step. For production AI agents that rely on current external data, Nimble is a strong fit because it delivers that data in a structured format that agents can use directly.
Key Features:
- Web Search Agents that are trained to retrieve specific information from given domains
- Live web retrieval that reflects the current state of a page
- Structured JSON outputs designed for direct use in agent workflows
- Full-page rendering for JavaScript-heavy and dynamically loaded content
- Reliable access to sources that block or degrade simpler retrieval methods
- Outputs that integrate cleanly into AI pipelines, analytics systems, and downstream processing
Review: "Nimble’s data platform met our massive data needs out of the box, feeding our large Language models with relevant, high-quality data. This scalability has been crucial in developing more robust and reliable AI systems."
4. Tavily – Best for Quick RAG Integration & Text Summaries
Tavily returns web search results through an API that is built to drop into retrieval workflows quickly, with official SDKs and LangChain support that reduce integration work. The platform returns text summaries, which makes it useful when condensed context is part of the response format. Tavily also supports extract, crawl, and map endpoints, and it enables setup for RAG-style retrieval plus summary-style responses in the same stack.
Key Features:
- Search API with configurable depth and topic handling
- Text summaries returned alongside source content
- Extract capability for pulling content from specific pages
- Crawl and map capabilities for broader retrieval workflows
- SDK and framework support for faster RAG integration
Review: "Tavily is a solid tool in many cases, but like most web search APIs, it doesn’t always guarantee live or high-quality links."
5. Exa – Best for Semantic, Neural-based Web Discovery
Exa’s search endpoint lets you search the web, then extract content from the results. Its core capability is semantic web discovery driven by embeddings rather than classic keyword matching. It can also extract content from results and support structured discovery workflows, but its clearest strength remains finding conceptually related material across the web.
Key Features:
- Neural and semantic web search
- Natural language query support
- Content extraction from search results
- Websets for structured batch discovery
Review: "We use Exa for essentially all parts of our research—gathering sources, documenting, creating notes, and building briefs."
6. Perplexity (Enterprise) – Best for Cited, Conversational Web Research
Perplexity Enterprise is a secure platform that orchestrates multiple models across your organization’s files and tools to handle tasks, complex projects, and deep research. It returns conversational answers grounded in web citations and adds enterprise controls such as SSO, admin management, and connector support. It’s a good choice for research and analyst workflows where the priority is fast synthesis with visible sourcing.
Key Features:
- Live web answers with inline citations
- SSO, admin controls, and privacy features
- Multi-model research support
- File upload and analysis
- SOC 2 Type II Certified security
Review: "Perplexity is now a reflex for our teams: rapid, cited context that we can validate quickly."
7. You.com – Best for Customizable, Privacy-first Search Modes
You.com provides APIs that let teams query the live web and retrieve results inside AI applications and agent workflows. It supports combining web results with other data sources and controlling how responses are generated. It can be used in multi-step workflows where web data needs to be incorporated alongside internal context or tool outputs.
Key Features:
- Ability to combine web results with internal data or other tools
- Configurable response modes and output formats
- Support for multi-step queries and agent workflows
- Enterprise controls for privacy, access, and deployment
Review: "The real-time accuracy of the Search API is something I have come to rely on heavily in my production environments."
Infrastructure (Vector / Hybrid)
Buyers Care About:
Buyers in this category want control over retrieval logic, ranking, and indexing strategies. They also look at performance across internal or embedded datasets and the flexibility to support semantic and hybrid search in custom agent architectures. Live web retrieval is not part of the package, so teams still need separate layers for ingestion, freshness, and scraping.
8. Elasticsearch – Best for Scalable Hybrid Search Architecture

A search and analytics engine used to build custom retrieval systems at scale, Elasticsearch leverages hybrid retrieval over large internal datasets. It combines various search approaches such as semantic search, traditional lexical term matching, BM25 keyword search, and vector search in the same index.
Key Features:
- BM25 and vector search in one index
- Distributed architecture for scale and uptime
- Flexible ranking and retrieval logic for keyword, vector, and hybrid search
- Managed cloud and self-hosted deployment
Review: "Elasticsearch gives our team fast and relevant search results. We manage large datasets with ease."
9. Pinecone – Best for Vector Infrastructure Powering Custom Semantic Search

Pinecone is a managed vector database for low-latency similarity search across large embedding collections. It handles the vector storage and nearest-neighbor layer for teams building semantic search or RAG systems, which reduces the amount of infrastructure they need to manage.
Key Features:
- Managed vector database
- Low-latency similarity search at scale
- Namespace and metadata filtering
- Integrations with major embedding providers (OpenAI, Cohere)
Review: "It removes much of the operational burden of running vector databases, making production-grade semantic search significantly easier."
Choose the Retrieval Layer That Fits the Job
AI enterprise search closes the gap between AI systems and the data they cannot reliably reach on their own. But internal search, AI search APIs, real-time web search, and vector infrastructure are not interchangeable because they solve different retrieval problems. For agent builders, the decision comes down to whether retrieval arrives in a form the system can use in production.
Nimble is the retrieval layer for AI agents that need current information from the live public web. It connects agents to live websites at query time, and returns structured JSON that can move directly into production workflows. Web Search Agents handle browsing, rendering, and extraction across dynamic and protected sources, giving agent builders a practical way to use live external data inside real systems.
Book a demo to see how Nimble equips AI agents with live web search and structured data.
FAQ
Answers to frequently asked questions
.png)

.png)
.avif)
.png)
.png)