The Data Accuracy Crisis: How Brand Analysts Can Overcome Retailer Roadblocks to Reliable Insights
Honeypots, blocks, and complex site structures increasingly threaten retail data analytics. Luckily, this can be overcome with adaptive scraping tech.

Landon Iannamico

The Data Accuracy Crisis: How Brand Analysts Can Overcome Retailer Roadblocks to Reliable Insights
Honeypots, blocks, and complex site structures increasingly threaten retail data analytics. Luckily, this can be overcome with adaptive scraping tech.
Landon Iannamico
Most popular articles

Get structured, reliable data for your stack.
Data from retailer brand sites and e-commerce marketplaces fuel retail data analytics.
Brand analysts build business strategies by studying competitor promotions, pricing, digital shelf, inventory, SERP, and customer sentiment data. AI models that automate dynamic pricing, inventory management, and customer support are built from the same data.
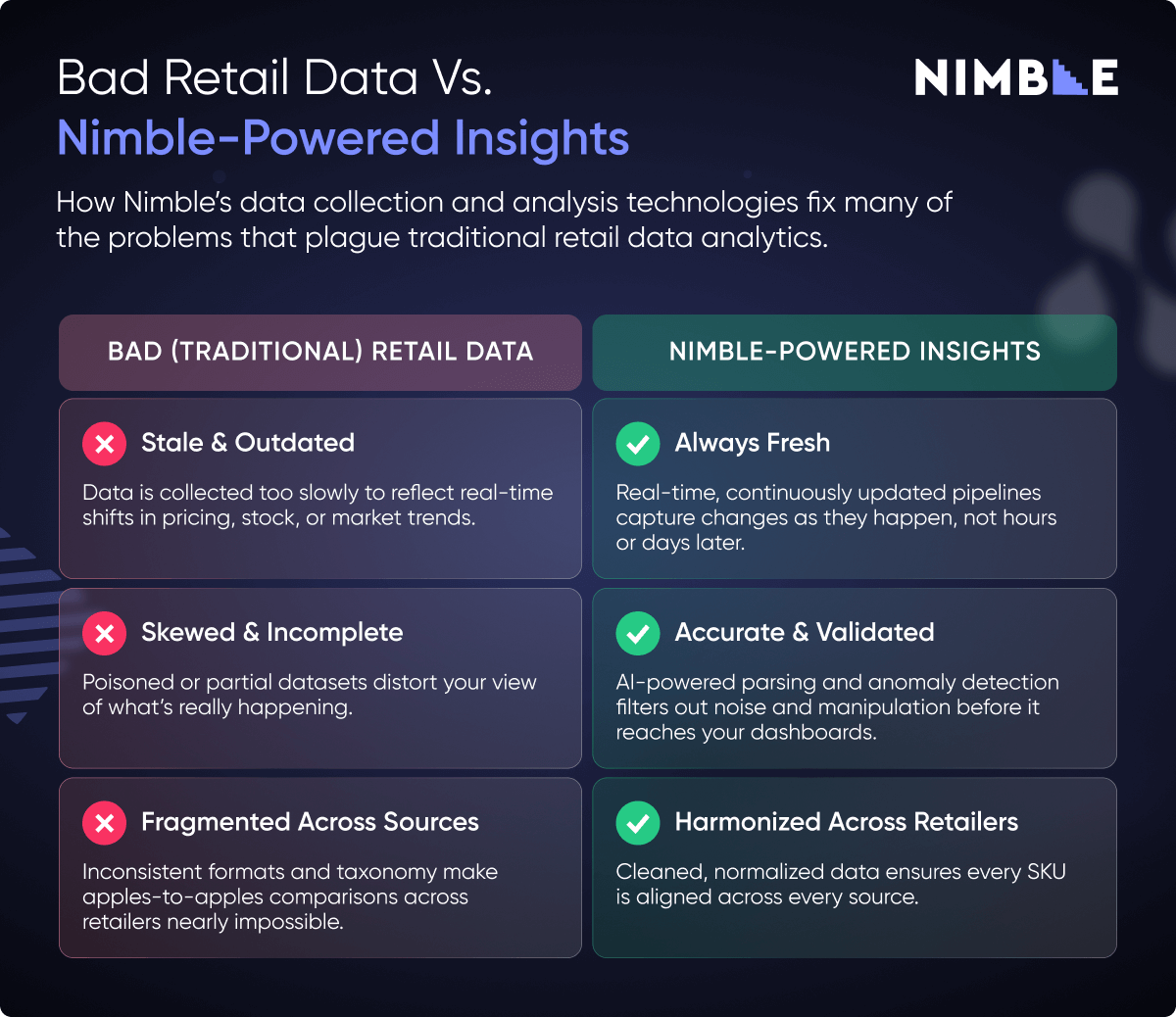
However, getting clean, accurate, and actionable retail data is becoming more difficult than ever. Sites are increasingly fighting back against e-commerce data scraping with IP blocks, honeypots, and other robust anti-scraping measures. This causes delays, inaccuracies, and data fragmentation, as well as a more sinister problem: data that looks clean but is secretly flawed.
