5 Bright Data Alternatives and What They Are Better For

Charlie Klein

5 Bright Data Alternatives and What They Are Better For
Charlie Klein
Most popular articles
Get structured, reliable data for your stack.
5 Bright Data Alternatives and What They Are Better For
Abstract
Bright Data alternatives range from proxy-first infrastructure platforms to newer structured web data APIs and AI-oriented web data tools that deliver fresh public web data for analytics and automation workflows.
Top Bright Data Alternatives Include:
- Nimble
- Decodo
- Zyte
- Infatica
- IPRoyal
Bright Data remains a strong fit for teams that need large-scale proxy access, geographic coverage, and web collection infrastructure. But for many AI and analytics workflows, access is no longer enough.
Recent research found that 51% of data and analytics leaders cite data quality as their top priority for improving data integrity in 2026. As teams move AI systems into production, they need fresh, structured web data that can move into pipelines with less parsing, validation, and delivery work.
This guide compares the top Bright Data alternatives by use case, including platforms focused on proxy infrastructure, managed extraction, and structured data delivery.
What is Bright Data, and what does it do?
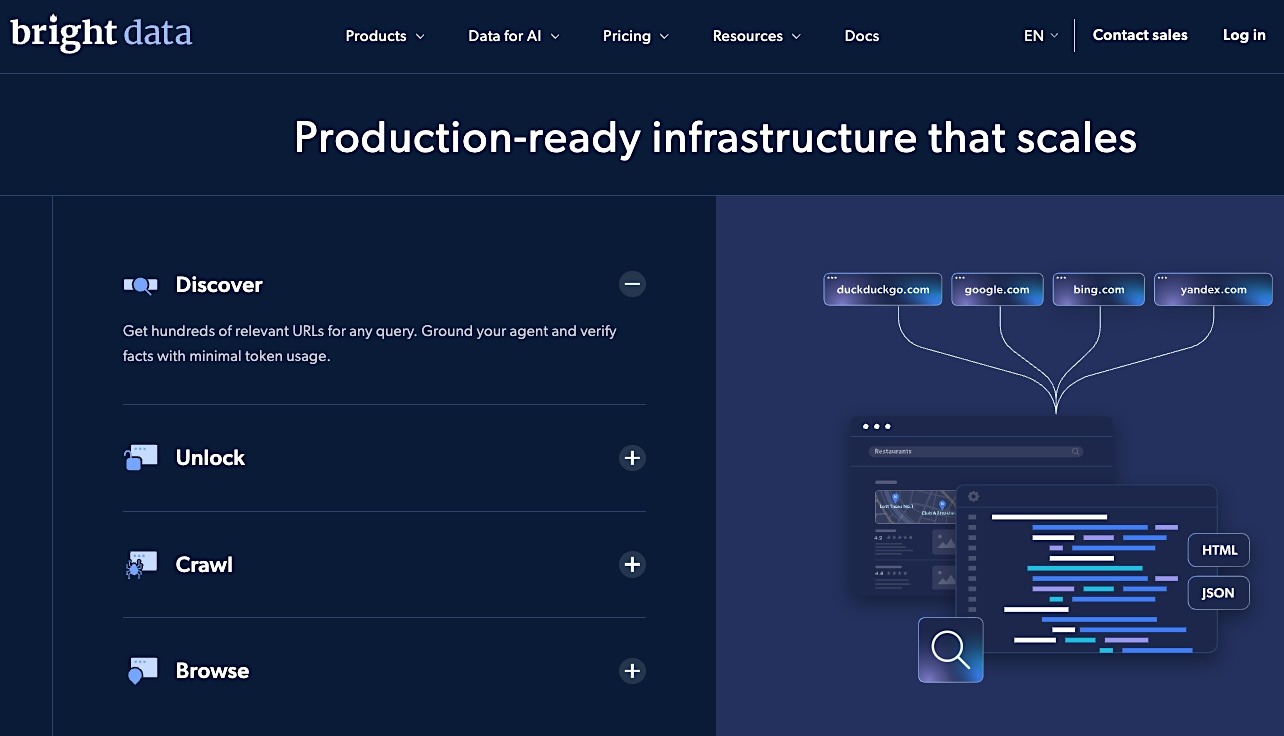
Bright Data is an enterprise web data infrastructure platform designed to give organizations large-scale access to public web data. It combines proxy networks, web scraping tools, and pre-built datasets into a single system that supports data collection across a wide range of industries and use cases.
