Top 9 Amazon Scraping APIs
.avif)
Ilan Chemla
%20(1).png)
Top 9 Amazon Scraping APIs
Ilan Chemla
Most popular articles

Get structured, reliable data for your stack.
Top 9 Amazon Scraping APIs
If you look closely, the world’s largest e-commerce platform, Amazon.com, functions less like a true marketplace and more like a high-speed data ecosystem. For enterprises, AI companies, and data aggregators, the ability to act on real-time, structured Amazon data is the difference between leading the market and reacting to it.
Success on Amazon now hinges on a dependable data supply, and the increased demand for it is behind the rising global market for data extraction software that's projected to reach $3.99 billion by 2032. But getting reliable Amazon data is not as easy as it might appear.
Amazon’s frequent layout changes and aggressive anti-bot systems make building and maintaining internal extraction tools a constant, unreliable battle. Internal scripts are brittle, leading to gaps, delays, and dirty data that requires extensive cleaning. This results in outdated data that forces business decisions to be made with only partial visibility.
The solution is to utilize a dedicated Amazon Scraping API (Application Programming Interface) that replaces unstable internal methods with a consistent data source that doesn’t require constant engineering effort. Amazon Scraping APIs manage scaling, IP rotation, and error handling while supporting compliance-aligned practices for collecting public Amazon data. Let’s explore the top nine solutions enterprises rely on to extract it reliably and at scale.
What is an Amazon Scraping API?
