Your AI Agents Are Only as Good as Their Web Access. Most Have None.
.avif)
Ilan Chemla


Your AI Agents Are Only as Good as Their Web Access. Most Have None.
Ilan Chemla
Most popular articles

Get structured, reliable data for your stack.
A perspective for technology leaders on why web intelligence is the missing layer in enterprise AI — and what to do about it.
Every enterprise is building AI agents. Research copilots, competitive intelligence tools, due diligence automation, customer-facing assistants. The reasoning capabilities are extraordinary. GPT-4, Claude, Gemini — they can analyze, synthesize, and recommend at a level that was unimaginable three years ago.
But there's a gap that almost no one is talking about.
General search tools are simply too high level.
They can reason about data you give them. They can search your internal documents. But the moment they need to check a competitor's pricing page, verify a company's latest funding round, or pull real-time news about a regulatory change — they fail. Silently. They either hallucinate an answer from training data, or they return nothing at all.
This is not a model problem. It's an infrastructure problem. And it's the single biggest blocker to moving AI agents from prototype to production.
The Web Is the World's Largest Database — and Your Agents Can't Read It
Consider what your teams do every day:
- Sales researches prospects before calls — manually Googling names, checking LinkedIn, reading company blogs
- Strategy monitors competitors — scanning news, tracking product launches, following hiring signals
- Compliance watches regulatory changes — checking government portals, reading policy updates across jurisdictions
- Investment teams do due diligence — pulling filings, tracking executive moves, reading market commentary
All of this is web data. Public, available, constantly changing. And all of it is done manually — or not at all — because the AI tools these teams use have no reliable way to access it.
The irony is striking: we're building AI systems that can reason at superhuman levels, but we haven't given them the ability to read a webpage.
Why "Just Add Web Search" Doesn't Work
The obvious answer — "just plug in a web search API" — misses the point entirely. Here's why:
- General web search can’t meet enterprise needs. It’s optimized for surface-level answers, not for complete data retrieval. It lacks depth, misses real-time changes, and provides no guarantee that you’re seeing the full picture.
- One-off lookups don't scale. Every web query is treated as a fresh, independent task. There's no way to say "extract product data from Amazon the same way every time" or "monitor this set of competitors weekly and only tell me what changed." Without reusability, web-powered agent workflows are expensive, inconsistent, and impossible to audit.