For data engineering teams, Bright Data often serves as the foundational layer for gathering raw web data that feeds analytics, machine learning models, and market intelligence systems. At its core, Bright Data operates as a full-stack infrastructure provider, with a feature set that includes:
- A global proxy network that spans more than 400 million residential, datacenter, ISP, and mobile IPs across 195 countries, allowing teams to access region-specific data and navigate geo-restricted environments.
- A Web Unlocker API that handles much of the access-layer complexity, including proxy selection, retries, JavaScript rendering support, CAPTCHA handling, headers, and fingerprinting logic for non-interactive extraction.
- Pre-built scraping and dataset products for common sources and categories, including eCommerce, search, real estate, business data, and AI training use cases.
- A Dataset Marketplace that provides ready-to-use structured datasets alongside raw extraction outputs in formats like HTML, JSON, and CSV.
This combination of scale, access, and tooling makes Bright Data a strong fit for teams running large-scale data collection workflows for use cases like competitive intelligence or AI training data acquisition.
When Bright Data May Not Be the Right Fit
Bright Data is built for enterprise-scale web access, but not every team needs that level of infrastructure. Because many Bright Data workflows begin with web access or extraction infrastructure, teams may still need to build and maintain processing layers to clean, structure, and validate data before it can be used downstream.
Common reasons teams look elsewhere include:
- Platform complexity: Smaller teams, or teams without dedicated scraping engineers, may find the learning curve difficult to manage.
- Pricing predictability: Enterprise minimums and bandwidth-based billing can make costs harder to forecast as workloads change.
- Output requirements: Pipelines that need structured, analysis-ready data may not want to rely on raw HTML or outputs that require additional parsing.
- AI workflow fit: AI agents and RAG systems often need live web data in a usable format, not just access to pages or periodically refreshed datasets.
- Infrastructure overkill: Some teams need reliable data delivery, but not the full scale of a large proxy-first platform.
In these cases, the better choice is a platform whose infrastructure model matches the way your team needs to turn public web data into usable production input.
Key Terms
When comparing enterprise web data infrastructure platforms, understanding these concepts helps clarify what each solution actually delivers and where the operational tradeoffs appear:
- Infrastructure Type: Describes whether a vendor gives teams web access to build on, extraction capabilities to configure, or managed delivery of processed web data.
- Output Format: Defines how much work remains after collection, from parsing raw page content to using returned fields directly in a pipeline.
- Data Freshness: Measures whether data collection happens at request time or comes from a source gathered earlier and updated on a set cadence.
- Site Coverage & Anti-bot Reliability: Evaluates consistency across websites with dynamic rendering, localization rules, bot defenses, or frequent layout changes.
- Compliance Posture: Covers privacy safeguards, security controls, procurement requirements, and responsible collection practices for public web data.
- Ease of Integration: Captures the time and engineering effort needed to connect the platform to existing workflows, storage layers, and AI systems.
Top Bright Data Alternatives by Use Case
- Recommended for production AI agents requiring real-time, structured web data at enterprise scale: Nimble
- Recommended for high-volume enterprise data collection on heavily protected targets: Oxylabs
- Recommended for cost-predictable web data infrastructure at mid-market scale: Decodo
- Recommended for fully managed data extraction with AI-powered structured output: Zyte
- Recommended for geo-targeted data collection on controlled proxy infrastructure: Infatica
- Recommended for budget-sensitive or irregular-volume web data workloads: IPRoyal
Comparison Table: Best Bright Data Alternatives Compared
Enterprise web data infrastructure defines how organizations access, collect, and deliver public web data for production AI systems that depend on current external information. Choosing the right Bright Data alternative requires a clear view of what each platform is built to deliver, and how much engineering work sits between web access and usable production data. The table below compares each solution across the dimensions that matter most for enterprise buyers.