An Amazon Scraping API is a third-party, unofficial Application Programming Interface that enables you to programmatically extract publicly available data from Amazon’s product pages, search results, reviews, and other listings. These specialized tools are offered by a vendor that manages all the technical challenges of extracting data from Amazon’s website on your behalf.
Here’s how Amazon Scraping APIs work:
- First, you send a request, such as a URL or an ASIN, to the Amazon Scraping API endpoint.
- The service then handles:
- Page access
- Anti-bot measures
- HTML parsing
- Returning the result as clean, structured data, typically in formats like JSON
The resulting data can be easily integrated into analytics workflows, model training, or internal business systems.
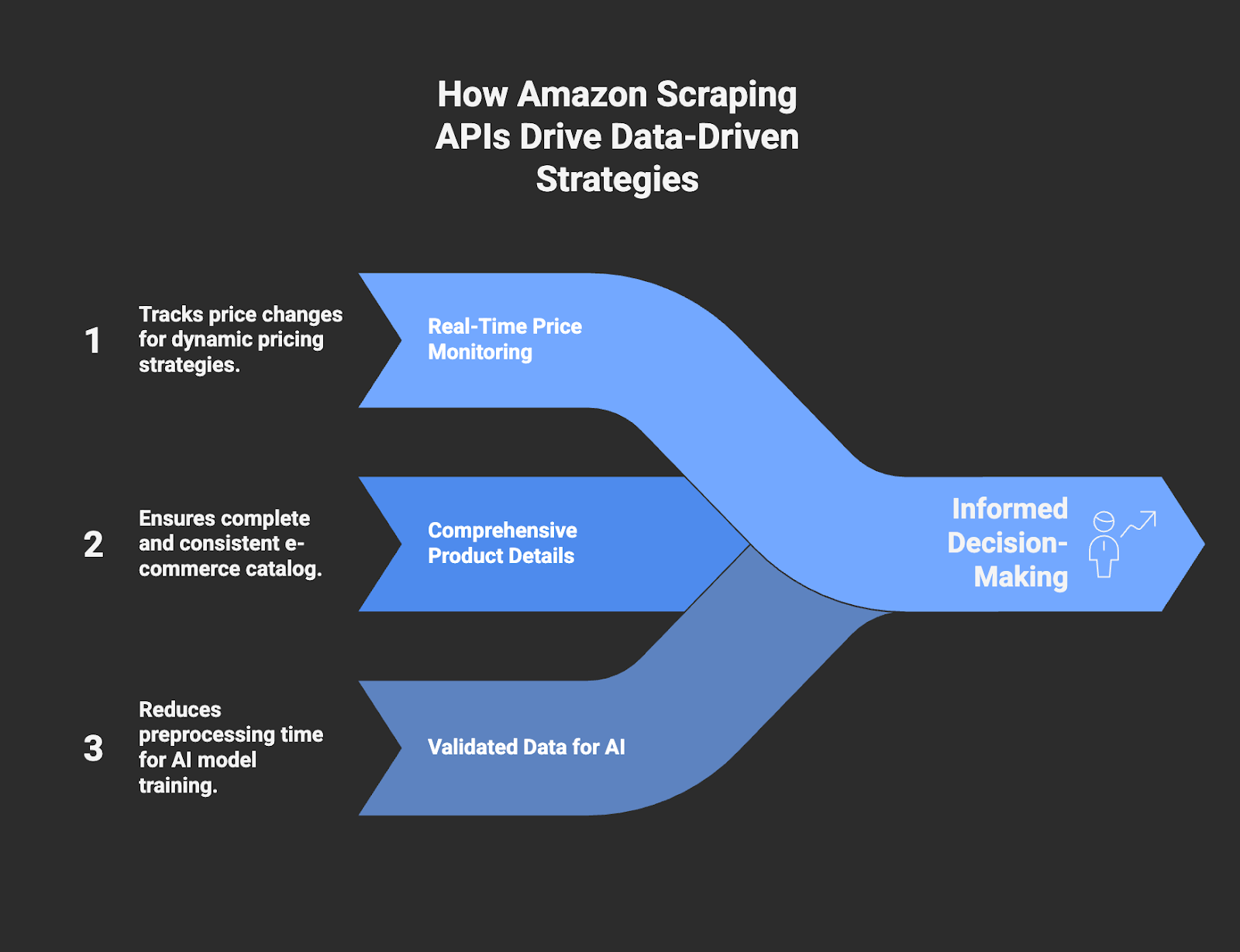
Amazon Scraping APIs are used by teams that depend on accurate, up-to-date marketplace information to support both operational and strategic decisions, including:
- Developers and engineers who need real-time, structured data feeds for building BI dashboards, data lakes, or analytics workflows.
- Data and analytics leaders who require trusted market intelligence on pricing, promotions, inventory, and customer reviews.
- Teams at LLM and AI companies that need clean, diverse, and continuously updated datasets.
These teams scrape Amazon data to support use cases such as:
- Monitoring and tracking real-time price changes to support dynamic pricing strategies.
- Collecting product details to keep your internal e-commerce catalog complete and consistent.
- Validated, normalized data for AI and LLM training that reduces preprocessing time and supports more consistent model outputs.