So, how can analysts overcome these challenges and ensure important strategies and automations are fueled by real, accurate, and timely data? Keep reading to find out.
Key Takeaways
- Scraped e-commerce data is often unknowingly compromised by intentional sabotage (honeypots, rate limiting, throttling) and the complexity of modern sites.
- Old, brittle scraping tools aren’t equipped to handle the changing layouts, dynamic content, AI personalization, and anti-scraping measures of modern sites.
- Dirty, compromised data can have devastating effects on marketing, pricing, stocking, and forecasting strategies.
- To ensure data integrity, brand analysts must utilize adaptive scraping techniques, intelligent anomaly detection, real-time feedback loops, and harmonization.
How Retailers Are Actively Disrupting Data Collection
In a quest to prevent competitors from taking valuable data, brand websites and e-commerce platforms like Amazon are doing everything they can to sabotage e-commerce data scraping.
Honeypots, Throttling, and Anti-Bot Warfare
Retailers now deploy full-blown anti-bot arsenals to manipulate and block automated scrapers. Common tactics include:
- Honeypots: Fake products, prices, customer reviews, and other types of retail competitive intelligence that are intentionally planted to contaminate scraped data.
- Rate Limiting: Caps the number of requests you can make in a set time, causing gaps or partial data collection when scrapers exceed the threshold.
- Bandwidth Throttling: Slows down data transmission for suspected bots, making large-scale scraping operations inefficient or infeasible.
- Browser Fingerprinting: Uses subtle variations in browser behavior and configuration to identify and block automated agents masquerading as real users.
This means a scraper targeting an e-commerce site may see different—or completely fabricated—prices or listings depending on location, browser configuration, or IP reputation.
Dynamic SERPs and PDPs Are Sabotaging Data Consistency
AI-driven personalization is transforming both search engine result pages (SERPs) and product display pages (PDPs). Carousels with user-generated content, A/B-tested modules, and geotargeted offers now vary session to session, while dynamic JavaScript content may require page interactions to access specific data.
These dynamic elements break legacy scrapers that depend on fixed page structures and simple layouts, causing scraped data to be fragmented. Key promotional banners or product variants may be missed.
Newer e-commerce data scraping technology must adapt to variable page layouts and data structures, render JavaScript, automate page interactions, and run requests from multiple geolocations.
Why This Distorts Your Retail Intelligence
E-commerce data scraping tools that aren’t adaptive to the new reality of retail data scraping feed you poisoned or partial data, leading to unreliable analytics.
Brand analysts end up modeling decisions from inconsistent pricing, mismatched SKUs, or artificially inflated review counts—ultimately delivering reports that can’t be trusted.
The Impact: From Inconsistent Insights to Misleading Reports
The Illusion of “Clean” Data
One of the most dangerous traps in retail data analytics is the illusion of accuracy. Just because your scraper logs a “200 OK” status code doesn’t mean the payload is real or trustworthy.
Tools may accidentally capture dirty data like placeholder content, localized pricing distortions, or incomplete inventory due to geo-fencing. Fake data created to mislead scrapers, such as fictional prices, products, and pages, also frequently make their way into “clean” data sets.
Many of these issues go unnoticed. Scrapers continue pulling data, dashboards keep updating, and the flawed data flows straight into performance models and analytics dashboards.
The Heavy Costs of Dirty Data
Flawed data isn’t just an inconvenience—it’s a liability that causes massive, far-reaching problems. Some of the most common downstream failures from poor retail scraping include:
- Miscalculated Competitive Pricing Strategies: Brands may think they’re undercutting a rival when they’re actually priced higher, thanks to honeypots or localized pricing errors.