How We Compared These Tools
We evaluated these Bright Data alternatives using a consistent set of criteria so readers can compare them clearly within the Enterprise Web Data Infrastructure category. Our evaluation is based on publicly available information as of 30 April 2026, including official product pages, documentation, pricing details, vendor comparison content, and third-party review sites.
What we reviewed:
- Official websites and product pages
- Documentation, feature explanations, and API pages
- Pricing pages and plan details (where available)
- Vendor-written comparison pages and alternative roundups
- Third-party review and software directory sites (where relevant)
How we compared tools:
We focused on the factors most likely to shape an enterprise buying decision, including infrastructure model, output format, data freshness, site coverage, and anti-bot reliability, compliance posture, ease of integration, and fit for production AI workflows.
We did not run hands-on testing for every platform. If a capability was unclear or public sources conflicted, we avoided definitive claims rather than overstating the comparison.
5 Bright Data Alternatives and What They Are Better For
Enterprise web data infrastructure now needs to support AI agents that search the live web autonomously and production pipelines that depend on fresh, structured public web data. These five Bright Data alternatives represent strong options in the category, each aligned to a specific production use case.
1. Nimble – Recommended for production AI agents requiring real-time, structured web data at enterprise scale
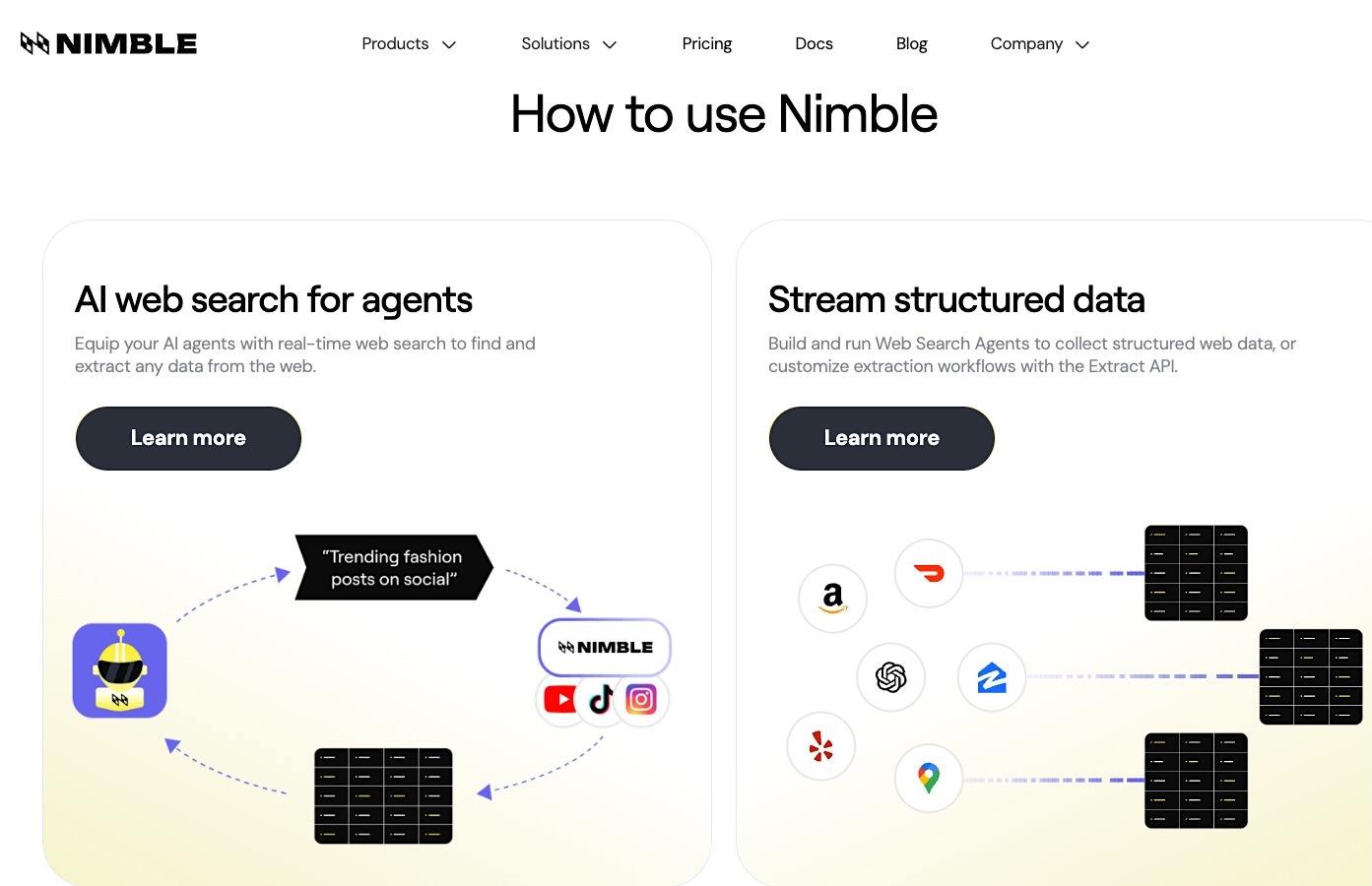
Nimble is an AI agent infrastructure platform that turns live public web pages into structured data that production systems can use with less parsing and post-processing work. Its Web Search Agents browse the live web, extract relevant information, and return structured outputs for AI agents and data pipelines instead of handing teams only raw page access to clean up themselves.