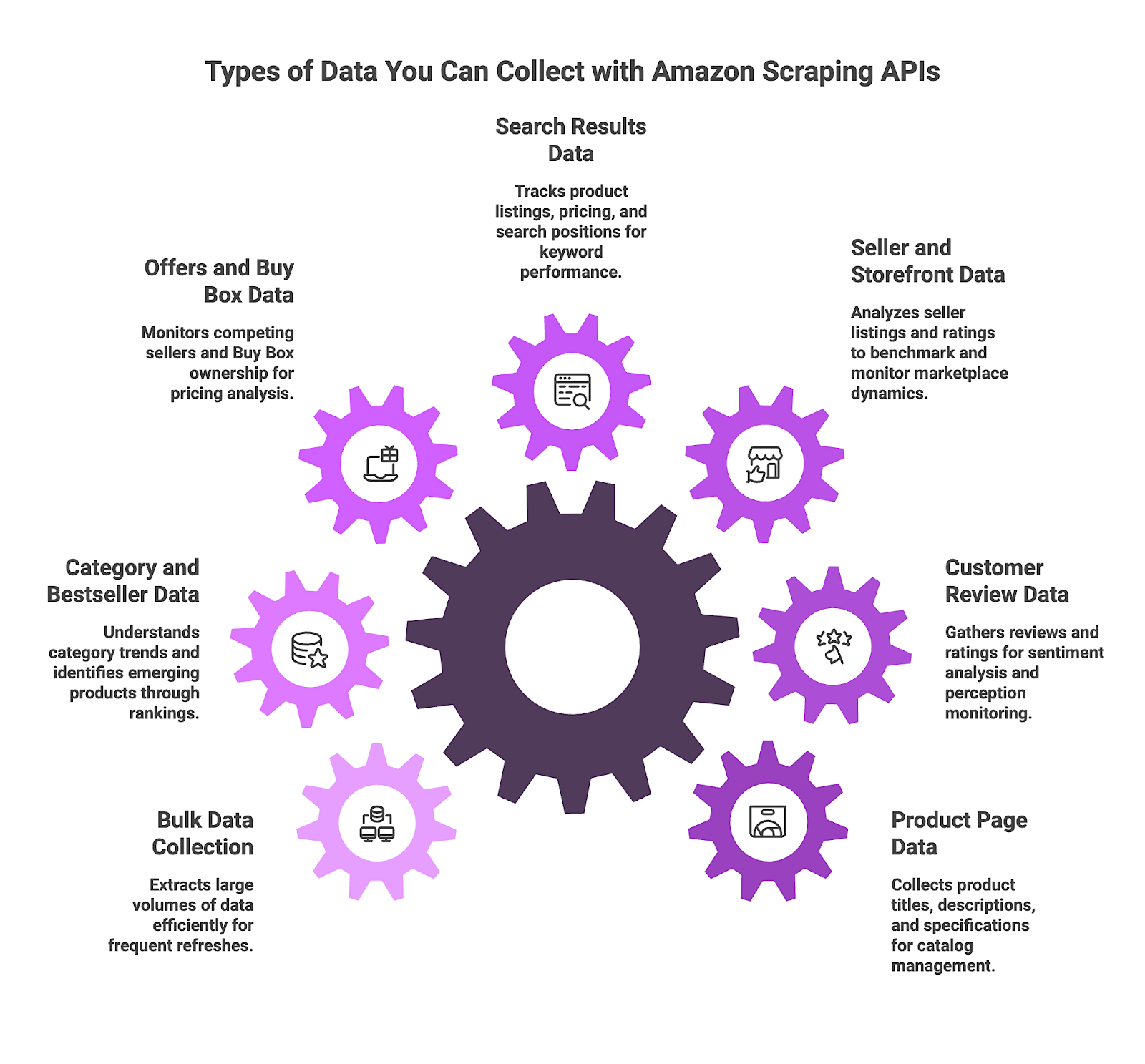
Types of Data You Can Collect with Amazon Scraping APIs
Amazon scraping APIs are used to collect different types of publicly available Amazon data, depending on the page being accessed and the information being extracted. This data includes:
- Product Page Data – This data includes product titles, descriptions, availability, and specifications. Teams use it to keep internal product catalogs complete and aligned with live marketplace listings.
- Customer Review Data – Review data includes customer-written reviews, star ratings, and review dates. It is commonly used for sentiment analysis and to monitor how customer perception changes over time.
- Seller and Storefront Data – Seller-level data covers storefront listings, seller ratings, and fulfillment methods. This information helps teams benchmark sellers and monitor marketplace dynamics.
- Search Results Data – Search data is collected from Amazon search result pages and includes product listings, pricing, and search position. It is often used to track visibility and performance for priority keywords.
- Offers and Buy Box Data – Offer-level data focuses on competing sellers, Buy Box ownership, and price changes. This data supports real-time pricing analysis and competitive monitoring.
- Category and Bestseller Data – Category data includes category hierarchies and bestseller rankings. Teams use it to understand category trends and identify emerging products.
- Bulk Data Collection – Bulk collection refers to extracting any of these data types at scale through batch or asynchronous workflows, enabling frequent refresh cycles across large catalogs.