- There's no governance layer. When an agent searches the web on behalf of your organization, who controls which sources it accesses? How do you ensure it doesn't cite unreliable sources in a client-facing report? How do you reproduce a result six months later when a regulator asks? Consumer search tools provide none of this.
- Raw web access creates more problems than it solves. Give an agent a basic web scraper and it will return thousands of tokens of HTML noise. The LLM then has to parse this noise, burning context, increasing latency, and — critically — increasing the probability of extraction errors. In regulated industries, an error isn't a UX problem. It's a compliance risk.
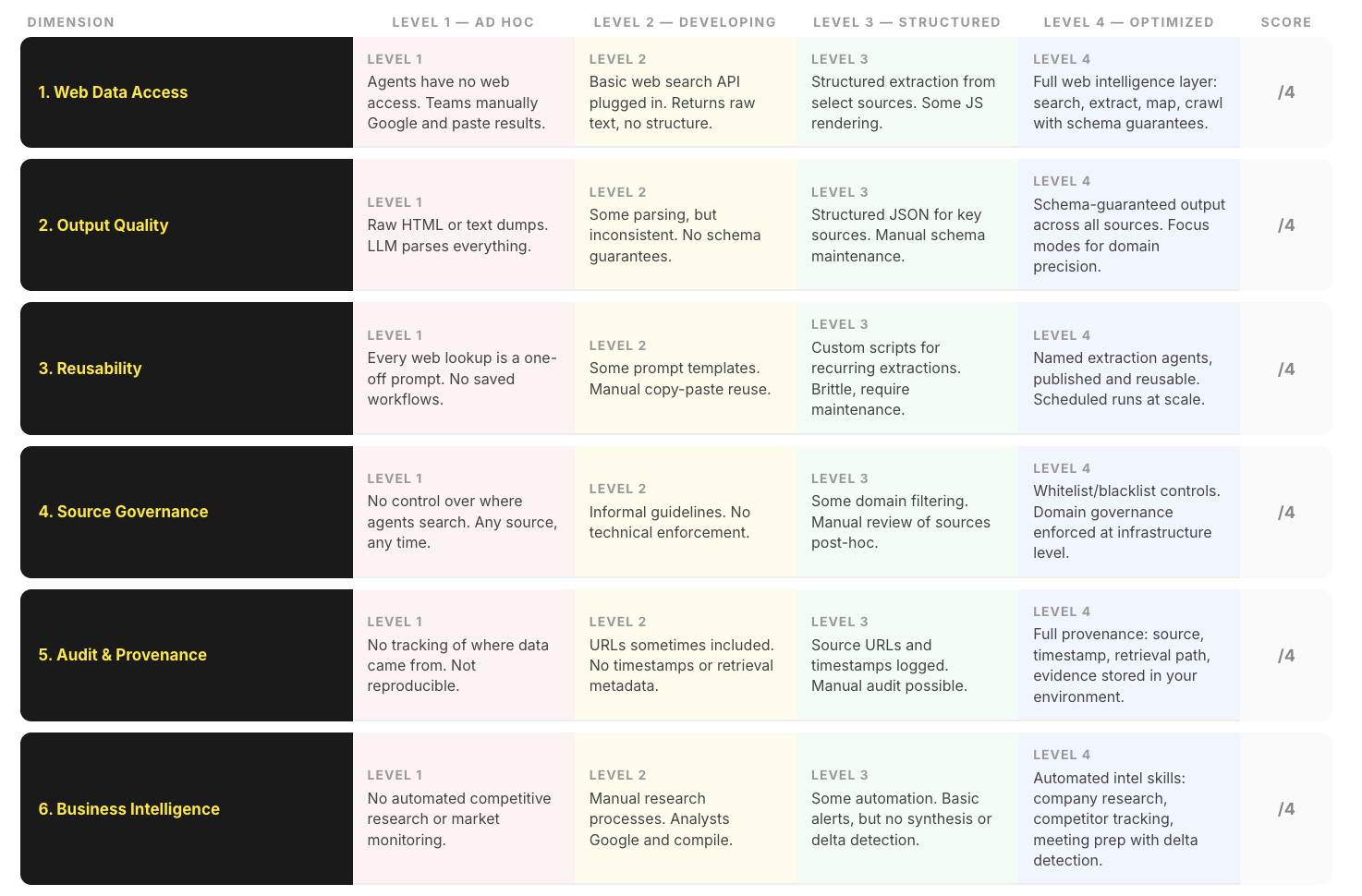
The Missing Layer: Structured Web Intelligence for Agents
What enterprise AI agents actually need is not "web search." They need a web intelligence layer — infrastructure purpose-built to give agents reliable, structured, governed access to live web data.
This is the category Nimble created.
The distinction matters:
This isn't an incremental improvement over web search. It's a different category of infrastructure — one that sits between your AI agents and the open web, and makes the connection reliable enough for production use.
What This Looks Like in Practice
Rather than describing capabilities in the abstract, here are three scenarios that illustrate the difference:
Scenario 1: Competitive Intelligence That Doesn't Go Stale
- Before: A strategy analyst manually searches Google for competitor news every Monday morning. They check 5-6 competitors, scan headlines, copy-paste relevant findings into a doc. It takes 2-3 hours. By Wednesday, it's already stale.
- After: An AI agent with Nimble's competitive intelligence skill monitors all competitors continuously. It uses domain-specific search to target trusted business news sources, tracks product launches, hiring signals, funding rounds, and partnership announcements. It compares new findings against what it found last time — and only surfaces what's changed. The analyst reviews a structured briefing in 10 minutes, with every finding linked to its source.
The key difference isn't speed. It's delta detection — the system knows what's new and what's noise, because it maintains state across runs.
Scenario 2: Meeting Prep That's Actually Useful
- Before: A sales rep has a call with a VP of Engineering at a prospect company in 30 minutes. They quickly search LinkedIn, skim the company blog, maybe check Crunchbase. They walk in with a generic understanding and hope the conversation reveals what they need.
- After: The rep says "prep me for my meeting with Sarah Chen at Datadog." The AI agent researches Sarah's background, recent public activity, and role. Simultaneously, it pulls the latest company news, funding status, product launches, and competitive positioning. It produces a structured briefing with personalized talking points calibrated for a sales discovery call — including pain points to probe, competitive context, and conversation starters tied to Sarah's recent work.
