8 AI Assistant Web Search Capabilities to Implement
.avif)
Ilan Chemla
.png)
8 AI Assistant Web Search Capabilities to Implement
Ilan Chemla
Most popular articles

Get structured, reliable data for your stack.
8 AI Assistant Web Search Capabilities to Implement
When your team needs critical information in a hurry, where do they turn? Today, the first place they likely look for an answer is an AI assistant. Far more than simple chatbots, most AI assistants are powered by agentic retrieval systems designed to act on behalf of the user.
In fast-moving enterprise environments, the expectation is for these tools to reflect what is happening right now, rather than what was true a month ago. However, meeting that expectation is a significant technical challenge, because many assistants are still tethered to stale indexes and cached data that can't keep pace with the volatility of the live web.
Fixing this issue requires a closer look at the AI assistant web search capabilities that actually drive the retrieval process. These technical functions allow an agent to step outside its static training and engage with the web in real-time. When you move from periodically refreshed datasets to live, inference-time retrieval, you're essentially moving from an assistant that "guesses" based on the past to one that is grounded in the present.
Web search capabilities ensure that when an agent decomposes a complex query, it has the infrastructure it needs to find a factual, up-to-date answer. Accuracy is critical, especially with a recent study showing that 75% of workers use AI assistants for coding or virtual assistance.
A dedicated Search API serves as the programmatic link between an agent's reasoning process and the live web, providing the high-speed access required for inference-time discovery. Moving retrieval to a specialized API allows agents to bypass stale indexes and interact with the most current data available. Deploying a production-ready assistant involves implementing a specific set of AI assistant web search capabilities to handle the search, retrieval, and structuring of web information autonomously.
What is an AI assistant?
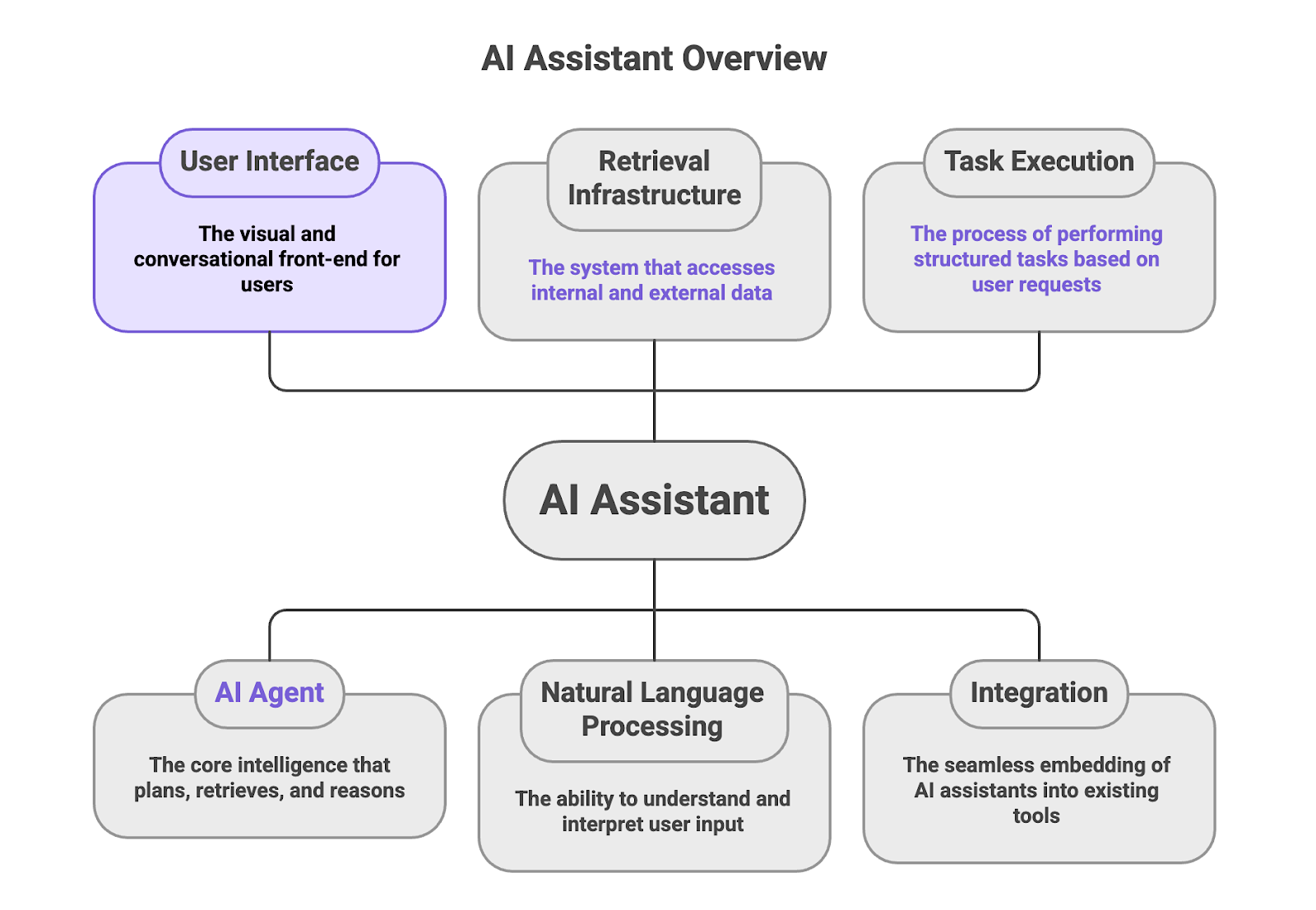
An AI assistant is a user-facing interface powered by an underlying AI agent that plans, retrieves, and reasons over data. While often presented to users as simple conversational tools, enterprise AI assistants operate through sophisticated agentic systems that execute multi-step retrieval and decision workflows. They accept natural language input and translate it into structured tasks, such as searching external sources, extracting specific information, and generating contextual responses.
In this architecture, the AI assistant functions as the critical interaction layer between the user and a complex retrieval infrastructure. The retrieval infrastructure includes both internal knowledge bases and the public web. Because they simplify complex data tasks, AI assistants are now deeply embedded in analytics platforms, enterprise software, developer environments, and custom internal tools.
The primary users of these assistants include:
- AI engineers and developers use AI assistants like GitHub Copilot to automate pipeline creation or troubleshoot infrastructure without manually navigating documentation.
- Analysts and business teams rely on AI assistants such as Salesforce Einstein to access instant insights and visualizations by simply asking questions in plain English, eliminating the need for manual dashboard navigation.
Ultimately, the effectiveness of any AI assistant is strictly capped by the capabilities of its underlying AI agent, and particularly its ability to retrieve and structure live web data programmatically rather than relying solely on static LLM training data or outdated model weights.
What are AI assistant web search capabilities?
AI assistant web search capabilities are the architectural functions that allow an AI assistant's underlying agent to access public web data during inference. They determine whether the assistant can retrieve live web pages programmatically in response to a user request.
These capabilities are essential when answering questions that depend on current, source-specific, or frequently changing web information.
Examples of these capabilities include:
- Source Discovery is the ability to identify relevant public web sources likely to contain the required information.
- Live Page Retrieval enables fetching web pages at request time rather than relying solely on cached data in indexes.
- Structured Extraction is about processing raw, messy web content and converting it into clean, machine-readable formats like JSON. Without structured outputs, assistants must rely on additional LLM parsing steps to extract usable data from text snippets, increasing cost, latency, and error risk.
- Grounding incorporates retrieved web information into generated responses to ensure model accuracy and reduce hallucination risk.
Robust web search capabilities enable assistants to work with real-time data, structured data, and hard-to-reach data across complex, JavaScript-heavy, and anti-bot-protected environments that commonly block traditional crawlers. Many systems rely on cached data in indexes or periodically refreshed datasets, which may not reflect real-time conditions.
Implementing AI assistant web search capabilities allows enterprises to ensure their AI agents operate on the most current information available, which maintains the reliability required for production-grade AI systems.
How do AI assistants search the web?
AI assistants must follow a structured, programmatic workflow to interact with the live web. This process transitions the assistant from a simple text generator into an active agent capable of discovering and validating information in real-time.
Here's how the workflow generally operates:
- A user enters a natural language request for specific data into an AI assistant.
- The AI agent decomposes the user request into specific retrieval objectives. Rather than performing a single keyword search, the underlying agent analyzes the natural language prompt to identify specific entities, constraints, and the multi-step information requirements needed for a complete answer.