What a Production-Ready Amazon Scraping API Should Enable
A production-ready API needs to support reliable, ongoing data collection in real operating conditions by enabling:
Reliable Access to Amazon Data
The API should maintain consistent access even through Amazon updating page layouts or introducing new anti-bot measures. This reliability reduces data gaps and prevents interruptions in downstream analytics and reporting.
Consistent, Structured Output
Clean, predictable data structures are critical for downstream use. A well-built API should return normalized outputs that can be ingested into analytics systems without extensive reprocessing or manual fixes.
Reduced Engineering Overhead
When extraction logic, parsing, and error handling are managed by the Amazon scraping API vendor, engineering teams spend less time maintaining scrapers and more time working on core business systems and data applications.
Timely Visibility Into Marketplace Changes
Access to frequently updated Amazon data enables teams to respond faster to pricing changes, stock shifts, and competitive activity rather than relying on delayed or incomplete snapshots.
Scalability for High-Volume Workloads
As data needs grow, a production-grade API should support larger request volumes and batch workflows without degradation, which makes it possible to expand from limited monitoring to broad, multi-market coverage.
Sustained Data Freshness
Ongoing data collection should be repeatable and dependable over time. APIs designed for long-term use support scheduled refreshes that keep marketplace data current without constant revalidation.
Key Features to Look for in an Amazon Scraping API
When choosing an Amazon Scraping API, evaluate these features that matter for production-grade data extraction
.png)
Top 9 Amazon Scraping APIs
1. Nimble
Nimble provides multiple ways for teams to collect Amazon data, depending on how much control and operational involvement they want. Instead of offering a single scraping interface, the platform supports three distinct approaches to Amazon data extraction:
- Teams that want out-of-the-box access can use Web Search Agents to receive continuously collected Amazon datasets that are streamed directly to their endpoint. These agents handle navigation, data extraction, and ongoing updates, making them suitable for teams that need reliable, regularly refreshed Amazon data without building custom logic.
- For teams that require more control, Nimble offers an SDK-based approach that allows developers to customize how Amazon data is collected. This option is designed for cases where teams need to define specific fields, extraction logic, or workflows while still relying on Nimble’s underlying infrastructure for execution and access.
- Nimble also offers a fully managed service for organizations that prefer a hands-off model. In this case, teams describe the Amazon data they need, and Nimble delivers the required dataset without customers having to design or operate the extraction process themselves.
Key Features:
- Analysis-ready outputs with stable field definitions suitable for direct ingestion
- Support for continuous and large-scale Amazon data collection
- Flexible delivery of Amazon data through APIs, SDKs, or managed workflows
- Resilient execution that adapts to changes in Amazon page behavior
- Compliance-aligned collection focused on publicly available Amazon data
Best for: E-commerce and data teams that need Amazon data to understand market behavior at scale.
Review: “Nimble has become our default platform for collecting public web data. We use a combination of Nimble IP and the Web API to route requests through residential proxies and reliably unlock sites that were very unstable with other providers. The thing I like most: High success rates & stability.”
2. WebScrapingAPI

WebScrapingAPI delivers an Amazon Product API that is purpose-built for high performance and scalability. It achieves sophisticated data extraction by using full-browser rendering and executing JavaScript directly, ensuring the returned data is identical to what a human user sees.
Key Features:
- Uses robust page parsing, full-browser rendering, and JavaScript execution for accuracy.
- Multiple dedicated endpoints for Search Product Offers and Reviews.
- Supports geo-targeting with Zipcode and Postcode localization.
Best for: Users needing a feature-rich, dedicated Amazon API with advanced ML-powered parsing and support for hyper-localized data.
Review: “Data extraction is reliable and auto extraction means less human intervention required, resulting in less errors. In short, it looks after itself.”
3. Decodo
Decodo (formerly Smartproxy) designed its Amazon scraping API to include a web scraper, a parser, and a large proxy pool. Requests can be made without encountering CAPTCHAs or IP blocks, and returned data can be consumed in standardized formats like HTML or JSON.
Key Features:
- Integrated browser fingerprints
- Vast country-level targeting options
- Built-in scraper and parser
- JavaScript rendering
Best for: Growing businesses seeking a cost-effective solution with a high volume of built-in residential proxies and AI-powered parsing.