By combining live retrieval with structured delivery, Nimble reduces the engineering work between collection and production use. This functionality makes Nimble a strong fit for enterprise AI teams building agents that need to search autonomously and act on current external information.
Key Strengths
- Nimble searches the live web at request time instead of depending primarily on pre-built indexes or periodically refreshed datasets.
- Returns clean, parsed data such as structured JSON, which reduces the engineering work and processing overhead required to clean, structure, and validate raw web data before it enters AI or analytics systems
- Designed for production agent workflows that require current external information to support search, reasoning, and decision-making.
- Uses enterprise-grade access infrastructure, including browser automation, rendering, and proxy infrastructure, to improve reliability on complex public websites.
Key Limitations
- If your team wants to manage its own scraping stack end-to-end, a proxy-first provider may offer more direct infrastructure control.
- Teams running lightweight prototypes or low-volume retrieval tasks may not need a full enterprise web data infrastructure layer.
Why Choose It Over Bright Data
Choose Nimble when your AI agents depend on live web queries and need structured results returned at request time. While Bright Data provides infrastructure to access and collect data from the web at scale, teams may still need additional parsing, structuring, or delivery logic before that data is ready for agent workflows. Nimble retrieves live public web data and returns it as structured output, reducing the transformation work required before results move into AI agents’ reasoning or downstream systems.
Pricing
A free trial is available, and there are two payment models: Pay-as-you-go, with costs per API, and Custom pricing.
Review
“Nimble has become our default platform for collecting public web data. We use a combination of Nimble IP and the Web API to route requests through residential proxies and reliably unlock sites that were very unstable with other providers. Overall, it feels like a modern, end‑to‑end web data platform rather than just a proxy provider.”
