7 Essential Components for AI Agent Infrastructure

Tom Shaked
.png)
7 Essential Components for AI Agent Infrastructure
Tom Shaked
Most popular articles

Get structured, reliable data for your stack.
AI agents often look impressive in a demo and still fail in production. The problem is rarely the model itself. It is the infrastructure around it: the systems responsible for memory, data access, orchestration, security, and runtime reliability. As enterprises move from AI experimentation to AI operations, infrastructure becomes the difference between agents that create value and agents that create risk.
In 2026, AI agents will be deployed by enterprises into pricing workflows, market intelligence pipelines, customer-facing systems, and internal data operations. Multi-step autonomous agents, multi-agent systems, and agent-native applications are moving onto real production roadmaps across industries. The teams succeeding in production treat agent infrastructure as a first-class engineering concern. But adoption alone does not equal production readiness. Gartner predicts that more than 40% of agentic AI projects will be canceled by the end of 2027, despite rapid enterprise uptake.
One of the clearest differences between a prototype agent and a production-ready one is access to live, structured, real-world data. Agents operating on stale or unstructured inputs produce unreliable outputs regardless of how well the rest of the stack is designed. Purpose-built web data platforms close that gap by giving agents current, structured, analysis-ready data at inference time. That is why live data access is now one of the seven core components of AI agent infrastructure.
What Is AI Agent Infrastructure?
AI agent infrastructure is the full-stack ecosystem of systems that enables an agent to perceive, reason, act, and learn at scale without constant human intervention. While development tools help teams design the agent, infrastructure includes the compute, memory, secure execution environments, and observability layers required for it to function in the real world.
Much of the early focus of generative AI was on development tooling. The emphasis was on model selection, prompt engineering, and early RAG pipeline architectures, aka the Build phase. Now, the challenge has shifted to the Run problem: deploying an autonomous agent that executes multi-step workflows, manages its own state, and interacts with production environments 24/7.
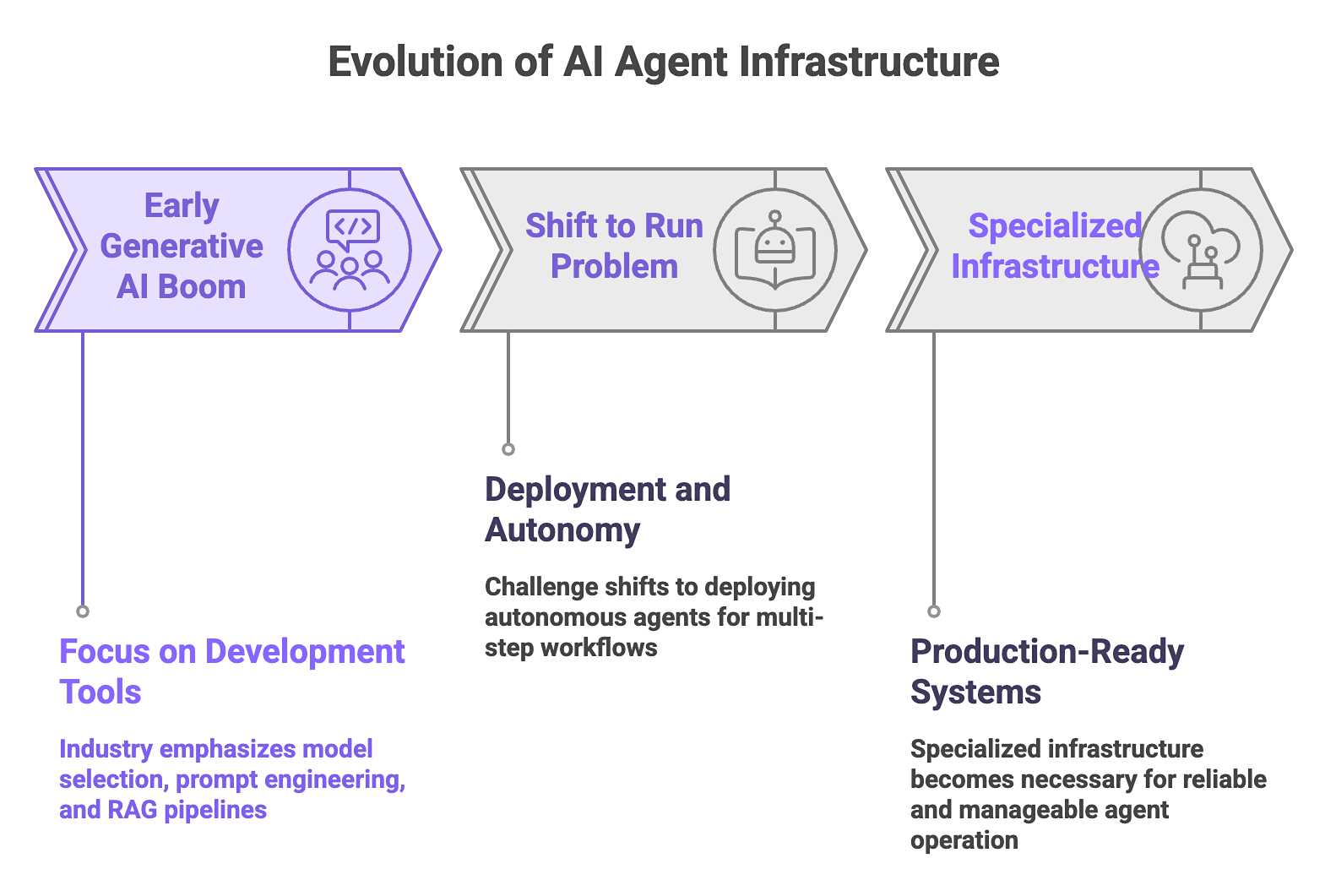