- A retrieval layer identifies relevant public web sources. It evaluates the digital landscape to determine which specialized domains, such as databases, news outlets, or e-commerce platforms, are most likely to house the necessary data.
- Depending on architecture, systems may rely on indexed data or execute direct source targeting. While some assistants pull from static, cached snapshots, more advanced systems target specific URLs directly to ensure information hasn't changed since the last crawl.
- Web pages are fetched programmatically so the assistant can access full page content. Using headless browser technology, the agent executes client-side JavaScript and renders dynamic content that static HTTP requests cannot access.
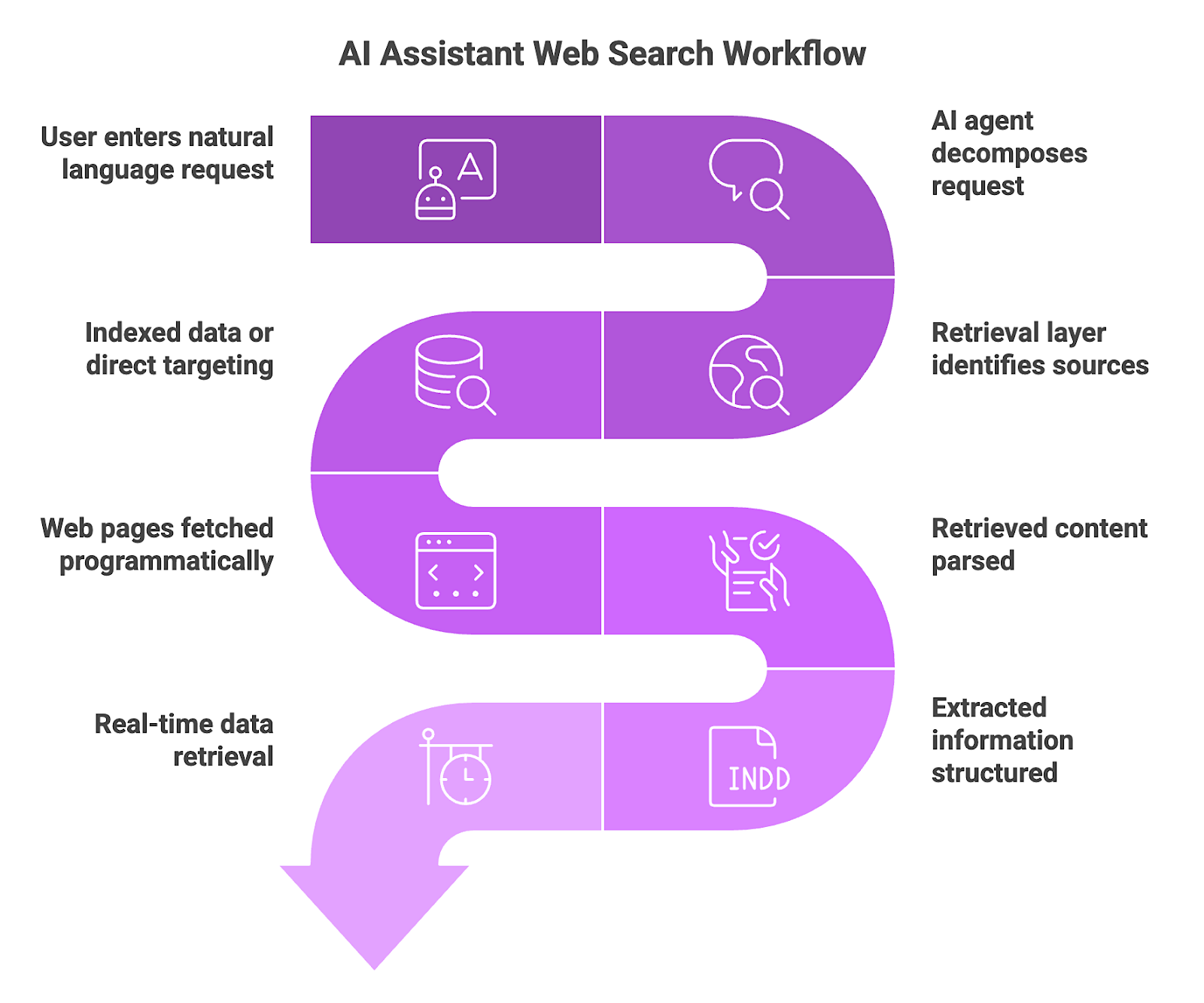
- Retrieved content is parsed, and relevant information is extracted. The agent strips away the "noise" of a webpage, such as advertisements and navigation menus, to isolate the core facts, like a product's price or a company's leadership team.