- Incorrect Out-of-Stock Forecasting: False zero-inventory signals from throttled scrapers can cause premature replenishment or missed replenishment cycles.
- Category Misreads: Analysts may believe a certain product tier is trending when it’s actually the result of inconsistent data structures or third-party seller listings.
These inaccuracies can then bleed into core business functions, contaminating the success of essential strategies:
- Marketing suffers from poorly targeted campaigns built on faulty assumptions about demand or price competitiveness.
- Trade spend is wasted trying to win placements that aren’t actually under threat.
- Forecasting models become inaccurate when based on unreliable product movement signals.
- Retail competitive intelligence becomes misleading because competitor actions and market dynamics are misrepresented.
- And most dangerously: brand managers make high-level strategic decisions based on poisoned data, believing they have an accurate picture when they don’t.
The 5 Biggest Challenges Brand Analysts Face From Retailer Data Blockages
Brand analysts must be ready to defend themselves against increasingly stealthy and sophisticated anti-bot tactics that distort insights before they even reach the dashboard. Here are the five most critical challenges.
1. Data Accuracy
Retailers deploy honeypots, fake pricing, and hidden inventory to confuse data collection bots. And, even when not intentionally deceptive, AI-powered personalization, dynamic pricing, and geolocation-based sales tactics make scraping unreliable. A product’s title, price, and reviews may look entirely different for a scraper vs. a real customer, even though it’s from the same URL.
This results in poisoned inputs: false trends, bad availability signals, and inaccurate brand sentiment data. To fight back, analysts need advanced anomaly detection tools that can flag unexpected changes before they skew strategic models.
2. Data Frequency Gaps and Fragmentation
Throttling, CAPTCHAs, and IP bans limit how often data can be collected. When scrapers are blocked or forced to run infrequently, brand analysts miss fast-moving changes like flash sales, promo launches, or sudden inventory shifts. This results in blind spots that kill timely insights.
To get around this, many brands blend real-time APIs, alternate data sources (e.g., from marketplaces), and crowd-sourced signals to maintain full visibility and reduce lag. However, this often leads to a confusing, over-complicated data stack, making real-time insight extraction difficult.
Want to simplify your data stack without sacrificing data quality? Learn about Nimble for Retail.
3. Data Harmonization
Retailers don’t all speak the same language.
One store might list a product as a “combo pack,” another as a “2-piece value bundle.” SKUs vary slightly, other code systems can accidentally get mixed in (like Amazon’s ASIN or UPCs), product names differ, and category tags are inconsistent. And of course, different geographies have different currencies, languages, formatting standards, and store layouts.
This makes it incredibly difficult to scrape e-commerce data to make direct comparisons and competitive benchmarking across multiple sources. Even with manual cleaning, mismatches slip through—especially with seasonal items or third-party sellers. AI-powered enrichment, fuzzy matching, and SKU normalization tools are now essential to bring fragmented listings into a unified view.
4. Data Integrity
Broken scripts, hidden site changes, and layout updates often go unnoticed. Silent failures—like a missing price module or a change in the review schema—can poison data pipelines over time.
Without timestamp validation and structural integrity checks, these issues remain undetected until a major reporting error occurs. Brand analysts must ensure continuous monitoring and rapid recovery mechanisms to preserve data integrity and ensure reliable insights.
5. Legal and Ethical Constraints
Some brands still rely on brute-force scraping, by rapid-firing requests, ignoring robots.txt files, and shuffling through hundreds of IPs.
While this may have worked in the past, this approach is becoming riskier. Legal threats, IP bans, and reputational harm can result from scraping protected content or violating terms of service.
Analysts are increasingly being asked to find “cleaner” ways to collect data—without sacrificing depth or accuracy.
The Fix: AI, Ethical Alternatives, and Adaptive Scraping
To overcome these barriers, forward-thinking brands are shifting toward smarter, more resilient data collection strategies by implementing the following tactics.
Agentic Web Search That Adapts to Evolving Layouts
Modern scraping tools now use web search and parsing agents that mimic real user behavior and automatically detect where the relevant information is on each site.
These systems can dynamically adapt to shifting site layouts, render JavaScript-heavy content, and navigate personalization layers without manual intervention. This makes them more reliable in the face of constant retailer updates.
AI-Powered Anomaly Detection and Data Validation
Machine learning models now monitor scraping outputs for unusual behavior, like overnight price drops, stockouts, or changes in sentiment density. These tools flag anomalies before the data reaches production dashboards. Some systems even predict when layout changes are likely to occur, helping analysts stay one step ahead.
