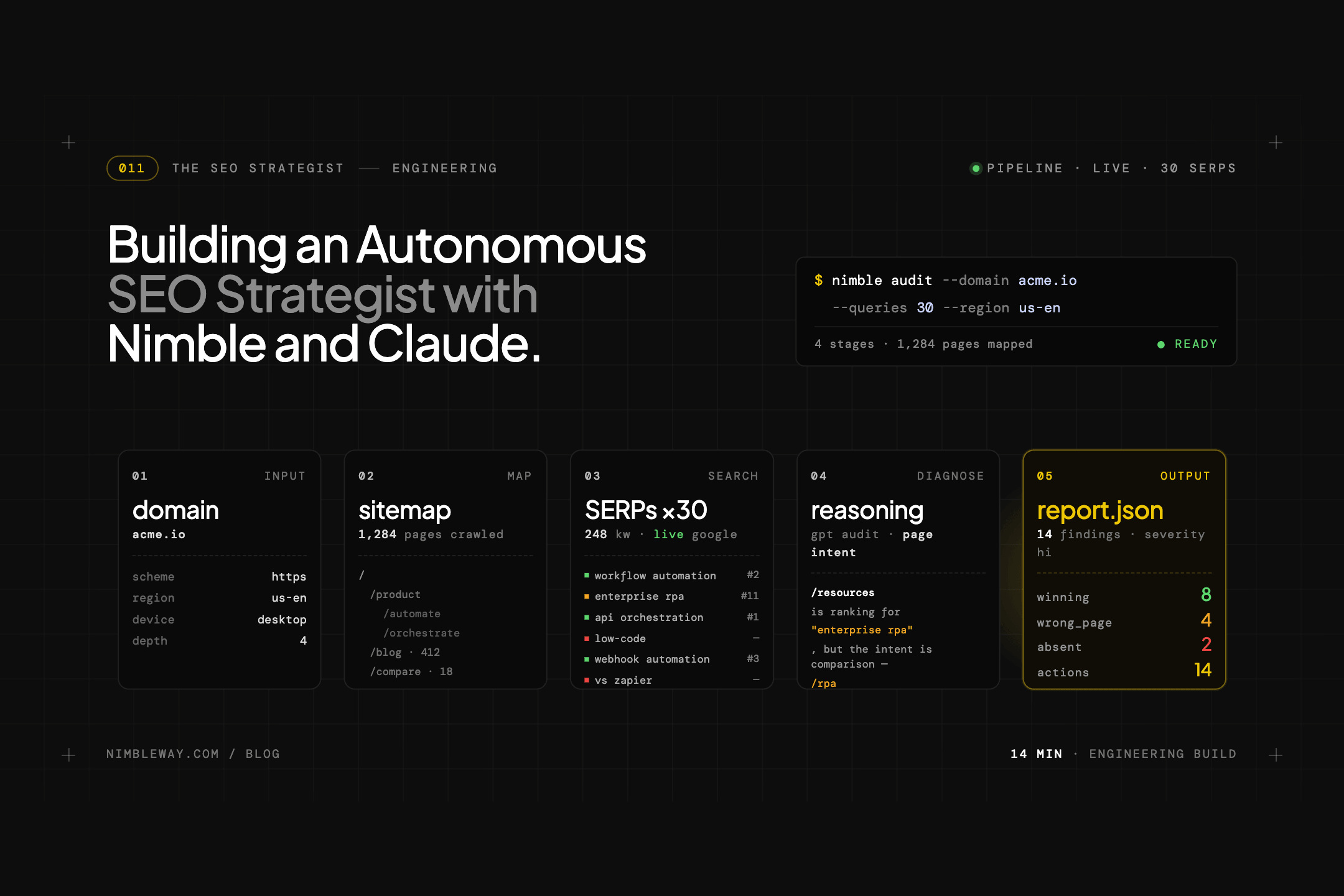
The Hidden Bottleneck in AI Agents: 98% of the Web Is Noise

Uri Knorovich

The Hidden Bottleneck in AI Agents: 98% of the Web Is Noise
Uri Knorovich
Most popular articles