Review: “Decodo provides great service with a simple setup and (a) friendly support team.”
4. Scrapingdog
Scrapingdog provides an Amazon Scraper API that automatically handles proxies and anti-detection measures. It is designed for ease of use while delivering real-time, comprehensive product information.
Key Features:
- Deep product-level data extraction that captures titles, prices, customer ratings, and detailed descriptions for a specific query or ASIN.
- Manages the complete anti-bot lifecycle for blockage-free data extraction.
- Delivers structured data in clean Markdown or JSON format that’s optimized for LLM training and ingestion.
Best for: A straightforward, entry-level API for Amazon data collection.
Review: “We use Scrapingdog's Amazon scraping API and it works exactly as we need.”
5. Oxylabs (Web Scraper API)
Oxylabs' Web Scraper API lets you retrieve Amazon product data through a simple API request with no initial setup. The service supports multiple Amazon page types using built-in parsers, with the option to create custom parser configurations that adapt as pages change.
Key Features:
- Dedicated endpoint for the Amazon website within its general Web Scraping API.
- Leverages a large proxy pool to bypass anti-bot measures and provide geo-targeting.
- Supports multiple output formats: parsed JSON or raw HTML.
Best for: Enterprise developers who require a highly stable scraping infrastructure with extensive proxy access for complex, large-scale data collection projects.
Review: “When it comes to the speed and uptime, I can’t complain as it meets my data extraction needs in a reasonable time.”
6. ScraperAPI

ScraperAPI allows teams to track competitor activity across regions with granular geographic targeting. Current e-commerce intelligence helps reveal how competitors adjust pricing and respond to customer behavior. Users receive clean, structured data directly via a single API request.
Key Features:
- Guaranteed 99.99% success rate on Amazon at scale.
- Returns structured JSON output for product details, reviews, and offers.
- Access to over 40 million IPs and 50+ Geolocations.
Best for: Leveraging localized data combined with automated scraping.
Review: “The team at ScraperAPI was so patient in helping us debug our first scraper.”
7. Bright Data
With Bright Data, teams can extract e-commerce data related to product trends, pricing, and customer feedback across online marketplaces. The service handles scale and access management so users can focus on data usage rather than scraping infrastructure.
Key Features:
- No-code, plug-n-play scraper
- Custom data delivery, including direct transfer to cloud storage, S3, and GCS
- Design your own automation schedules in the control panel
- API authentication using token-based access
Best for: Large enterprises with high volume, complex data extraction needs.
Review: “Good value for the services, integration with various tools, and excellent support.”
8. Zyte API
Focused on automated extraction at scale, Zyte API uses AI-assisted parsing to reduce the need for site-specific extraction logic. It is commonly used for broad, multi-site scraping workloads where maintaining custom parsers would otherwise require significant effort.
Key Features:
- Adapts to different Amazon page structures without manual parser maintenance
- Unified API for rendering, unblocking, and structured data delivery
- Optimized for high-volume scraping across many domains rather than deep tuning per site
Best for: Teams running large, cross-site scraping workloads.
Review: “Zyte API integrates easily with any existing project and offers an optimal tier-like subscription system.”