- Extracted information is structured and provided to the model as grounding input. This data is converted into a machine-readable format that serves as the factual "anchor" for the model, significantly reducing hallucination risk and limiting reliance on outdated internal training weights.
- Systems that execute live retrieval at request time can operate on real-time data rather than cached representations. Performing this entire cycle at the moment of inference enables the assistant to generate responses that reflect the current state of the world. While index-based systems may return faster responses, that speed comes at the cost of data freshness, a tradeoff that matters in production AI workflows.
Nimble's AI Search API serves as an ideal execution layer for this workflow by consolidating browser orchestration, proxy management, and data extraction into a single endpoint. It dynamically selects appropriate browser drivers, session configurations, and rotating residential IPs to maximize retrieval success across different domains. The API delivers structured outputs such as JSON objects or schema-defined tables, reducing token overhead and eliminating the need to parse raw HTML.
8 AI Assistant Web Search Capabilities
Here are the AI assistant web search capabilities you should implement to ensure your agents deliver accurate, real-time results in a production environment:
1. Query Understanding and Intent Decomposition
Query understanding is the architectural layer that interprets natural language requests to determine the specific parameters required for web retrieval. This phase aligns search execution with precise constraints, named entities, and high-level objectives, preventing the exhaustion of token and compute resources on irrelevant datasets. By mapping linguistic nuance to technical search parameters, the system ensures the retrieval layer operates with high precision.
Engineers apply intent decomposition to break multi-step prompts into a sequence of atomic retrieval tasks. This process is necessary when an assistant must plan a multi-stage strategy, such as identifying that a request for "competitor growth" requires separate concurrent fetches for financial filings and recent press releases. Effective decomposition transforms the assistant from a basic search interface into a reasoning engine capable of executing complex, multi-variable research workflows.
2. Web Source Discovery
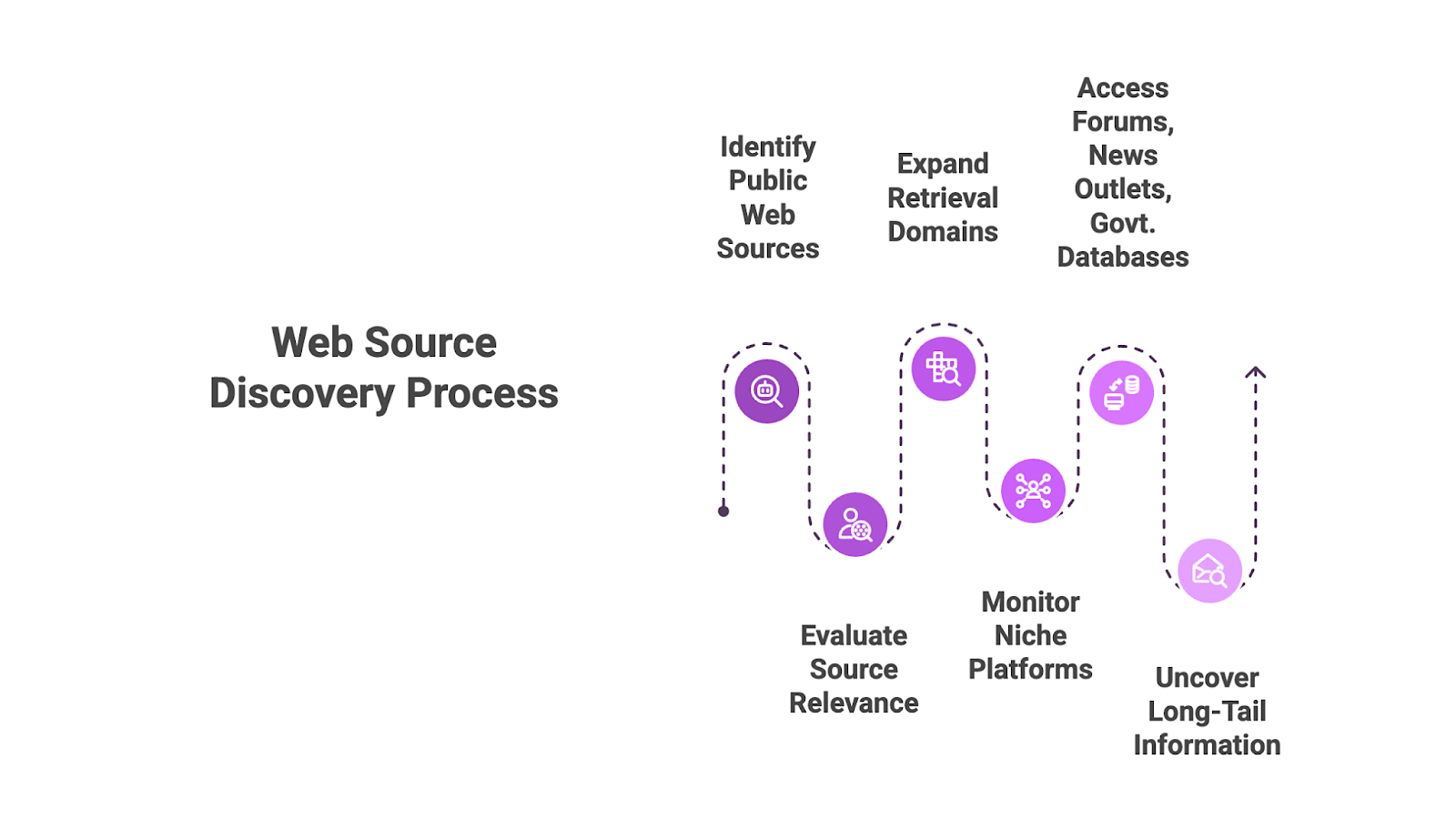
Web source discovery is the capability of an AI agent to autonomously identify and evaluate public web sources that likely contain the required information. This mechanism provides broad coverage across the open web, minimizing the information gaps that occur when an agent is restricted to a narrow subset of indexed sites or hardcoded connectors. It enables the retrieval layer to be dynamic rather than static, adjusting its target list based on the specific context of the query.
