The Internet’s New Data Layer: How Web Search Agents Redefine Search, Data, and Discovery

Tom Shaked
.png)
The Internet’s New Data Layer: How Web Search Agents Redefine Search, Data, and Discovery
Tom Shaked
Most popular articles

Get structured, reliable data for your stack.
The Internet’s New Data Layer: How Web Search Agents Redefine Search, Data, and Discovery
How a new class of agents is transforming the way we see, structure, and trust data in a fragmented online world.
The web began with a simple belief - that the world’s knowledge should be shared. Linking pages together was supposed to make information universal and useful. It worked, but only partly. The early web gave us access, not understanding. Billions of pages existed, but they told no clear story.
That changed when we learned to organize it. Google’s search index didn’t just crawl the web; it made sense of it. By categorizing, ranking, and connecting content, it revealed something profound: information only becomes valuable when it’s structured and visible. The web stopped being a list of pages and became a map of knowledge.
That shift rippled outward. Finance firms organized market filings into signals. Travel sites stitched together routes and fares from thousands of carriers. Retailers tracked prices across competitors. Job boards indexed global hiring data. Everyone understood that whoever could collect and structure information could make better, faster decisions.
The API Era: Structure by Partnership
As the web matured, structure became formalized. APIs offered direct, predictable ways to exchange information. Systems could finally talk to each other. A business could plug into another’s data and build something new on top.
But APIs also drew boundaries. Every endpoint reflected what its owner chose to expose. Access came with limits - quotas, keys, permissions, and expiration dates. You could only see what someone else allowed. And as demand for data exploded, many services offered no APIs at all. The vision of an interconnected web became a maze of walls and missing doors.
The Scraping Era: Structure by Engineering
Developers responded the only way they could - by building their own visibility. They built scrapers, scripts that browsed the web directly and pulled data from what was already public. With libraries like Beautiful Soup, Scrapy, and Selenium, the web became programmable again.
It worked, but only through constant effort. A single layout change could break an entire workflow. Teams spent hours fixing selectors, rotating proxies, and dodging anti-bot systems. Scraping worked, but it was fragile, expensive, and rarely scalable. Smaller companies often couldn’t afford to keep up.
The demand didn’t slow down, though. Businesses needed live intelligence: prices, availability, reviews, market signals. Entire service companies formed to offer scraping at scale, yet many of them inherited the same brittleness. Success rates dropped, costs rose, and visibility lagged behind reality. The problem wasn’t access anymore; it was sustainability.
The AI Era: Structure by Understanding
Then came language models. Suddenly, machines could read, summarize, and respond in plain English. They didn’t just retrieve data, they seemed to understand it. For the first time, technology could turn text into conversation, insight, even reasoning.
But the magic had limits. These models knew the world as it was when they were trained, not as it is now. They couldn’t see what had changed yesterday or even last week. And what they didn’t know, they guessed - often confidently and incorrectly. Fluency replaced accuracy.
For decision-making, it simply wasn’t good enough. Intelligence without observation isn’t intelligence at all. To stay relevant, systems need eyes on the live web and not a snapshot frozen in time.
The Expanding Web: Complexity as the Constant
The web didn’t stand still either. It splintered, evolved, and multiplied. Every site built its own conventions, technologies, and structures. Retailers refreshed prices hourly. Marketplaces personalized results by user. News, video, and social data poured in faster than any system could track.
Today’s web is dynamic by design. It’s what makes it vibrant and yet so hard to track. APIs capture only what’s shared. Scrapers crash when pages change. AI models lose sight of the present. The challenge isn’t access anymore; it’s staying synchronized with reality at scale and speed.
The Rise of Agents: A New Model for Web Intelligence
That’s where a new class of software emerged: Agents. Systems that don’t just fetch data, but perceive, decide, and act.
At Nimble, we saw that the same approach could redefine how web data is gathered and trusted. The web needed something more adaptive than scrapers and more observant than APIs. It needed explorers; autonomous navigators that could interpret the live web as it changes.
We call them Web Search Agents.