Real-Time Feedback Loops
Retail scraping is too complex to “set it and forget it”, but it’s also too vast to manage manually. The solution is to employ automated real-time diagnostics to monitor data pipeline health, alert teams to broken selectors or slowdowns, and help identify data erosion before it becomes a systemic issue.
Ethical Scraping Over Brute Force Tactics
More e-commerce data scraping platforms now leverage advanced ethical solutions like verified residential IPs, compliant practices, and non-CAPTCHA triggering automations. These methods reduce legal risk and blocks, while improving data quality.
Harmonization Via Single-Source Data Pipelines
Instead of cleaning messy data after collection, leading teams are integrating structured, normalized data upstream.
Unified data pipelines that combine multiple data streams from various sources—like Nimble’s Online Pipelines—deliver harmonized SKUs, consistent attributes, and clean taxonomies out of the box. This eliminates hours of manual cleanup and makes cross-retailer benchmarking accurate and scalable.
Real-World Tactics to Stay Ahead of Retailer Interference
Use Case: Building a Retail Competitive Intelligence Dashboard
To make sense of fragmented, noisy data, analysts need centralized visibility. A retail competitive intelligence dashboard can aggregate datasets from multiple retailers and normalize shared taxonomy and SKU structure.
This allows retailers to visualize real-time shifts across the competitive landscape, like:
- Price fluctuations at the SKU and category level.
- Sudden inventory drops or restocks across regions.
- New product launches and promotional timing from competitors.
With real-time views and historical comparisons, analysts can instantly spot undercutting behavior, campaign overlaps, and seasonal pricing tactics to make faster, data-backed decisions.
Tactic: Validating Data with Shopper Sentiment
Even with harmonized pricing and inventory data, context matters. Was that price drop a strategic move, or a signal that inventory is being cleared?
To answer that, an analyst may pull user-generated content (UGC), review data, and social media sentiment to conduct brand sentiment analysis. By correlating shifts in pricing or stock status with customer reviews and social chatter, you can get a clearer picture of how and why pricing or inventory changes.
Tactic: SERP Monitoring for Competitive Landscape Shifts
SERPs are an extension of the digital shelf. They’re where customers gain exposure to your brand and ultimately make a purchase decision. This is especially true for SERPs within e-commerce platforms like Amazon.
SERP monitoring at the category and brand level helps detect:
- Changes in ranking logic (e.g., personalization tests, new sorting algorithms).
- Emerging ad formats or new sponsored placements.
- Feature prioritization (videos, bundles, reviews).
By ensuring your e-commerce data scraping strategy tracks SERP changes, you can keep tabs on how real shoppers experience your category.
How Nimble Enables Clean, Compliant, and Actionable Insights
Nimble’s Online Pipelines were built with today’s retail landscape in mind.
With an AI-powered, fully-managed infrastructure that can adapt to changing sites and dodge common blocks, Nimble delivers real-time, harmonized, accurate, and anomaly-resistant e-commerce data to brand analysts without engineering bottlenecks.
Zero Engineering Lift
Nimble automates adaptive scraping, enrichment, and data validation with a no-code interface. Analysts get trusted data without relying on manual collection and analysis or time-consuming debugging.
Fast Time-to-Value
With a simple onboarding, user-friendly platform, and real-time data collection and analysis, you can get insights on your data as soon as it's collected—not weeks later.
Nimble’s Online Pipelines for Retail and CPG are built to provide retail competitive intelligence on valuable pricing, brand sentiment, and category assortment across major e-commerce platforms. Plug in and begin getting insights immediately.
Flexibility Across Retailers
Whether it’s localized pricing, mobile-first layouts, or category-specific SKUs, Nimble handles nuance and specific customer needs. Data is harmonized into a single structure, ready for modeling, visualization, or direct activation in pricing and media platforms.
Final Thoughts: Don’t Let Bad Data Cost You the Quarter
Retailer data manipulation is only getting smarter. If you’re still relying on brittle scraping tools or incomplete datasets, you’re building strategies that are destined to fail.
It’s essential to understand that the biggest winners in the space today aren’t just collecting more data—they’re collecting better data. Clean, compliant, harmonized datasets make the difference between reacting late and acting first.
FAQ
Answers to frequently asked questions


.avif)


.png)

.png)
.avif)