2. Decodo – Recommended for cost-predictable web data infrastructure at mid-market scale
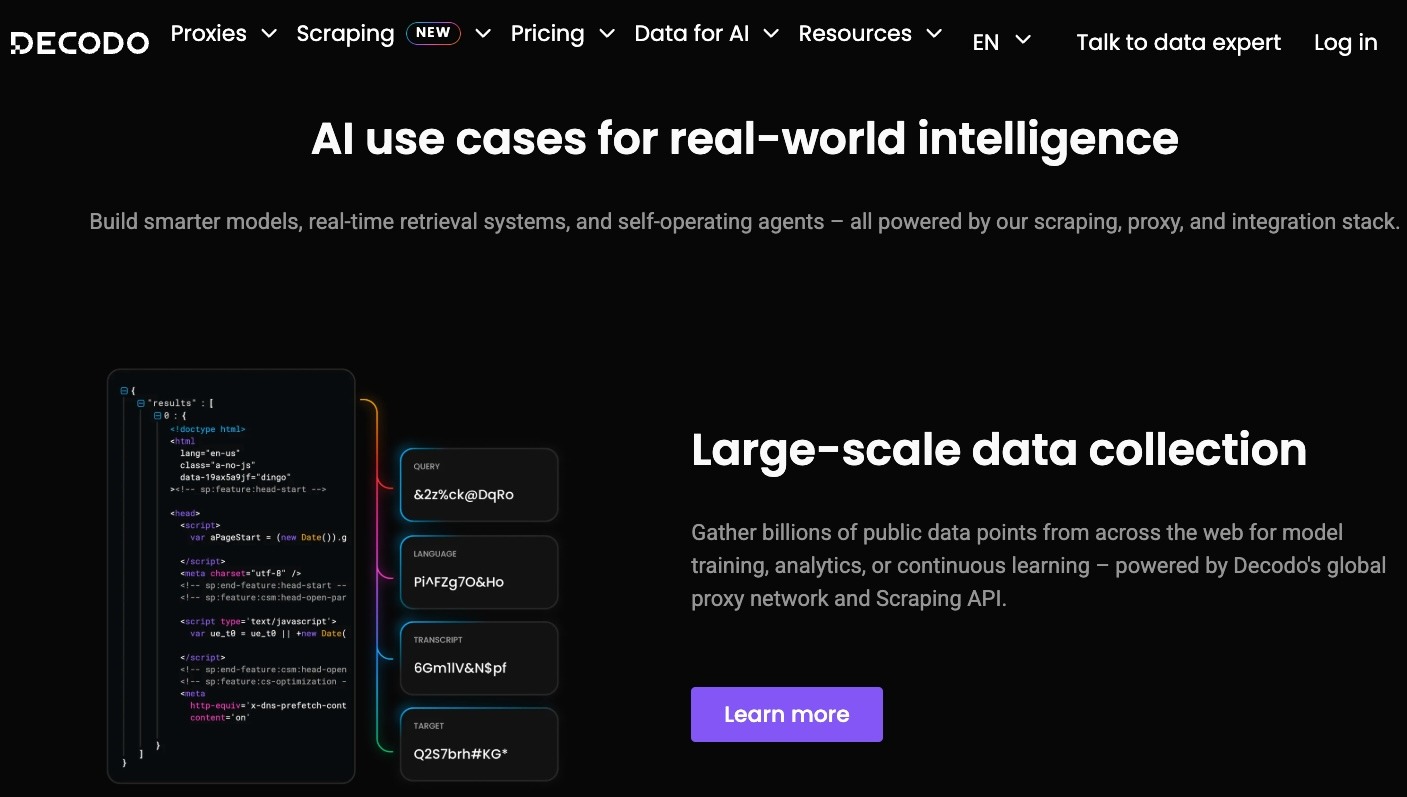
Decodo, formerly Smartproxy, is a practical fit for teams that need production web data collection without adopting the commercial weight of a larger enterprise platform. It offers proxy products, a Site Unblocker, a Web Scraping API that can return results in formats such as HTML, JSON, CSV, PNG, and Markdown, and an AI Parser that can turn HTML into structured JSON. Self-serve plans, API usage tiers, and transparent product packaging make it especially useful for mid-market teams that want to control spend while still using managed collection features.
Key Strengths
- Public plans and request-based API tiers provide usage visibility that makes it easier to estimate spend before scaling a workload.