Specialized AI agent infrastructure is now necessary because the paradigm has shifted. Enterprises are moving away from single-turn assistants toward multi-step autonomous agents. These agents commit code, resolve tickets, and take action inside live systems. That introduces real-world consequences and much larger data requirements.
As AI agents take on more responsibility inside production systems, infrastructure becomes essential to keeping them reliable and manageable. Moving from a demo to real deployment requires an infrastructure layer built for the realities of agent operation.
The 7 Components of Production-Ready AI Agent Infrastructure
These seven interdependent components determine whether an agent can operate reliably in production or only perform well in a demo:
1. Orchestration
Orchestration is the engine that actually maps out and runs multi-step agent workflows. It manages how an agent uses tools, hands off tasks to sub-agents, and applies the logic required to reach a goal. Simple prompt chains are too fragile for production. If one step fails or the model gets stuck in a loop, the entire process breaks because there is no built-in way to recover or pivot.
Production Requirements:
- Support for multi-step loops, parallel execution, and complex conditional branching.
- Built-in retry logic and automated error handling to maintain workflow continuity.
- Auditable decision paths that allow developers to trace why an agent took a specific action.
- A calculated balance between deterministic code paths and LLM flexibility.
- Integration with frameworks such as LangGraph, LlamaIndex Workflows, CrewAI, or Autogen.
2. Memory and State Management
The challenge with agent memory is that Large Language Models are stateless. Without a dedicated infrastructure layer to manage state, an agent treats every interaction as a Day Zero event. That makes statelessness a core architectural hurdle for production agents, where context has to persist across longer tasks and multi-step workflows.
AI agents lose track of ongoing work without persistent context. A tiered memory architecture creates a state management layer that supports high-fidelity retrieval, so past decisions remain accessible without forcing everything into the active context window. It preserves continuity while keeping context lean enough to stay efficient.
Production Requirements:
- Context compression and prioritization strategies to manage token limits in short-term memory.
- External storage for long-term memory using vector databases like Pinecone, Weaviate, or pgvector.
- Key-value stores and episodic memory structures to track historical user interactions.
- Consistent and conflict-resistant shared state management for multi-agent systems.