The discovery process expands retrieval beyond predefined domains, allowing the assistant to evaluate the digital landscape in real-time. It's applied in monitoring and competitive intelligence workflows where relevant data often resides on niche forums, specialized news outlets, or government databases not originally specified by the developer. By automating source identification, engineers ensure the agent can uncover "long-tail" information that traditional, closed-loop RAG systems would miss.
3. Live Web Content Retrieval
Live web content retrieval is the programmatic execution of HTTP requests or browser sessions at the moment of inference, bypassing the stale snapshots found in traditional search indexes. It provides the technical foundation for "freshness" by ensuring that the model's context window is populated with real-time data, even when the source is volatile and changes by the minute.
This capability solves the "Temporal Gap" in a RAG pipeline (Retrieval-Augmented Generation) for use cases involving pricing, inventory, or regulatory updates where deprecated data triggers hallucinations. Implementing a solution such as Nimble's AI Search APIs allows the agent to initiate live sessions that return structured outputs instead of raw HTML. Direct retrieval captures the current state of targeted public domains at the moment of inference to provide a reliable factual anchor for downstream reasoning.
4. Content Parsing and Extraction
Content parsing and extraction involve processing unstructured web pages to isolate specific facts, attributes, or data points. The procedure prevents injecting long, noisy text blocks into an LLM. High-noise inputs inflate token costs and degrade the agent's ability to interpret data accurately.
Engineers implement extraction to transform raw HTML into structured inputs for AI reasoning. Effective parsing converts public web content into machine-readable formats. Only relevant signals, such as specific product prices or news dates, enter the model's context window. Mapping unstructured data to a clean schema reduces noise and provides the consistent data types required for reliable downstream logic.
5. Structured Data Generation
Structured data generation is the transformation of extracted web content into machine-readable schemas, typically JSON objects or typed tables. This capability moves an agent beyond generating prose and allows it to function as a data provider for production pipelines where schema consistency is a requirement. By enforcing a strict structure at the point of retrieval, the system ensures that the model's findings are programmatically valid and ready for automated reasoning or validation steps.