- Collection flexibility lets teams start with proxies and move to higher-level scraping APIs as requirements become more complex.
- Decodo is easier to trial and implement for teams that do not want a long enterprise sales process before testing a workflow.
Key Limitations
- Decodo is a strong mid-market option, but teams with the largest global collection programs may need more advanced enterprise controls or broader managed data services.
- The platform’s output quality depends on the product and configuration. Decodo offers structured output capabilities, but teams may still need additional processing depending on the source, schema, and workflow.
Why Choose It Over Bright Data
Decodo is a better choice when you want to run consistent data collection workflows without committing to enterprise contracts or managing the overhead that comes with a larger proxy-first platform. Compare that to Bright Data, which is designed for large-scale enterprise programs with complex requirements and has the pricing models to match.
Pricing
Various price points for APIs and proxies, including Web Scraping API starting from $0.09/1k requests; Residential Proxies starting from $2/GB; and Site Unblocker starting from $0.95/1k requests.
Review
“The proxy network is stable, fast, and consistent across regions, which is critical for web data extraction at scale. Setup is straightforward, the dashboard is clean, and integrations with common scraping tools work without much friction.”
3. Zyte – Recommended for fully managed data extraction with AI-powered structured output
Zyte is an all-in-one web scraping and data extraction platform for teams that need fully managed public web data collection. Its API handles access, rendering, and ban management, while its AI-powered extraction can return structured data for supported page types such as product, article, and job-posting pages. For teams that want to offload more of the workflow, Zyte also offers managed data services and Scrapy-based deployment options, making it a solid choice for organizations that want structured web data without maintaining the full extraction stack internally.
Key Strengths
- Zyte API charges for successful responses, which can reduce wasted spend from unsuccessful requests.
- AI-powered extraction for supported data types, including product pages, articles, and job postings, reduces manual parsing work for AI search and other retrieval-heavy use cases.
- The Scrapy ecosystem lets teams deploy, run, schedule, and scale Scrapy spiders without maintaining their own crawler hosting environment.
Key Limitations
- Zyte’s managed services and enterprise-scale workloads may require higher spend than simpler access-layer providers.
- Teams that want direct control over proxy selection, scraping behavior, or custom collection logic may prefer a more self-managed platform.
Why Choose It Over Bright Data
Choose Zyte over Bright Data when the handoff between collection and usable data is the main problem. Bright Data provides broad AI data infrastructure for accessing public web sources, but teams may still need to manage parsing logic, crawler operations, and delivery workflows around that access. But Zyte is a better fit when teams want structured extraction and managed data delivery built into the workflow, especially for supported use cases where AI-powered extraction can reduce manual parser maintenance.
Pricing
Website scraping APIs are priced in five tiers, with datacenter, residential, rendering, and more included in one automated API with charges based only on what is used. Separate pricing for managed data extraction services (starts at $500/month) and cloud hosting for Scrapy spiders (Free, or Professional plan at $9/unit per month).
Review
“It features a powerful crawler and advanced proxy management, allowing us to automate almost all of our data collection tasks seamlessly through Zyte.”
4. Infatica – Recommended for geo-targeted data collection on controlled proxy infrastructure
Infatica is a proxy infrastructure and web data collection platform for teams that need geo-targeted access to public web data through proxy products, scraping APIs, pre-built datasets, and custom scraping services. The platform gives teams country, region, city, and ISP-level targeting, with dashboard controls for authorization and proxy rotation. It works well for data collection workflows that depend on how websites respond to requests from different regions.
Key Strengths
- Infatica’s governance over its proxy network supports clearer sourcing, routing, and responsible-use controls.
- Provides scraping APIs on top of the proxy network, so teams can reduce the infrastructure work required to retrieve public web data.
- Enterprise governance materials document consent-based sourcing, KYC verification, anti-abuse practices, ISO certifications, GDPR/CCPA compliance, and Trust Center practices.