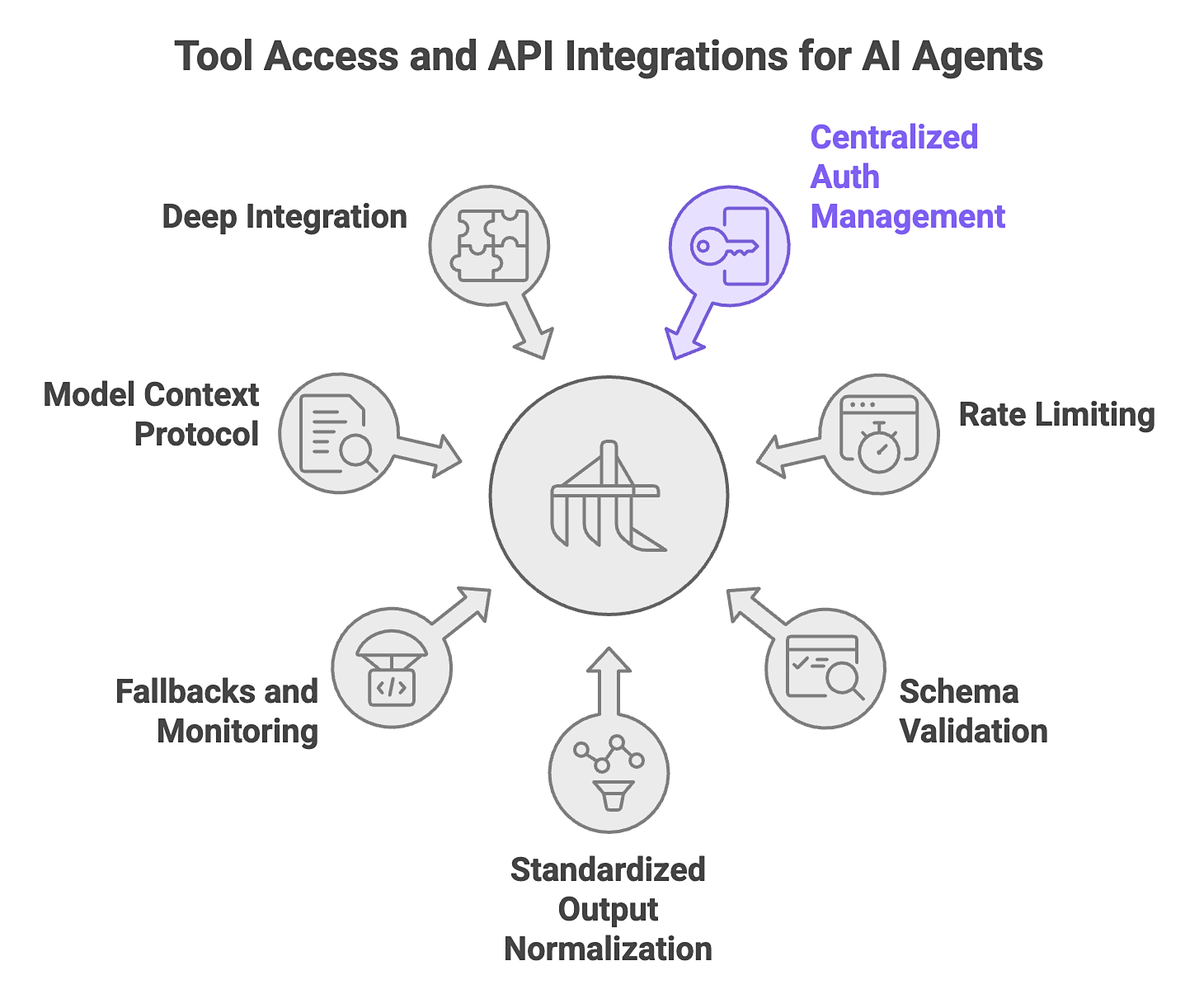
3. Tool Access and API Integrations
The tool access layer is the functional bridge between an agent’s reasoning and its ability to affect the real world. In a production environment, simply giving an agent “access” to an API or external systems like AI web search engines is insufficient. When tool access is unreliable, agents fail quietly. Timeouts and schema drift can break execution even if the reasoning is sound.
In production, this layer has to handle the mismatch between enterprise systems and autonomous agents. Most enterprise APIs were built for predictable human or application traffic, not the bursty and non-deterministic call patterns of agent workflows.
Production Requirements:
- Centralized auth management, rate limiting, and schema validation for all integrated tools.
- Standardized output normalization to ensure the agent receives data in a consistent format.
- Defined fallbacks and per-integration monitoring to catch API failures early.
- Adoption of the Model Context Protocol (MCP) for scalable tool registration and discovery.
- Deep integration with specialized tools like the Nimble AI Search API and Web API.
4. Live Web Data Access
Most RAG implementations rely on pre-indexed data, which creates a knowledge cutoff the moment that index stops reflecting the current state of the world.