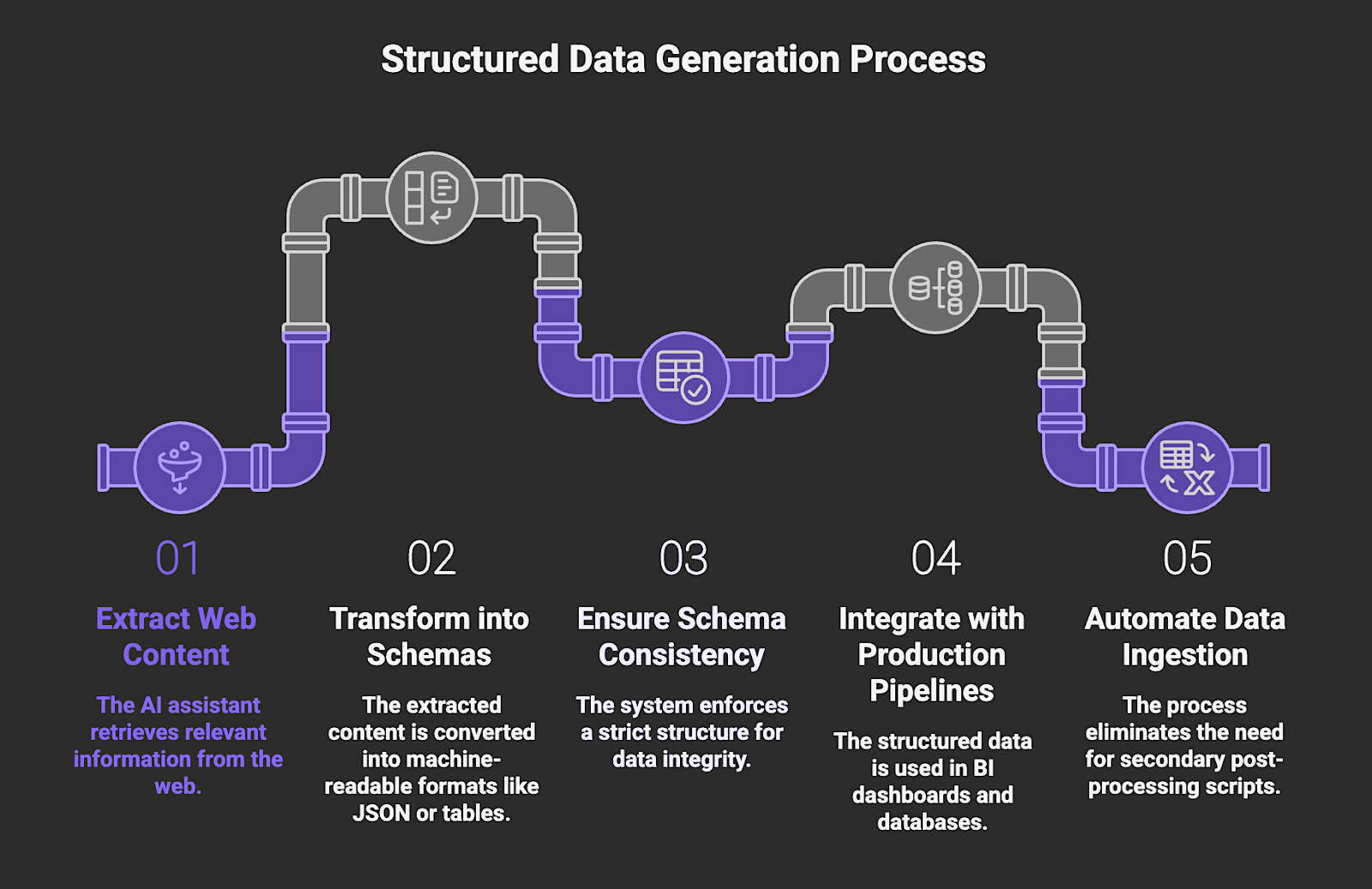
Engineers implement this capability where data needs to be ingested by BI dashboards or databases, such as for large-scale competitive intelligence, CRM automations, and real-time price monitoring. Implementation involves defining specific output schemas within the agent's function-calling definitions or using structured output APIs to map web elements directly to predefined keys. This approach eliminates the need for secondary post-processing scripts and ensures that the assistant's output is instantly consumable by downstream enterprise infrastructure.