A Web Search Agent is more than a crawler. It behaves like a user, loading pages, clicking, scrolling, interpreting, and structuring what it sees. It’s guided by a clear mission: what data to collect, from where, and how often. It adapts on the fly when layouts shift or content updates. And every piece of data it delivers is validated, schema-consistent, and analysis-ready.
Unlike traditional scraping systems, Web Search Agents operate within a governed, enterprise-grade platform. Nimble’s infrastructure provides everything they need from residential proxies for scale, AI-driven browsing engines for rendering and network capture, to LLM-based parsing that ensures clean, structured outputs. The result: a continuous, trusted stream of real-time intelligence that reflects the world as it is, not as it was.
How Web Search Agents Work
Each agent begins with a defined goal. It navigates its target environment, executes interactions, and extracts both visible and hidden information such as DOM elements and network calls while maintaining context. The platform validates every record for accuracy and freshness before delivering it to your systems.
For engineers, it means no more brittle scrapers or manual configurations.
For analysts, it means data that’s always clean and complete.
For AI builders, it means models that stay grounded in the live web.
Nimble’s orchestration layer handles everything behind the scenes. Compliance, scaling, fault tolerance, everything needed to enable agents to operate across thousands of domains in parallel.
Built on Nimble’s Proven Infrastructure
Nimble’s Web Search Agents run on the same premium, enterprise-grade infrastructure that powers some of the world’s largest data operations. Every layer of Nimble’s stack is built for performance, resilience, and governance at scale.
- Proxy network ensures access across geographies and retailers without triggering rate limits or blocking.
- Headless browser dynamically renders JavaScript-heavy sites, captures network calls, and scale seamlessly.
- LLM-driven parsing intelligently interprets unstructured layouts and converts them into structured, schema-aligned data across sources, reducing the maintenance burden that plagues traditional pipelines.
- Adaptive driver selection optimizes for speed or completeness based on task requirements, balancing cost with depth.
- Integrated observability and compliance controls deliver full visibility into data lineage, freshness, and governance — essential for enterprise reliability and auditability.
This is not commodity infrastructure. It’s a tightly integrated system, tuned for the unique challenges of web-scale intelligence. The result is unmatched depth, seamless continuity, and unmatched data quality.
Web Search Agents in Practice
In retail, Web Search Agents track millions of SKUs across marketplaces like Amazon, Walmart, and Target, capturing price, availability, and promotion changes as they happen. This allows brands to react to competitor moves within hours instead of weeks, ensuring pricing and assortment decisions stay in sync with the market.
In consumer goods, category managers deploy agents to measure share-of-shelf, banner placements, and content compliance across thousands of product pages daily. When a label changes or a compliance issue emerges, it’s flagged in real time rather than discovered weeks later in a static report.
In financial services, agents aggregate filings, product releases, and regulatory data across multiple jurisdictions, providing analysts with structured, near-live intelligence on market shifts and company behavior.
In AI and RAG workflows, Web Search Agents feed models with live, verified, structured data so that generative systems operate with maximum accuracy and data coverage.
In every case, the result is the same: real-time, structured intelligence that updates itself as the web changes.
Architecture of the Agent Era
Beneath every Web Search Agent is a layered foundation.
The infrastructure layer provides the essentials - optimized proxies, browserless drivers, and intelligent driver selection that balances cost and completeness.
The agent layer adds adaptability - domain-specific navigation, contextual understanding, and schema enforcement.
The delivery layer turns it into value - continuous, validated data streams flowing directly into warehouses, BI dashboards, or AI training pipelines.
Together, these layers transform the open web from a chaotic sprawl into a living structured, searchable, and reliable dataset.