For enterprise agents, this infrastructure must transition to Just-In-Time (JIT) data retrieval. The “re-indexing tax” is a major bottleneck for autonomous agents. By switching to just-in-time (JIT) data retrieval, such as pulling in fresh, structured information exactly when it’s needed, you avoid the delays and limitations of constantly re-indexing data in the background.
This live-data layer is usually treated as an afterthought, but the right web search capabilities are what keep an agent’s reasoning grounded in reality. Most teams underinvest in this layer, but without it, agent outputs become stale, brittle, and difficult to trust.
Production Requirements:
- Real-time retrieval across complex web environments, including JavaScript-rendered pages.
- Structured, machine-consumable outputs that require no heavy post-processing by the agent.
- Semantic search capabilities to ensure retrieved results are highly relevant to the active query.
- Validation layers that check freshness, consistency, and extraction quality before data reaches the agent.
- Anti-blocking orchestration and self-healing extraction to maintain data flow.
- Purpose-built platforms like Nimble browse the live web in real time, validating extraction quality, and returning structured, analysis-ready data that agents can use directly.
5. Security, Guardrails, and Governance
As agents gain the ability to move and act on data autonomously, security and governance need to be built into the architecture, or it creates a compliance liability from day one. A dedicated security layer functions as a real-time policy enforcement point, validating inputs and outputs against defined rules and acting as a circuit breaker that keeps agents within sanctioned boundaries. Governance means maintaining full auditability, so that every action an agent takes is traceable back to a specific rule or policy decision.
Production Requirements:
- Input and output guardrails to filter sensitive information or malicious instructions.
- Least-privilege access controls to ensure agents only touch necessary data.
- Full audit trails to satisfy GDPR, CCPA, and industry-specific compliance standards.
- Prompt injection mitigation that validates retrieved data before it reaches the model.
6. Observability and Evaluation
Observability and evaluation are two distinct but complementary systems. Observability covers real-time monitoring of agent runs to track what the agent did, when, and how. Evaluation covers a structured assessment of output quality, measuring whether what the agent did was actually correct.
Both are necessary because standard monitoring tools are built for deterministic API calls, not the non-deterministic, multi-step behavior of autonomous agents. Without both in place, agents are black boxes that only allow you to see that something went wrong, but not where or why.
Production Requirements:
- Full trace logging for reasoning steps, tool calls, latency, and token consumption.
- Anomaly detection to identify unusual agent behavior or unexpected cost spikes.
- Evaluation infrastructure utilizing ground truth datasets and automated scoring.
- Human-in-the-loop review cycles to refine agent accuracy over time.
- Implementation of tools like LangSmith, Arize, Helicone, or OpenTelemetry.

7. Compute and Runtime Infrastructure
Compute and runtime infrastructure encompasses the execution environment, resources, and operational systems that keep agents running reliably at scale. Agent workloads are long-running, bursty, and stateful; and standard API deployment patterns are not designed for them.
A task that runs for minutes or hours needs persistent context throughout, and the underlying infrastructure needs to handle the unpredictable demand patterns that come with autonomous operation.
Production Requirements:
- Containerization using Kubernetes or Docker with specific session management for concurrent instances.
- Latency optimization across tool calls and retrieval to prevent compound delays in workflows.
- Cost visibility and circuit breakers to protect against runaway inference spend.
- Resilience features like checkpoints and resume to recover from system interruptions.
- Multi-region availability SLAs to ensure the agent is always reachable.
Bridging the Gap from Demo to Production
The seven components detailed in this article are deeply interdependent, and a weakness in any one of them will inevitably constrain the performance of the entire system. Live data access has the most direct and immediate impact on the quality of an agent’s output, because an agent can only be as reliable as the data it operates on.
Nimble is the Web Search Agent Platform purpose-built for the live data access layer. It browses the live web in real time, validates and structures outputs, and delivers analysis-ready data directly into AI agent workflows. The platform provides a data foundation built for production, with enterprise-grade reliability, compliance-first design, and self-healing extraction at scale.
Nimble’s AI Search API gives agent-native teams access to live, structured web data at inference time, improving factual grounding when current information matters, while the Web API and SDK give engineering teams control over extraction logic without forcing them to build and maintain their own proxy and browser infrastructure.
Book a Nimble demo to see how the platform delivers the live, structured web data that production agents need.
FAQ
Answers to frequently asked questions
%20(1).png)
.avif)
.png)

.png)
.png)