6. Freshness and Update Handling
Freshness and update handling is the architectural capability to synchronize agent reasoning with real-time web states through an inference-time retrieval model. This mechanism ensures that the retrieval layer fetches the current version of a data source at the exact moment of a user query, bypassing the stale snapshots found in traditional search indexes. It is critical for maintaining the integrity of the model's context window, as it prevents the LLM from reasoning over deprecated data that has decayed since the last crawl-index cycle.
In production, engineers apply this to high-volatility use cases like monitoring equity markets, tracking supply chain logistics, or supporting conversion optimization where pricing and availability data changes rapidly. Implementation requires integrating live retrieval APIs directly into the agent's tool-calling loop rather than relying on a static vector database. Triggering dynamic fetches during the reasoning phase enables the system to capture the immediate state of a target URL and provides a reliable factual anchor for downstream enterprise decision-making.
7. Grounding and Response Generation
Grounding is the architectural process of anchoring LLM outputs to a verified, retrieved context block rather than the model's internal training weights. This mechanism serves as a key mechanism for reducing hallucination risk by forcing the model to treat live-fetched web data as the exclusive "source of truth" for a given query. A direct link between retrieved evidence and the generated response ensures that every claim is traceable to a specific, verifiable origin. Clear source attribution also reduces the risk of AI answer fraud that arises when provenance is obscured or manipulated information is surfaced.
Engineers implement grounding for high-stakes enterprise applications where factual precision is non-negotiable, such as legal research, financial reporting, or medical data synthesis. Implementation involves a strict prompting strategy that uses specific "Context" and "Fact" delimiters to inject structured web data into the model's context window at the moment of generation. The assistant can then provide evidence-based answers with precise source citations, and acknowledge when information is absent rather than attempting to fill gaps with probabilistic guesses.
8. Programmatic Web Search via Nimble’s AI Search API
Programmatic web search is the method of exposing search engine capabilities as a structured API for automated querying by AI agents. Unlike a visual search interface designed for human navigation, this execution layer converts the web into a queryable data source where the agent sends parameters and receives machine-readable results. It enables agents to discover, filter, and access URLs based on real-time needs, providing the connective tissue between an agent's reasoning logic and the broader public web beyond static search indexes.
Engineers utilize this capability for workflows that require an agent to find current pricing, locate specific documentation, or track news across millions of domains without human intervention. In production, this is essential for scaling discovery-based tasks where the agent must programmatically adjust search parameters, such as geolocation or domain filtering, to optimize the results for a specific downstream task.
Nimble's AI Search API provides this essential execution layer, allowing enterprise AI systems to connect agents directly to the live public web with high reliability. Using the API, agents can perform inference-time retrieval of real-time, structured, and hard-to-reach data on any site. It allows engineers to focus on the reasoning and logic of their assistants while Nimble handles the infrastructure complexities of web data acquisition at scale.

Why Enterprises Need High-Performance Web Search for AI
The shift toward agentic retrieval marks a definitive turning point in how AI assistants interface with the public web. These systems now possess the intelligence to determine exactly when and how to access live, structured data at the moment of inference, and are the primary drivers of reliability and freshness in a production environment. For organizations evaluating AI solutions, understanding AI assistant web search capabilities provides the only practical framework for distinguishing between a basic conversational bot and a robust, data-driven assistant capable of high-stakes enterprise work.
Nimble's AI Search API bridges the gap between these sophisticated agentic requirements and the fragmented reality of the live web. It enables AI agents to execute searches at request time, and removes the need to rely on stale, cached indexes that often compromise the accuracy of AI outputs. The API fetches content directly from the source and delivers structured, analysis-ready data. Built on enterprise-grade proxy and scraping infrastructure, it enables reliable access to dynamic and protected pages that often block traditional crawlers.
Book a Nimble demo to see how its AI Search API connects production AI agents directly to the live web with structured, inference-ready data.
FAQ
Answers to frequently asked questions
%201%20(1).png)
.png)
![Top 9 AI Enterprise Search Solutions for 2026 [by Category]](https://cdn.prod.website-files.com/699c65d475d592ff4cf9729d/69fc42a16546ad21fd4c45bc_Top%209%20AI%20Enterprise%20Search%20Solutions.png)
.png)
.png)