9. Outscraper
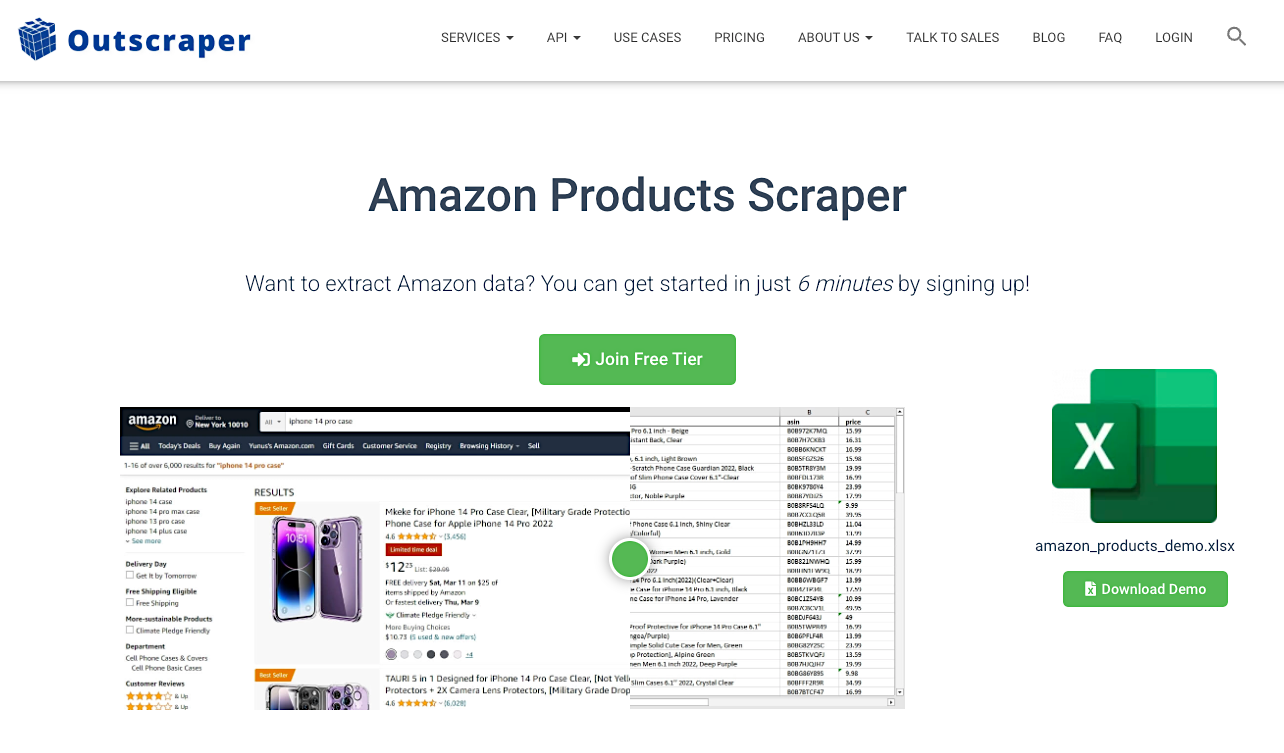
Outscraper’s Amazon Products Scraper API is built around programmatic job-based requests, where users submit extraction tasks and retrieve structured results once processing completes. Jobs are defined through request parameters passed to the API, with collection running asynchronously rather than as a continuously streaming process.
Key Features:
- Support for large result sets returned as structured records suitable for downstream processing
- Ability to run extraction jobs on demand or on a recurring schedule through programmatic requests
- Multiple delivery options for extracted data, including API responses and downloadable files
Best for: E-commerce teams collecting Amazon product data for catalog monitoring or assortment analysis.
Review: “The Outscraper program is cost-effective and very useful for our sales teams.”
Amazon Scraping APIs: Reliable Data for Better Decisions
Amazon is one of the most valuable sources of market and commerce data, but it is also one of the hardest platforms to extract from reliably. To get accurate data, teams are increasingly relying on Amazon scraping APIs instead of building and operating their own extraction systems. However, many Amazon scraping solutions work well initially but struggle as collection needs grow or page behavior shifts. Over time, this creates gaps and operational overhead that undermine the usefulness of the data.
Nimble addresses these issues by providing a web data platform that combines Web Search Agents and programmable APIs to extract structured Amazon data from product and search result pages, while managing execution complexity at the platform level. Amazon data scraping functions as part of a live data workflow rather than a process that requires constant attention. The result is real-time Amazon data that provides a stable foundation for ongoing market intelligence.
Book a Nimble demo to see how our Amazon Scraping API supports reliable, data-driven decision-making.
FAQ
Answers to frequently asked questions
.png)

.png)
.png)
.png)
.png)