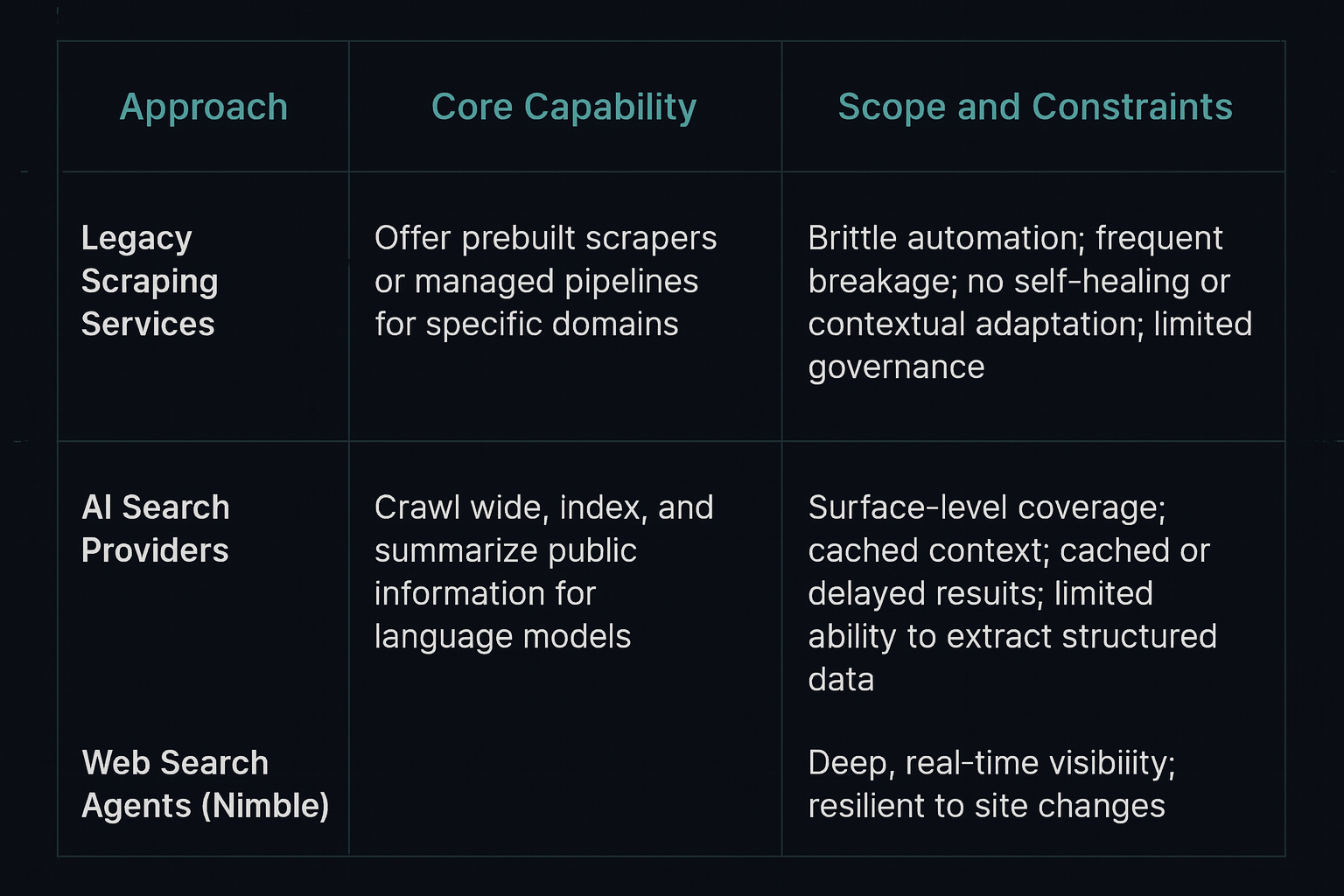
Nimble vs. AI Search and Legacy Providers
The difference between Web Search Agents and other web intelligence tools is not incremental; it’s architectural.
The Future of Public Data
Public web data has always powered innovation. It built search engines, price indexes, recommendation systems, and even the AI models shaping our world. But as the pace of change accelerates, static datasets can’t keep up.
Web Search Agents close that gap. They transform the living web into a governed, continuously updating source of truth. In the coming years, every enterprise, model, and analytical system will rely on them to stay aligned with the real world.
The next era of intelligence won’t belong to systems that know the most - it will belong to systems that see the most.
Web Search Agents are how machines keep their eyes open. And with them, the web becomes not just connected, but continuously understood.
FAQ
Answers to frequently asked questions

.avif)
.png)

.png)
.png)