Get structured, reliable data for your stack.
AI agents are supposed to make the web more useful, but what if the web is actually making AI agents worse?
A recent analysis of 250 real-world queries in the retail sector uncovered something surprising and, frankly, alarming: on average, 97.9% of the data that AI agents retrieve from web pages is irrelevant to the question they’re trying to answer.
That’s not a rounding error. That’s a structural problem.
And while this particular dataset focuses on retail, the implications extend far beyond it, into every industry that relies on live web data for AI.
Here’s What Happens When AI Agents “Browse” the Web
To understand how AI agents interact with the web, we analyzed 250 realistic queries across a handful of common retail tasks:
- Product prices
- Customer ratings
- Discounts
- Availability
- Product specifications
- Shipping policies
For each query, an AI agent retrieved a webpage (just like many production systems do today) and attempted to extract the answer. What we measured was simple: How much data did the agent ingest? And how much of that data actually mattered?
The answer revealed a massive imbalance.
The Signal-to-Noise Problem is Bad
Here are some high-level datapoints that start to paint the picture. Across all queries:
- Average page size: 8,795 characters
- Average answer size: 31.7 characters
- Noise per signal: 278×
In aggregate, less than 0.4% of all data processed was actually useful. For anyone who thinks they’re using agentic AI efficiently, that’s a tough pill to swallow. In this retail example, AI agents are effectively reading entire product pages, parsing navigation menus, ads, reviews and disclaimers, all to extract something as small as a product price.
It Gets Worse: The Price Query Problem
Price queries were the most extreme example. To answer a question like “What is the price of the Apple AirPods Pro (2nd gen)?” an agent might retrieve 27,000-plus characters of page content just to extract a four-character answer like “$174.”
That’s a 99.48% noise rate.
Even worse, the page doesn’t just contain one price. It contains discounted prices, bundle prices, prices for other configurations, sponsored listings, and historical references in reviews.
That means the agent isn’t just inefficient. It’s also navigating a sea of potentially plausible but likely incorrect answers.
This Matters More Than You Likely Think
These tidbits are fun for tech and data nerds to chew on, but they’re more just a curiosity. They can have real consequences on two fronts:
1. Accuracy degrades. Large language models struggle when context is long, relevant information is sparse and multiple “almost correct” answers exist.
Unfortunately for retail, this is exactly what most pages across the industry look like. And the result can be things like wrong prices, incorrect availability information or misinterpreted product specs. It’s not because the model is bad; it’s because the input is messy.
2. Costs skyrocket. LLMs charge by tokens, and tokens come from text. At roughly four characters per token, which is the general rule of thumb, that 8,795-character page becomes closer to 2,200 tokens.
Now multiply that by thousands of queries per day and multiple retrieval steps per query. You’re paying to process millions of characters of useless data. In fact, in this dataset alone, the vast majority of costs would be tied to data that never contributes to the answer the user is looking for.
It’s Not a Retail Problem. It’s an Internet Problem.
This retail example makes the core issue more obvious, but the same pattern shows up everywhere:
- Finance: Extracting a single metric from earnings reports.
- Travel: Finding availability or pricing from booking pages.
- Real estate: Pulling property details from listing sites.
- Healthcare: Identifying specific data points from provider pages.
There are many other examples you could think of, but in every case, the web is optimized for humans, not machines. This means AI agents need to retrieve entire pages, interpret messy layouts, and attempt to filter signals from overwhelming noise. And they likely repeat this process query after query, at scale.
The Missing Piece of AI Infrastructure: Real-Time Web Intelligence
There’s a common assumption that improving AI performance means better models, larger context windows or more sophisticated reasoning.
But in reality, this dataset suggests the model’s not at fault. The biggest bottleneck isn’t reasoning; it’s retrieval. Think about it: if 97.9% of your input is irrelevant, no model can fully compensate for that.
What really matters is how data is collected, how it’s structured and how much of it is actually needed. Thus, the findings point to a clear shift in how AI systems should be designed:
- Don’t ingest everything. Retrieve precisely. Pull only what’s needed, not entire documents.
- Prefer structured data over raw HTML. If the answer exists as a field, don’t extract it from prose.
- Treat data efficiency as a first-class metric. Go beyond latency or accuracy and account for signal-to-noise ratio.
Turning Web Pages into Web Intelligence
The internet isn’t going anywhere (obviously). But how AI interacts with it is already changing significantly. At Nimble, we’re helping agent builders move from page retrieval to data retrieval, from unstructured content to structured intelligence, and from brute-force ingestion to precise extraction.
And the teams that recognize this early will build more reliable AI agents, more cost-efficient systems, more scalable data pipelines and, ultimately, a bigger competitive advantage.
FAQ
Answers to frequently asked questions
%20(1).png)
.avif)

.png)
.png)