The key difference isn't automation. It's specificity — the output is tailored to the meeting type, the attendees, and the strategic context.
Scenario 3: Due Diligence That's Auditable
- Before: An investment team needs to evaluate a target company during a 2-week diligence window. Junior analysts manually pull data from dozens of sources — filings, news, LinkedIn, Crunchbase, industry reports. Information is copy-pasted into slides. Sources are inconsistently tracked. When a partner asks "where did this number come from?" — nobody can answer quickly.
- After: An AI agent with Nimble's company deep dive skill runs 5 parallel research streams: funding, product, leadership, news, and competitive position. Every finding is linked to its source URL and retrieval timestamp. The output is a structured report with citations that can be traced, verified, and reproduced. When the partner asks where a data point came from, the answer is one click away.
The key difference isn't comprehensiveness. It's auditability — every data point has provenance, which is a requirement in regulated environments.
The Strategic Lens: Why This Matters for AI Leadership
If you're a CIO, VP of AI, or Chief Data Officer, here's the strategic frame:
- Your AI agent strategy has a data gap. You've invested in models, in prompt engineering, in RAG pipelines for internal data. But you haven't solved the external data problem. Your agents can search your Confluence, but they can't search the web reliably. This limits their value to internal knowledge work — and leaves the highest-value use cases (competitive intel, market research, due diligence, compliance monitoring) on the table.
- The gap is infrastructure, not intelligence. The models are good enough. What's missing is the plumbing between your agents and the live web. This is a solvable problem — but it requires purpose-built infrastructure, not a hacked-together web scraping pipeline.
- The governance requirement is non-negotiable. In regulated industries — financial services, healthcare, legal — every piece of data an agent surfaces may end up in a regulatory filing, a client report, or a board presentation. If you can't trace it to its source, you can't use it. This eliminates consumer search tools and DIY scrapers from consideration.
- The build-vs-buy math is clear. Building reliable web extraction infrastructure is genuinely hard. JavaScript rendering, anti-bot bypass, rate limiting, structured output parsing, schema guarantees, evidence storage — this is not a weekend project. And maintaining it is worse: websites change their structure constantly, breaking scrapers and requiring ongoing engineering attention. The total cost of ownership for in-house web infrastructure typically exceeds specialized solutions within 3-6 months.
The Category: AI Web Intelligence Infrastructure
We believe "AI web intelligence" is an emerging infrastructure category — distinct from web search, distinct from web scraping, distinct from data providers. It sits at the intersection of:
- Search infrastructure — live web retrieval with freshness guarantees
- Structured extraction — schema-guaranteed output, not raw text
- Agent orchestration — reusable workflows that compose into larger pipelines
- Enterprise governance — source control, audit trails, evidence storage
Nimble has processed over 1.2 billion searches daily, deployed 40,000+ verticalized agents per day, and serves 200+ enterprise customers including Anthropic, Deloitte, Microsoft, and Databricks. We built this infrastructure because we saw the gap — and because we believe the next wave of enterprise AI value depends on closing it.
What To Do Next
If you're evaluating how to give your AI agents reliable web access, here's where to start:
- Audit your current state. How are your AI agents accessing web data today? If the answer is "they're not" or "we built something fragile" — you have the gap.
- Identify your highest-value use case. Competitive intelligence, meeting prep, due diligence, compliance monitoring, market research — which one would deliver the most value if it were automated and reliable?
- Run a proof of concept. Nimble Agent Skills installs in 5 minutes and includes a free tier of 5,000 pages. Pick one use case, run it, and evaluate the output quality against your current manual process.
- Evaluate the governance requirements. If you're in a regulated industry, ask: can we trace every web-sourced data point to its original URL, timestamp, and retrieval parameters? If not, you need governed infrastructure.
The AI agents of 2026 will be defined not by their reasoning capabilities — those are table stakes — but by their ability to access, structure, and govern the world's most valuable data source: the live web.
The question isn't whether your agents need web intelligence. It's whether you're going to build it yourself, or use infrastructure purpose-built for the job.
Nimble is the AI search platform for enterprise agents. Trusted by Anthropic, Deloitte, Microsoft, Databricks, and 200+ enterprise customers. Learn more at nimbleway.com.
To discuss how Nimble fits your AI agent strategy, reach out for a free consulting session — we'll help you design a targeted proof of concept for your highest-value use case.
FAQ
Answers to frequently asked questions
.avif)
.png)

.png)
.png)