Key Limitations
- Infatica is more access- and collection-oriented than managed data delivery platforms, so teams may still need to handle structuring, validation, and delivery into production systems depending on the workflow.
- The proxy network is significantly smaller than competitors like Bright Data or Oxylabs.
Why Choose It Over Bright Data
Infatica makes more sense when a project needs targeted regional web data collection but does not require Bright Data’s larger network, dataset marketplace, and broader enterprise platform. Infatica offers a narrower path for localized public web data workflows, with custom scraping support for teams that need help implementing the collection process. It is the better solution when location-specific web data collection and controlled proxy routing matter more than maximum infrastructure scale.
Pricing
Six Proxy plans range from Pay As You Go at $4/GB to Customized, with pricing on request. Contact sales for custom pricing on scrapers and APIs.
Review
“Infatica has been reliable for our needs. The proxies are stable with great uptime. The service is flexible enough to adapt to our various projects. It's a solid choice when it comes to maintaining consistent connections.”
5. IPRoyal – Recommended for budget-sensitive or irregular-volume web data workloads

IPRoyal is a proxy-first provider used for public web data collection, with residential, datacenter, ISP, and mobile proxy products, plus newer access-layer tools such as Web Unblocker. For most proxy-led workflows, teams connect IPRoyal to their own scraping or automation stack, then manage extraction and processing separately. It is recommended for budget-sensitive or irregular-volume workloads because its self-serve model and non-expiring residential traffic reduce the pressure to commit to a larger platform before the workload justifies it.
Key Strengths
- Supports rotating and sticky residential sessions, which help teams choose between frequent IP rotation and longer-lived sessions depending on the target site.
- HTTP, HTTPS, and SOCKS5 support make it compatible with common scraping frameworks, browser automation tools, and proxy managers.
- Chrome and Firefox extensions support browser-based proxy management, letting teams switch and manage proxies without relying only on dashboard configuration.
Key Limitations
- Its core offering is still proxy-led, so teams should expect to use their own scraping, automation, or processing stack for many production workflows.
- Smaller proxy network than category leaders like Bright Data or Oxylabs.
Why Choose It Over Bright Data
When your team needs a lower-cost access layer and already has the tools to collect and process data, IPRoyal is a good fit. Bright Data offers a larger network, scraping APIs, datasets, and broader enterprise controls, but your organization may not require a full enterprise web data platform. Instead, a leaner solution like IPRoyal may be enough: proxy infrastructure with flexible usage terms, standard integrations, and non-expiring residential traffic.
Pricing
Proxy and product pricing vary by use case, including ISP Proxies starting from $2.40/proxy; Residential Proxies starting from $1.75/GB; and Web Unblocker starting from $1.00/1k requests.
Review
“I appreciate how switching between locations is smooth and how it offers a variety of IP options, allowing flexibility for testing content in different regions. It effectively helps me overcome location-based restrictions and reduces interruptions like temporary access blocks when switching regions, which makes my workflow smoother and more consistent.”
Choose Production-ready Web Data Infrastructure That Matches Your Workload
Bright Data remains a valid option for teams that need broad proxy infrastructure, large-scale collection, and extensive enterprise tooling. But it is not the only fit for every web data workload. The right alternative depends on what your team needs most: raw proxy access and broad site coverage, managed extraction with structured output, cost-predictable access at mid-market scale, or production-ready web data that can feed AI agents without heavy post-processing.
Nimble is the right choice for teams that have outgrown raw-access workflows and need production-ready web data infrastructure for AI agents and data pipelines. It supports live web browsing, structured JSON output, and real-time data freshness while reducing the post-processing overhead that often comes with proxy-first infrastructure. For teams building production AI agents, the platform reduces the work required to turn collected web pages into usable inputs while improving confidence in data freshness and structure.
Book a demo to see how Nimble’s Web Data Agents deliver structured, real-time web data into production AI workflows.
FAQ
Answers to frequently asked questions


.png)

.png)

.png)
.avif)
.png)